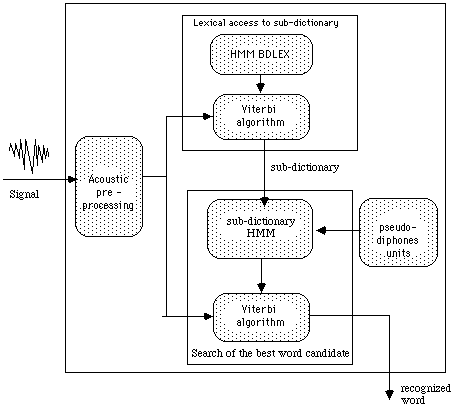
 Figure
1 : Structure of the speech recognition system
Figure
1 : Structure of the speech recognition system Abstract
A lexical access using a two-stage algorithm based on the description of the lexicon into two types of units is proposed. To access to a sub-dictionnary, phonetic classes are used to build an HMM. Then this sub-dictionary is modeled by a temporary HMM, with pseudo-diphones units, to produce the recognized word.
An acoustic pre-processing adapted to the pseudo-diphone decomposition and an adequate"HMM Compiler" toolkit are used in this application.
Experiments are made to evaluate this approach with the 500 most frequents words in french language.
I. Introduction
The main problem in large vocabulary continuous speech recognition systems is to reduce the search space without pruning the correct candidate and to perform a rapid search algorithm. Several approaches have been proposed, most of them are based on lexical tree organisation and forward-backward algorithms [1], [2], [3].
We propose a new lexical access strategy for speaker independent isolated word recognition and large vocabulary. We use a two stage decoding algorithm based on the description of the lexicon into two types of units and HMM :
- broad phonetic classes are defined to model the global dictionary as an union of sub-dictionaries. During a first recognition, only a sub dictionary is so exhibated
- pseudo diphone units are the intermediate units of a finer HMM, built on line after each recognized sub dictionary. An ultimate search in this graph gives the word candidate.
Our paper is organized as follows : in section 2, we describe our recognition system. In section 3, we give details about the tools we use to implement our system, the BDLEX lexicon, its organisation and our adequate HMM compiler. Section 4 is devoted to a first experiment and some preliminary results are given.
II The two pass recognition system.
As shown in Figure 1, the present system consists classically on two main modules, the acoustic processing and the linguistic decoder The originality of our work lies upon two points :
- the acoustic parameters are performed after an a priori signal segmentation, each observation vector corresponds to an analysis of a variable length segment ;
- the linguistic decoder is composed of a broad rooted HMM which is made with phonetic classes units.and of a temporary HMM composed of pseudo-diphone units.
Figure
1 : Structure of the speech recognition system
II 1 ) The acoustic pre-processing :
An automatic statistical segmentation is performed without a priori knowledge by the Forward-Backward divergence method [4]. This one produces segments which can be classified into two main categories :
* stationary segments which correspond to the steady part of a phoneme ( when it exists )
* transient segments which correspond to the transitions between two phonemes.
A cepstral analysis is computed on each segment to give one observation vector composed of the energy, 8 MFCC, their derivatives. As the segment length is variable, we add this quantity as a last coordinate. Finally we dispose of 19 parameters.
II 2 ) Lexical access to the sub-dictionary :
A phonetic class regroups phones which have nearly acoustic behaviour. So, a sequence of phonetic classes correspond to several words.
A a voiced D b, d, g
plosive
E [[epsilon]], T p ,t ,k
e
e oe , (TM) plosives TR tr
Vowels I i TL pl
O o fricatives S f , s ,
[[integral]]
U u Z v , Z , Ô
Y y liquids R r
nasal % ã ,õ L l
vowels IN É silences $
nasal N m , n, #
[[eta]]
semi-vowels J j
Figure
3 : table of phonetic classes description
With the various prononciations and the transcription into phonetic classes of the BDLEX lexicon, the "HMM Compiler" permit us to build a broad HMM.
This rooted HMM is organised into three principal state-levels :
* The word level : each state of this level refers to a graph word.
* The phonetic level : each state refers to the name of a phonetic class. The probabilist transitions model the phonetic class decomposition of the states of the word level.
A link of "relationship" type is made between each state of the word-level and the set of the states which describes phonetic class decomposition of this word.
* The acoustic level : this level contains the set of the elementary acoustic HMM of each phonetic class. The states of the phonetic level are connected to the states belonging to the HMM which models their acoustic decomposition.
To reduce the computational cost, the phonetic level is organized into a tree structure. In such a way a state of the phonetic level may have several fathers, each father refering to a word, and several sons in the acoustic level modeling this phonetic class.
