Un modèle Maître-Esclave
pour la fusion des données acoustiques et articulatoires
en Reconnaissance Automatique de la Parole
Bruno Jacob, Christine Sénac
Institut de Recherche en Informatique de Toulouse CNRS UMR
5505
Université Paul Sabatier
118, Route de Narbonne, 31062 Toulouse Cédex
ABSTRACT
In the project AMIBE (Applications Multimodales pour Interfaces et
Bornes Evoluées), we study the natural visual and auditive bi-modality
of the speech communication. The automatic speech recognition is performed by
synchronizing the lip-reading and the acoustic pattern recognition based on
Hidden Markov Models (HMM).
To merge acoustic and labial observations, we propose two alternatives :
- a classical HMM where the acoustic observations and the labial ones are
assumed independent,
- a master-slave relation between two HMM, the articulatory HMM enslaves the
labial one.
Automatic recognition experiments are performed on connected digit and spelled
letter databases. We compare the two approaches and we show the lip-reading
interest.
Dans le cadre du projet Applications Multimodales pour Interfaces et
Bornes Evoluées (projet AMIBE soutenu par les PRC Informatique 1993 -
1995), est étudiée la bi-modalité naturelle auditive et
visuelle de la communication orale. La reconnaissance automatique de la parole
s'opère en synchronisant une "lecture labiale" avec un module de
reconnaissance des formes acoustiques, par Modèles de Markov
Cachés (MMC).
Pour fusionner les données acoustiques et articulatoires, plusieurs
alternatives se présentent. Les informations peuvent être
traitées sans discernement, par un MMC classique ; le vecteur
d'observations est la concaténation des deux familles de
paramètres labiaux et acoustiques ; ils sont considérés
comme indépendants et l'utilisation de pondérations permet de
réduire l'importance de l'une par rapport à l'autre (nous
parlerons, dans la suite de cet article d'approche globale et de MMC global).
Cette approche a été choisie par le LIUM avec un MMC dont les
coefficients labiaux et acoustiques sont pondérés en fonction du
bruit (Foucault, 95). Pour sa part, le LIA propose un nouveau MMC dont les
unités sont des mots, gérant le décalage de façon
interne grâce à un choix particulier de topologie
(Jourlin, 95). Une autre alternative consiste à modéliser
chaque famille de paramètres par un modèle de type MMC, et
corréler les deux modèles par une dépendance entre les
lois. Nous avons étudié plus particulièrement cette
approche appelée par la suite approche maître-esclave ; nous nous
sommes inspirés des travaux de Brugnara et De Mori qui ont
appliqué cette liaison maître-esclave pour traiter la durée
des sons (Brugnara, 92).
Au cours de cette présentation, le principe de l'approche
maître-esclave est rappelé brièvement, et nous
définissons un MMC équivalent moyennant certaines
hypothèses simplificatrices appropriées à la
reconnaissance de paramètres acoustiques et labiaux. Des
résultats expérimentaux illustrent cette approche, dans les cas
de la reconnaissance de suites de chiffres et lettres épelées.
Une comparaison entre approche globale et approche maître-esclave est
proposée.
Le principe des modèles dits "maître-esclave" repose sur la
modélisation d'une application non plus par un MMC unique, mais par deux
MMC mis en parallèle et corrélés. L'idée
générale est de parvenir à une adaptation dynamique des
lois de probabilités d'un des modèles de Markov cachés, en
fonction du contexte courant modélisé par l'autre MMC. Le
contexte est une notion qui doit être prise au sens large, il peut s'agir
d'un indice de voisement, de nasalisation,... d'un réel contexte
phonétique, d'un indice suprasegmental comme la durée des sons...
tandis que le MMC piloté est traditionnellement lié à des
paramètres acoustiques.
Un modèle maître-esclave se compose de deux modèles : un
modèle maître [[lambda]]' qui est un MMC classique et un
modèle [[lambda]]" qui est un MMC dont les paramètres
dépendent à tout instant de l'état dans lequel se
trouve le modèle maître.
Un modèle maître-esclave est équivalent
mathématiquement à un modèle classique de type MMC mais
l'inconvénient de ce modèle réside dans son important
nombre d'états et de lois. Ne pouvant raisonnablement implanter un tel
modèle, nous avons réalisé une représentation
simplifiée : nous réduisons le processus maître à un
modèle ergodique dont les probabilités de transitions entre
états ne sont pas réestimées.
