Reconnaissance de Mots Isolés par modélisation markovienne de sous-dictionnaires
Bruno JACOB , Régine ANDRE-OBRECHT
I.R.I.T., URA 1399 CNRS
UPS , 118 route de Narbonne, 31062 Toulouse Cedex
Tél. : 61 55 60 55 Fax : 61 55 62 58
Abstract :
This paper describes a new strategy for very large vocabulary speech recognition. The main problem is to reduce the lexical access without pruning the correct candidate. We propose to exploit the branching structure of BDLEX lexicon and the description of each word into root and flexional ending. More we use the notion of phonetic classes to decompose the dictionnary into sub-dictionnaries. We develop a two-stage recognition algorithm :
-- Each dictionnary which is considered as a sequence of phonetics classes is modeled by a HMM where the elementaries units are these phonetics classes.
-- Each word is modeled by a classical HMM where the elementary unit is the pseudo-diphone.
For an unknown word utterance, a first recognition gives the best dictionnary to which it belongs, the Viterbi algorithm applied to the network of the best dictionnary words, gives the word with the most likelihood.
Experiments are carried out with telephonic database.
Keywords : Sub-dictionnaries, Phonetics Classes, HMM / Viterbi.
Résumé :
Cet article présente un nouveau mode de sélection de sous-dictionnaire pour la reconnaissance de la parole dans le cadre de très grands vocabulaires. Le but recherché est de réduire l'accès lexical sans pour autant rejeter la bonne solution. Nous exploitons la structure arborescente du lexique de BDLEX, la description de chaque mots en racine et désinence, ainsi que la notion de classe majeure pour décomposer le lexique en sous-dictionnaires. Nous avons développé un algorithme de reconnaissance en deux passes :
-- Chaque dictionnaire est modélisé par un MMC dont les éléments sont des classes majeures.
-- Pour une séquence de classes majeures trouvée dans ce premier MMC, sont modélisés tous les mots lui correspondant par un MMC classique dont l'unité est le pseudo-diphone.
Pour un mot inconnu, la première phase donne le meilleur sous-dictionnaire qui pourrait le contenir et l'algorithme de Viterbi appliqué à celui-ci propose le mot ayant le meilleur score de vraisemblance.
Des expérimentations sont en cours avec une base de données dont les mots ont été prononcés à travers le réseau téléphonique.
Mots Clés : Sous-dictionnaire, Classes Majeures, MMC / Viterbi.
1. INTRODUCTION.
L'accès lexical, dans les systèmes de RAP, dans le cadre de très grands vocabulaires, est un problème difficile. Lorsque la taille du vocabulaire augmente ( > 1000 mots ), il devient indispensable d'optimiser cet accès. Plusieurs tendances sont actuellement observées ; le lexique peut être organisé sous forme arborescente [1] ou sous forme de tables de règles de grammaire [2] afin de réduire l'espace de recherche. Une autre approche consiste à déterminer un sous-dictionnaire par déduction progressive du vocabulaire à l'aide de filtres lexicaux ( module d'accès lexical MALLIA [10] ).
Nous nous intéressons à une nouvelle approche basée sur la recherche probabiliste de sous-dictionnaires. Nous proposons de structurer le lexique sous forme d'arbres modélisés par des MMC: le vocabulaire de base est considéré comme une réunion de sous-dictionnaires, chacun étant modélisé par un sous-modèle de Markov ; chaque sous-dictionnaire est lui-même un ensemble de mots et chaque mot correspond à un modèle de Markov caché. Les modèles de Markov cachés sont construits de manière hiérarchique à partir d'unités de base : pour la modélisation des dictionnaires, est introduite la notion de classes majeures et pour celle des mots, la notion de pseudo-diphones. Cette décomposition est complétée par l'utilisation de gpm ( groupes à prononciations multiples ). Intuitivement cette décomposition correspond à la représentation des mots en classes phonétiques puis en phonèmes.
Nous l'appliquons, dans un premier temps, à la reconnaissance de mots isolés.
La mise en oeuvre de cette stratégie n'a pu être faite sans un lexique clairement étudié et structuré, et sans un outil informatique puissant permettant la création de MMC , et leur compilation éventuelle à l'aide de règles phonologiques. C'est pourquoi nous consacrons deux paragraphes à la description de ces outils, avant de détailler le système de reconnaissance proprement dit et les premières expérimentations.
2. Le lexique.
Le lexique de base utilisé est extrait du lexique de BDLEX version 2 qui contient 50.000 entrées lexicales, chacune d'elles étant accompagnée d'une description linguistique centrée sur les niveaux morpho-syntaxique et phonologique du français [3].