The Viterbi algorithm suplies the best path composed of the acoustic level states. With the "relationship" link, we obtain the corresponding sequence of phonetic classes in the upper level. This sequence of words gives the recognized sub-dictionary. Finally, to each sequence of acoustic states corresponds the likely sub-dictionary.
II 3 ) Best word candidate :
The set of words found previously by Viterbi algorithm is modeled on line with the "HMM compiler" and gives a second HMM.
By a similar way this temporary HMM contains three principal levels :
* The word level : each state word refers to a graph word.
* The phonetic level : each word is described as a sequence of pseudo-diphones. The pseudo-diphones units distinguish the steady and transient parts of word phonemes.
The phonetic decomposition produced by this level is finest than the one produced by the HMM modelizing the sub-dictionnaries. This decomposition is more exactly adapted to the segmental pre-processing.
As in the previous HMM, the states of the word level are linked with the states of the phonetic level.
* The acoustic level : this level contains the set of the elementary acoustic HMM of each pseudo-diphone unit. The states of the pseudo-diphones level are connected to states belonging to the HMMs which model the acoustic decomposition.
Another application of the Viterbi algorithm gives the best path in the acoustic level. The fathers of the state sequence give the pseudo-diphones decomposition of the recognized word. The graph of this word is given by the upper generation of the states of the pseudo-diphone level.
III BDLEX lexicon and an appropriate HMM compiler.
III 1 ) The BDLEX lexicon :
We use a basic lexicon extracted from the BDLEX-2 lexicon which contains 50.000 lexical forms. Each form refers to a phonetic description ( API code ).
From the BDLEX-2 lexicon and using flexionnal rules , we obtain a corpus of 437.000 inflected forms. These rules are based on the adequation root/flexionnal ending. The root is the characteristic part of the word and flexionnal ending is the part which have the flexionnal marks ( plural, gender, tense, person, mood )
We propose to structure the lexicon with several networks : one network which contains root parts and as many as there are flexionnal endings.
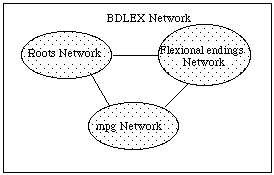 Figure
2 :Structure of the BDLEX Network
Figure
2 :Structure of the BDLEX Network
In order to take account of the possible pronunciation variants within the phonological representation of inflected forms, we introduce mpg's and the cpg's.
The mpg's account for all possible pronunciation variants of one or more contiguous phonemes put out by a group of speakers. They allow to translate phonological phenomena as the fall of schwa or the liaison ...
The cpg's account for the variants due to word context within the sentence. So, the contextual pronunciation variants are taking as early as lexical level into account [5].
As part of our application, we interest to isolated words. The cpg's are reduce to the context "ending sentence". The corresponding mpg's are translated in this context by the BDLEX phonologic component. Each mpg is modeled by a network.
For exemple, the word trente-quatre is represeneted by "trã(~t(TM)^)k(TM)<tr(TM)>" at the phonological level.
The mpg (~ta^) can be pronounced [t], [n], [ta], [toe] or [tø]
The cpg <tr(TM)> with the right context "Pause" gives the mpg (tra>). Its realization corresponds to the pronounciations [troe] , [trø] , [:], t^r... where '^'means unvoicing, and '>' means a strong boundary pause.
III 2 ) The HMM compiler
Many of the speech recognition systems are based on hierarchic building Hidden Markov Models ( HMM ) with elementary HMM. Current tools are availables : PHIL 90[6], HTK[7] Unfortunatly, they are unsuited to the production control of our HMM and tree structures.
Thus we are developed our HMM compiler; from the description of elementary HMM and basic instructions, the compiler builds a multi-level HMM.
The Viterbi algorithm is run with the states of the bottom level.This level is called "active".The others levels are the successive savings of the building steps.
The set of instructions contains three sections :
-- The first section identifies classical HMM.
A HMM may have two types of transitions :
* The "active transitions" are connected to a probabilist function and can be associated to a observation vector.
* The "empty transitions" dont't produce any observation. They are used to link the elementary HMM.
Each transition is associated to its backward transition. Thus, we can identify, for every state, its preceding and following states in the HMM.
A state name is composed of a root name and a extension name; the states which have the same root name make a state-class.