Il s'en suit que nous pouvons créer un modèle simplifié
dont le nombre d'états est le nombre d'états du modèle
esclave, mais chaque transition du modèle esclave est dupliquée
par le nombre d'états du modèle maître et chaque nouvelle
transition est indexée par un état maître (Jacob, 95).
Dans le cadre du projet AMIBE, nous disposons de deux types de
signaux : le signal acoustique et le signal articulatoire
synchronisés. Le signal acoustique est échantillonné
à 16 kHz, tandis que pour le signal articulatoire ( issu d'un traitement
d'image (Lallouache, 91) ), nous disposons d'un vecteur d'observations toutes
les 20ms. Ce signal se compose de la largeur A ,de la hauteur B, et de la
surface S intérolabiale .
Le signal acoustique est segmenté automatiquement (André-Obrecht,
88) et une analyse spectrale est faite sur chaque segment : 8 coefficients
cepstraux (CC) sont obtenus après recalage du spectre selon
l'échelle Mel. Leur sont adjoints l'énergie (E) et la
dérivée de ces coefficients ([[Delta]] CC, [[Delta]] E). Les
frontières issues de la segmentation statistique sont projetées
sur les signaux articulatoires. Pour chaque segment projeté, est
calculée une valeur moyenne de chaque paramètre labial ainsi que
les dérivées correspondantes. Le vecteur d'observations est
finalement composé de 18 coefficients de nature acoustique, de 6
coefficients articulatoires, auxquels est ajoutée la longueur du segment
correspondant (T).
Pour fusionner les données acoustiques et articulatoires, nous
avons envisagé un modèle équivalent simplifié
correspondant au modèle maître-esclave suivant :
-- le modèle Maître est un modèle ergodique à 3
états modélisant les configurations des lèvres :
ouvertes, fermées et semi-ouvertes.
-- le modèle Esclave est un modèle gauche-droit. dont les
unités acoustiques élémentaires sont des pseudo-diphones
(André-Obrecht, 93).
Dans les deux séries d'expériences, le nombre de lettres ,
c'est-à-dire 4, est connu du système.
Cette application de reconnaissance est monolocuteur et le
système est évalué sur un corpus de lettres
connectées : chacune des phrases est composée de 4 lettres
épelées. L'apprentissage contient 158 phrases (soit 632 mots) et
le test se compose de 48 phrases (soit 192 mots).
Afin de valider ce type d'approche, nous avons comparé
systématiquement les taux de reconnaissance à ceux obtenus
à l'aide d'un modèle de Markov Caché Global construit de
manière classique en utilisant aussi le pseudo-diphone comme
unité élémentaire. Un vecteur d'observations est
traité globalement, à raison d'une loi gaussienne par transition
(matrice de covariance diagonale ).
Le MMC Global est appris initialement avec 8 coefficients cepstraux,
l'énergie et la durée. Le taux de reconnaissance avec ces seuls
paramètres acoustiques est de 89,6%. Nous avons ajouté
successivement les paramètres labiaux et leurs dérivées.
La même expérience a été
répétée en initialisant le modèle global avec 8
coefficients cepstraux, les dérivées des quatres premiers
coefficients, l'énergie ainsi que sa dérivée, et la
durée du segment. Le meilleur taux de reconnaissance, à savoir
91,6 % (taux mots) est obtenu en utilisant la hauteur et la largeur des
lèvres (figure 1.a ). L'introduction de la surface des lèvres
n'apporte pas d'information pertinente car elle est fortement
corrélée aux paramètres A et B (Benoît, 91). Les
dérivées des coefficients labiaux dégradent le taux de
reconnaissance : une des causes principales peut être le manque de
synchronisation entre les informations labiales et acoustiques, ou le manque de
données d'apprentissage.
Le même protocole d'expérimentation est réalisé pour
tester l'approche Maître-Esclave. Le coefficient labial A fait partie des
paramètres initiaux. Le meilleur taux de reconnaissance est obtenu par
le modèle ayant pour paramètres 8CC, E, T, A et B, à
savoir 91,7 % en terme de mots correctement reconnus( figure 1.b ).
Lorsque le nombre de paramètres augmente, les performances
décroissent, la cause est très certainement liée au
relativement faible ensemble de données d'apprentissage par rapport au
nombre de paramètres à apprendre.