A partir du lexique BDLEX-2 et en utilisant un ensemble de règles flexionnelles, on obtient un corpus de 437.000 formes fléchies. Ces règles sont basées sur l'association racine/désinence où la racine est la partie caractéristique du mot et la désinence celle qui porte les marques flexionnelles ( pluriel, féminin, temps, personne, mode ) [4].
La représentation phonologique de chaque forme fléchie est produite de manière à rendre compte des variantes de prononciation. Pour cela, la représentation phonologique est décrite à l'aide de groupes à prononciations multiples ( gpm ) et des groupes phonologiques contextuels ( gpc ) [8]. "Les gpm rendent comptent de toutes les variantes possibles de prononciation d'un ou de plusieurs phonèmes contigus pour un groupe de locuteurs donné. Ils permettent de traduire des phénomènes phonologiques comme la chute du schwa ou les assimilations. Les gpc rendent comptent des variantes de prononciation dues au contexte du mot dans la phrase"[8].
Dans le cadre de notre application nous nous intéressons uniquement aux mots isolés, aussi le gpc d'une forme phonologique finale est traduit, en contexte "fin de phrase", dans le gpm correspondant à l'aide d'un ensemble de règles par la composante phonologique de BDLEX [8].
Pour minimiser le problème d'accès posé par la reconnaissance grands vocabulaires, ce corpus est structuré de manière arborescente. L'arborescence principale regroupe toutes les racines présentes dans ce corpus; elle est liée aux sous arbres des désinences.Cette organisation s'inspire de celle utilisée pour le lexique de BDLEX dans le cadre de l'application VORTEX ( Correcteur Lexical ) [11]. Pour optimiser le traitement et réduire la taille des graphes, nous prenons en compte la représentation phonologique en classes majeures des racines et des désinences. Une classe majeure regroupe les phonèmes qui ont un comportement acoustique proche (tableau 1). Les formes qui ont la même représentation phonologique en classes majeures sont factorisées, les branches de l'arbre correspondant sont regroupées en une seule ; finalement une branche de l'arbre des racines reliée à une branche d'un des arbres de désinence, dans le cas où cette liaison est possible, permet de définir un sous-dictionnaire.
A a plosive D b, d, g
voisée
E [[epsilon]], T p ,t ,k
e
e oe , (TM) plosives TR tr
voyelles I i TL pl
O o fricatives S f , s ,
[[integral]]
U u Z v , Z , Ô
Y y liquides R r
voyelles % ã ,õ L l
nasales IN É silences $
nasale N m , n, #
[[eta]]
semi-voyelle J j
Tableau 1 : description des Classes Majeures .
3. Le générateur de réseaux.
La plupart des applications en reconnaissance de la parole utilisent des modèles de Markov cachés (MMC), construits de manière hiérarchique à partir de réseaux élémentaires. De nombreux outils sont actuellement disponibles tels que le compilateur PHIL 90 [5], le logiciel HTK [6]. Malheureusement ils sont inadaptés à la création et à la gestion de graphes et arbres, tels que ceux présentés au paragraphe précédent.
L'outil que nous développons, est un compilateur de réseaux ; à partir de réseaux élémentaires de type MMC et d'instructions de base, un réseau hiérarchique structuré en niveaux est obtenu :
- le niveau le plus bas représente le réseau actif ; les transitions et états de ce niveau sont dits actifs, en particulier les transitions porteuses des lois d'observations.
- les niveaux supérieurs représentent les étapes successives de la construction du réseau actif.
Dans l'ensemble des instructions de compilation, on peut distinguer trois grandes familles de rubriques :
- la première famille consiste à caractériser un réseau simple d'un seul niveau en décrivant ses états initiaux et finaux, et ses transitions. Le nom d'un état est formé d'une racine et d'une extension et on peut définir des classes d'états en les repérant par la même racine. Les transitions peuvent supporter des lois discrètes ou continues. Elles peuvent être éventuellement vides, c'est à dire ne supportant aucune loi. A chaque transition correspond un chaînage arrière. On peut ainsi connaître à tout instant les prédécesseurs d'un état dans le graphe et, bien entendu, ses suivants.
- la deuxième famille d'instructions est utilisée pour "imbriquer" des réseaux. Ceci consiste à relier des transitions appartenant à un réseau global à des sous-réseaux. Cette nouvelle liaison peut être obligatoire ("Clusters"), c'est à dire détruire la transition initiale, ou facultative ("Coarticulation"), et dans ce cas la transition initiale est doublée. On peut en outre relier une classe d'états par un sous-réseau ("Lien"). Les sous-réseaux peuvent être locaux, c'est à dire décrits en même temps que le réseau global dans le fichier texte, ou bien être déjà créés en mémoire.