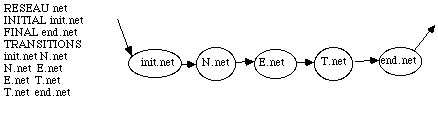 Figure
2 : Example of identification of a classical HMM
Figure
2 : Example of identification of a classical HMM
-- The second section contains instructions used to "overlap" the different HMM. This type of instructions links global HMM transitions with of a sub-HMM This new connection can be "obligatory" ( "Cluster" ) i.e. the initial transition is deleted, or "optional" ("Coarticulation") i.e. the global HMM transition is preserved and so, we have a double transition.
Furthermore, we can link a state-class with a sub-HMM ( "Link" ). These sub-HMMs can be describe in the same text file as the global HMM or create in main memory before.
A "relationship" is defined between the state ( case "Link" ) or the transition ( case "Cluster" or "Coarticulation" ) and the sub-HMM which replaces it. The root of the genealogic tree of sub-HMM states will be increased by a new ancestor, which is the replaced state. Reciprocally, we add to structure of son-states, the state-ancestors of the sub-HMM .
The replaced state and its transitions become unaffected to the "active level"; thus, they called "inactives". The inactives states are the ancestors of the states of the active level.They connect them by inactive transitions. Each states generation corresponds to a level in the HMM. Therefore, each state of the HMM is linked to its ancestors and its sons.
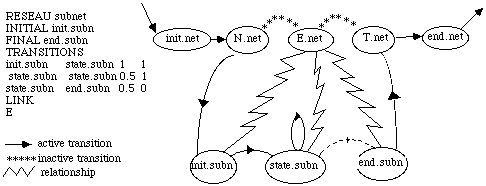 Figure
3 : Example of overlap of HMM.
Figure
3 : Example of overlap of HMM.
-- The HMM may have discrete or continuous probabilist laws. Default values are injected in these pdfs parameters. The third section gives to the user the possibility to modify these default values with his own initialisation values. The user can initialize the totality or a part of the parameters. This part is characterized by the functions which are connected to one state-class.
Once instructions compiled we obtain a final HMM. This one is optimized, in particular the useless "empty transitions" may be deleted. The training and recognition functions, based on the Viterbi algorithm, are adapted to this data structure.
IV Experiments :
As a feasible step in evaluating our approach, a realistic task has been chosen : we build an isolated word recognition system. The vocabulary is composed of the 500 most frequent words in french conversation, and the database is recorded through the telephonic channel. The system is multi-speaker in the sense that the learning set consists of two prononciations of each word by 10 speakers, and the test of another one pronounced by the same speakers.
A exemple of result of the two-stage strategy is given by the figure 4. It shows the sub-dictionnary result in the first pass with the phonetic classes and the recognized word which is the result of the second pass in pseudo-diphones units.
In spite of the adverse conditions ( sampling rate of 8 kHz, band pass of 3,3 kHz ), very good performances are obtained. The experiments show us that 14 phonetic classes are necessary to realize a good compromise between their reliability, and that the adequation pseudo-diphone HMM / segemental pre-processing is perfect. Currently, we extend our application to the BDLEX-2 lexicon [8].
Reference
[1] P. KENNY, P LABUTE, Z. LI, R. HOLLAN, M. LENNIG, D. OSHAUGHNESSY, "A New fast Match for Very Large Vocabulary Continuous Speech Recognition", Proceedings ICASSP 93.
[2] A. LJOLJE, M.D. RILEY, "Optimal Speech Recognition Using Phone Recognition and Lexical Access", Proceedings ICSLP 92.
[3] Y. MINANI, K. SHIKANO, T.YAMADA, T. MATSUOKA, "Very Large Vocabulary Continuous Speech Recognition Algorithm for Telephone Directory Assistance", EUROSPEECH 93., Vol 3, pp 2129-2132, September 93
[4] R. ANDRE-OBRECHT, "A New Statistical Approch for the Automatic Segmentation of Continuous Speech Signals", IEEE Trans on ASSP, January 1988.
[5] A de GINESTEL-MAILLAND, M.de CALMES, G. PERENNOU "Multi-Level Transcription of Speech Corpora From Orthographic Forms", EUROSPEECH 93
[6] D JOUVET, J. MONNE, D. DUBOIS, "A New Network Based Speaker Independent Connected Word Recognition System", ICASSP, Tokyo 1986
[7] S.J. YOUNG "HTK Hidden Markov Model Toolkit" Rapport Cambridge University Engineering Department -- Speech Group -- September 92.
[8] G.PERENNOU, "BDLEX : Lexical Data and Knowledge Base of Spoken and Writen French", Europeen Conference on Speech Technology, Edinburgh 1987.
Figure 4 : Results with the word "n'est-ce pas" (a) sub-dictionary (b) pseudo-diphone