Afin de réaliser cette étude, nous reprenons les
expériences du corpus des lettres en bruitant artificiellement à
15 dB les fichiers contenant le signal. Le bruit utilisé est de nature
"cocktail party".
Nous n'avons pas utilisé la segmentation automatique, afin de ne pas
ajouter les problèmes dus aux erreurs de segmentation à notre
problème initial. Les observations acoustiques sont donc centisecondes
et les modèles acoustiques des unités pseudo-diphones liés
à un pré-traitement segmental sont remplacés par des
modèles acoustiques plus adaptés à un découpage
centiseconde.
Etant donné que la durée du segment est maintenant constante, le
paramètre T ne fait plus partie des paramètres du modèle
Global et du modèle Maître-Esclave.
Dans le modèle Global, les paramètres de base sont les
coefficients cepstraux auxquels nous ajoutons progressivement des
paramètres labiaux et/ou acoustiques. Les résultats sont
montrés par la figure 1.c. Le meilleur taux de reconnaissance que nous
obtenons est de 78,7% ( soit 41 lettres sur 192 non correctement
reconnues ). Ce modèle n'utilise que les paramètres de base et
les paramètres labiaux A et B. L'introduction des dérivées
qu'elles soient de paramètres acoustiques ou labiaux n'apporte rien aux
performances du système. Nous constatons que l'apport de
l'énergie E dégrade les taux de reconnaissance en milieu
bruité.
Dans le modèle Maître-Esclave, le paramètre labial A et les
quatres premiers coefficients cepstraux constituent les paramètres de
base. On ajoute progressivement dans les modèles Maître et Esclave
les paramètres labiaux et acoustiques. Etant données les
dégradations observées dans le modèle Global,
l'énergie E du signal n'a pas été retenue dans le choix
des paramètres. Les résultats sont donnés dans la figure
1.d. Le meilleur taux de reconnaissance obtenu est de 77,6% (
c'est-à-dire 43 lettres incorrectement reconnues sur 192 ). Comme dans
le modèle Global, les paramètres maximisant le taux de
reconnaissance sont les 8 coefficients cepstraux ainsi que les
paramètres labiaux A et B.
Les expériences réalisées en milieu bruité ont
indiqué que les résultats obtenus avec les deux modèles
Global et Maître-Esclave sont là encore comparables.
Cependant, il faut se rappeler de l'augmentation du nombre de paramètres
de ces modèles dûe à une plus grande complexité des
modèles acoustiques centisecondes par rapport aux modèles
acoustiques segmentaux. L'ensemble d'apprentissage restant le même, ces
modèles n'ont bénéficié que d'un apprentissage
moindre. Si l'on tient compte du grand intervalle de confiance et de
l'explosion combinatoire du nombre de paramètres du modèle
Maître-Esclave par rapport au modèle Global, les résultats
obtenus sont alors comparables.
Nous avons présenté deux approches probabilistes pour
traiter la fusion de données acoustiques et articulatoires dans un but
de reconnaissance. L'approche classique consiste à supposer les
informations issues des deux canaux indépendantes tandis que l'approche
maître-esclave exploite une certaine corrélation par
l'intermédiaire de liens entre les lois d'observation.
L'approche du LIUM permet d'obtenir des taux de précision ( "accurate" )
de 96% en ambiance calme et de 91% à 10dB. Le LIA réalise des
scores de reconnaissance en termes de lettres de 90% en ambiance calme. Les
deux approches modèle global et modèle
maître-esclave donnent des résultats très comparables
dans le cadre de la reconnaissance mono locuteur de lettres
épelées (92 % de taux de reconnaissance en mots dans une ambiance
calme et 78% dans le bruit à 10dB). L'avantage de la deuxième
méthode est liée à une meilleure compréhension du
phénomène labial et offre des perspectives
intéressantes :
-- Au niveau maître, nous augmenterons le nombre d'états de
manière à se rapprocher des études statistiques qui ont
montré l'émergence de visèmes (Benoît, 91)
-- Le modèle maître-esclave est, dans son actuelle
implémentation, fort simplifié et certaines hypothèses
sont trop fortes : le passage d'un état ouvert à
celui de fermé ne se réalise pas de manière
instantanée! En fonction du volume croissant de l'ensemble
d'apprentissage qui nous sera ultérieurement fourni, nous
complexifierons le modèle simplifié pour tendre vers le
modèle exact et tester ses réelles possibilités.
--L'étude d'une désynchronisation entre le labial et l'acoustique
est plus abordable par cette approche.