Il s'établit entre l'état instancié, dans le cas de "Liens", -- ou l'état de départ de la transition instanciée, dans le cas des "Clusters" et "Coarticulations" -- et le sous-réseau qui le remplace, un lien de parenté du type père/fils : tous les états appartenant au sous-réseau verront la racine de leur arbre généalogique augmenté d'un ancêtre ; réciproquement l'état substitué reconnaîtra comme ses fils les plus lointains ancêtres de l'ensemble des états du sous-réseau.
L'état qui a été instancié, ainsi que les flots entrant et sortant de ses transitions, sont rendus inactifs. Les états inactifs sont les ancêtres des états du réseau actifs et sont liés entre eux par des relations inactives. Chaque génération d'états forme ainsi un niveau du réseau global. Il est possible de connaître à tout instant dans le parcours d'un tel graphe les ancêtres et les descendants d'un état.
- les lois de probabilité du réseau global sont créées avec des valeurs données par défaut. La troisième famille de rubriques permet de modifier ces valeurs en les initialisant par les données de l'utilisateur. Il est possible d'initialiser soit la totalité des lois du réseau, soit seulement celles relatives à des transitions dont les états appartiennent à une classe d'ancêtres.
Une fois les instructions compilées et le réseau final obtenu, celui-ci est optimisé en supprimant en particulier les transitions vides. Les algorithmes d'apprentissage et de reconnaissance à l'aide d'un tel réseau, basés sur l'algorithme de Viterbi, sont adaptés à cette structure de données.
4.Le système de reconnaissance.
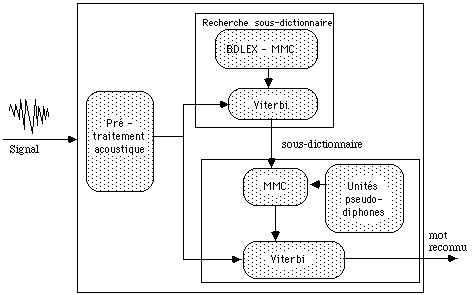
Le système de reconnaissance automatique de mots isolés que nous abordons se décompose en trois modules principaux qui sont :
- le pré-traitement acoustique,
- la recherche du meilleur sous-dictionnaire,
- la recherche d'un mot le plus probable.
Figure 2 : Décomposition du système de reconnaissance basée sur la modélisation en sous-dictionnaire
4.1 Le pré-traitement acoustique :
Ce pré-traitement s'effectue en deux phases :
- un algorithme de segmentation statistique, l'algorithme de divergence "forward-backward"[7], est appliqué au signal de parole et permet d'obtenir une suite de segments de taille variable correspondant dans une première approximation aux zones stables et transitoires du continuum de parole.
- sur chaque segment est ensuite effectuée une analyse spectrale. Sont ainsi extraits huit coefficients cepstraux, l'énergie, les dérivées premières et secondes de ces paramètres ; leur est adjoint la durée du segment en centisecondes pour former un vecteur d'observation.
4.2 La recherche de sous-dictionnaires :
A partir de l'écriture en classes majeures des formes extraites du lexique BDLEX, le compilateur décrit ci-dessus permet d'obtenir un réseau arborescent pour représenter l'ensemble des racines et des réseaux pour ceux des désinences, puis d'effectuer les transitions entre eux. Les règles phonétiques, qui associent à un gpm ses réalisations phonétiques munies de probabilités [8], sont interprétées à l'aide des instructions Cluster et Coarticulations. L'ensemble constitue la modélisation probabiliste du lexique de BDLEX, dans laquelle l'unité de base est la classe majeure ; les lois d'observation sont gaussiennes, les matrices de covariance sont diagonales.
L'algorithme de Viterbi permet d'aligner la suite d'observations acoustiques du mot à reconnaître sur un des chemins actifs du réseau et de fournir la meilleure suite de classes majeures qui correspond, a fortiori, à un sous-dictionnaire.
4.3 La recherche du mot.
La suite de classes majeures reconnue est équivalente à un sous-dictionnaire de mots. Le compilateur de réseaux fournit pour chaque mot un modèle de Markov caché, dans lequel l'unité de base est le pseudo-diphone ( parties stables des sons, transitions entre les sons...) ; les règles phonologiques permettent d'accéder aux différentes prononciations. Les lois d'observations sont gaussiennes de matrice de covariance diagonale. L'algorithme de Viterbi, appliqué à l'ensemble des MMC de mots en pseudo-diphones et à la même suite d'observations que précédemment, fournit le mot reconnu.
5. Expériences et conclusion.
Dans la mesure où il s'agit d'une étude préliminaire, il n'était pas envisageable, au cours des premières expériences, de modéliser et surtout d'apprendre tous les réseaux liés à BDLEX. De plus, nous voulions nous assurer que le processus de reconnaissance en deux étapes ne dégradait pas trop les performances du système de reconnaissance par rapport à une approche plus classique.
Afin de montrer la faisabilité de cette approche, nous nous limitons à la reconnaissance de mots isolés. Nous nous sommes restreints à la création d'une arborescence représentant entièrement les mots, sans faire appel à la notion de désinence. Les premiers résultats sont obtenus sur un vocabulaire de 50 mots tirés de manière aléatoire parmi les 500 mots les plus courants du français ; il en résulte qu'il s'agit essentiellement de mots monosyllabiques et bisyllabiques. Les enregistrements ont été faits par le CNET à travers le réseau téléphonique, la bande passante est donc réduite à 3,3kHz. Cette expérience est multi-locuteurs dans le sens où l'apprentissage est effectué à partir de deux prononciations de chaque mot par dix locuteurs et que les tests sont faits sur une troisième répétition de chaque mot prononcé par chacun des dix locuteurs. Le taux de reconnaissance en termes de sous-dictionnaires correctement sélectionnés est de 90%, en ne prenant en compte que huit coefficients cepstraux par vecteur d'observation. Il est à noter que dans le cadre de cette expérience, un sous-dictionnaire ne contient que rarement plus d'un mot.
Nous avons comparé cette approche à l'approche classique où chaque mot est directement modélisé par un MMC ; l'unité de base est le pseudo-diphone, le traitement acoustique est identique. Un exemple de comparaison est donné par la figure 3. Le taux de reconnaissance est de 94%. La dégradation que nous observons est essentiellement due au manque de précautions prises lors de la modélisation des classes majeures. Nous allons poursuivre cette recherche en améliorant les modèles de Markov cachés élémentaires et en l'expérimentant sur un ensemble de 500 mots. Alors seulement nous pourrons en tirer une réelle conclusion.
Figure 3 : Résultats des étapes de reconnaissance sur le mot "n'est-ce pas"
(a) sous forme de classes majeures
(b) sous forme de pseudo-diphones
REFERENCES
1] V. Steinbiss, H. Ney, R. Haeb-Umbach, B.-H. Tran, U. Essen, R. Kneser, M. Oerder, H.-G. Meier, X. Aubert, C. Dugast, D. Geller, " The Philips Research System for large vocabulary continuous speech recognition", Eurospeech, Berlin 1993, pp 2125-2128.
[2] Y. Minami, K Shikano, T. Yamada, T. Matsuoka, "Very large vocabulary continuous speech recognition algorithm for telephone directory assistance", Eurospeech , Berlin 1993, pp 2129-2132.
[[3] G. Pérennou , " Le projet BDLEX de bases de données et de connaissances lexicales et phonologiques", 1ères Journées du GRECO-PRC Communication Homme-Machine, EC2 Editeur, Paris 1988, pp 81-111.
[4] I. Ferrané , " Base de données et de connaissances lexicales morphosyntaxiques", Thèse de l'Université Paul Sabatier, Septembre 1991.
[5] D. Jouvet, J. Monné, D. Dubois, A new network based speaker independent connected word recognition system. ICASSP, Tokyo 1986.
[6] S.J. Young "HTK Hidden Markov Model Toolkit" Rapport Cambridge University Engineering Department -- Speech Group -- September 92 .
[7] R. André-Obrecht, " A new statistical approach for the automatic segmentation of continous speech signals. IEEE Trans. on ASSP, vol. 36, ndeg.1, January 1988.
[8] A. de Ginestel-Mailland, M. de Calmès, G. Pérennou, "Multi Level Transcription of Speech Corpus from Orthographic Form", Eurospeech, Berlin 93.
[9] R. André-Obrecht , "Segmentation et parole ?", Habilitation Directeur de Recherche, Université de Rennes I, Juin 93.
[10] F. Béchet , "Système de Traitement de Connaissances Phonétiques et Lexicales : Application à la reconnaissance de mots isolés sur de grands vocabulaires et à la recherche de mots cibles dans un discours continu", Thèse de l'Université d'Avignon , Janvier 94.
[11] J-M Pécatte, "Tolérance aux fautes dans les interfaces Homme-Machine, Traitement des chaînes phonétiques, des chaînes orthographiques et des structures syntaxiques", Thèse de l'Université P. Sabatier, Toulouse III, Janvier 92.