L'utilisation des paramètres labiaux a pour but de rendre plus robuste
la reconnaissance automatique de parole en milieu bruité ; nous
avons montré que cette information ne dégradait absolument pas
les performances des systèmes actuels déjà très
performants. Nous étudions actuellement des rapports signal sur bruit
plus faibles.
REFERENCES
R. André-Obrecht (1988) : A new statistical approach for the
automatic segmentation of continuous speech signals, IEEE Trans. on
Acoustics, Speech, Signal Processing, vol. 36, ndeg.1, janvier 1988.
R. André-Obrecht (1993) : Segmentation et parole? Habilitation
à diriger des recherches, IRISA, Rennes, juin 1993.
C. Benoît (1991) , C. Abry, L.J. Boë : The effect of context on
labiality in french. Eurospeech , Gènes, 1991
F. Brugnara (1992) , R. De Mori, D. Guiliani, M. Omologo : A family of Parallel
Hidden Markov Models, ICASSP 92, San Francisco, 1992.
A. Foucault (1995) : Système acoustico-labial de reconnaissance de la
parole, GFCP-SFA Journées Jeunes Chercheurs, ENST Paris, 1995.
P. Jourlin (1995) : Automatic bimodal speech recognition, ICPhS-95,
Stockholm, 1995.
B. Jacob (1995) : Un outil informatique de gestion des Modèles de Markov
cachés : expérimentation en reconnaissance automatique de la
parole, Thèse de 3deg.cycle, Toulouse III, 1995.
T. Lallouache (1991) : Un poste "visage parole" couleur. Acquisition et
traitement automatique des contours de lèvres, Thèse de
doctorat de l'Institut National Polytechnique de Grenoble, 1991.
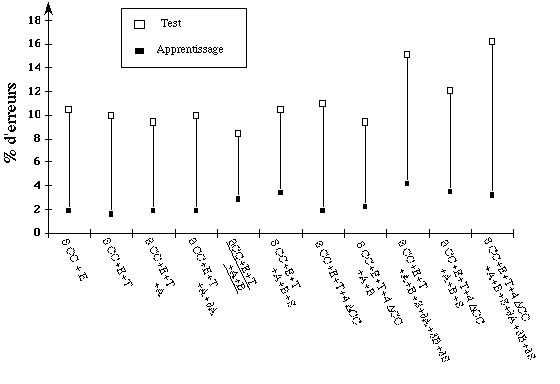
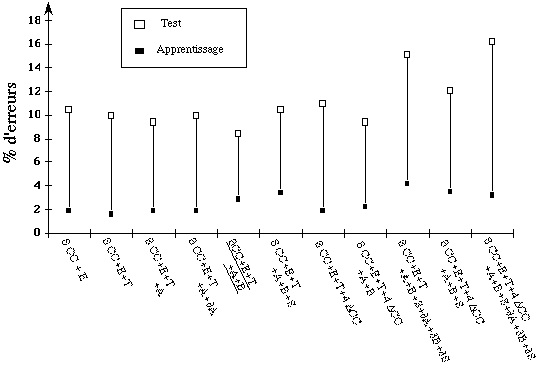 a) MMC global b) MMC Maître/Esclave
a) MMC global b) MMC Maître/Esclave
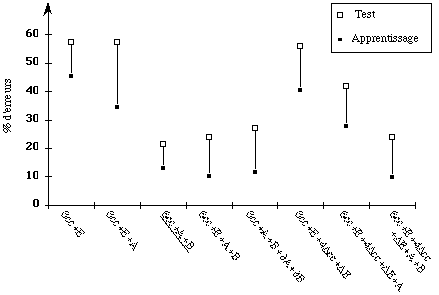
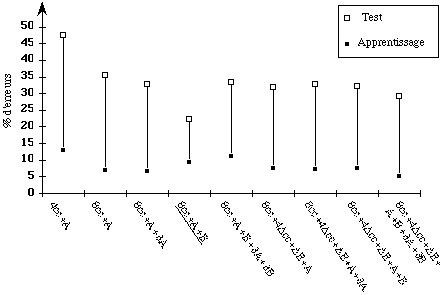 c ) MMC Global à 15 dB d ) MMC Maître-Esclave à 15 dB
c ) MMC Global à 15 dB d ) MMC Maître-Esclave à 15 dB
Figure
1 : Taux d'erreurs en termes de lettres