
Thèse
de
l'Institut de Recherche en Informatique de Toulouse
en vue de l'obtention du
Doctorat de l'Université Paul Sabatier de Toulouse III
Spécialité Informatique
en
Reconnaissance Automatique de la Parole
présentée par
Bruno JACOB
Un outil informatique de gestion de Modèles de Markov Cachés : expérimentations en Reconnaissance Automatique de la Parole
Soutenance le 27 septembre 1995 devant le jury
Guy Pérennou Professeur à l'Université Paul Sabatier ( Directeur de thèse )
Régine André-Obrecht Chargée de recherches au CNRS ( Directeur de thèse )
Marc El-Bèze Professeur à l'Université d'Avignon ( rapporteur )
Jean Paul Haton Professeur à l'Université de Nancy I ( rapporteur )
Paul Deléglise Professeur à l'Université du Maine
Annie Morin Maître de Conférence à l'Université de Rennes I
Denis Jouvet Ingénieur au Centre National des Etudes en Télécommunications
Laboratoire IRIT, Département IHM-PT, URA 1399
Université Paul sabatier, 118 route de Narbonne, 31062 Toulouse Cedex
Algorithme de Viterbi : recherche du chemin optimal dans un MMC. Les fonctions de reconnaissance et d'apprentissage utilisent uniquement cet algorithme .
AMIBE : Applications Multimodales pour Interfaces et Bornes Évoluées : projet soutenu par les Programmes de Recherches Coordonnés Informatiques 1993-1995.
Chaînage mirroir : lien d'un état vers ses prédécesseurs dans un MMC.
Classe majeure : regroupement de phonèmes ayant des comportement acoustiques proches.
Cluster : règle phonologique permettant de scinder deux sons adjacents en une unité indépendante.
Coarticulation : règle phonologique permettant d'avoir plusieurs modélisations pour une suite d'unités phonétiques.
CNET : Centre National des Études en Télécommunications : provenance des corpus utilisés.
Compilateur de réseaux : outil informatique assemblant des MMC élémentaires afin de réaliser un MMC global.
DAP : Décodage Acoustico-Phonétique : cadre d'un sujet de DEA faisant intervenir le compilateur
Ensembles d'états : regroupement d'états d'un MMC ayant en commun un état-ensemble dans leurs liens de parenté.
Filtrage lexical : algorithme de reconnaissance en deux étapes utilisant deux MMC dont les unités phonétiques sont respectivement des classes majeures et des pseudo-diphones.
HMM : Hidden Markov Model : appellation anglaise des MMC.
Lien de parenté : lien entre les états de niveaux adjacents dans un MMC. Ces liens sont du type père/fils.
MFCC : Mel Frequency Cepstral Coefficient : type des coefficients cepstraux utilisés pour représenter le signal dans les applications.
Modèle Maître/Esclave : Modèle reflétant la relation entre deux MMC mis en parallèle.
Multi-gaussiennes : MMC dont le nombre de lois d'émissions est multiplié. La reconnaissance dans un tel modèle n'utilise pas une somme pondérée de plusieurs lois, ce qui différencie ce modèle d'un MMC avec des mélanges de lois gaussiennes.
Multi-modèles : MMC possédant plusieurs modélisation pour une même unité. Dans le cadre de notre application de filtrage lexical, nous utilisons des bi-modèles : un même mot possède une modélisation pour les locuteurs masculins et une deuxième modélisation pour les locuteurs féminins.
MMC : Modèle de Markov Caché : type des réseaux créés par le compilateur.
N-meilleures solutions : base du post-traitement
Paramètres labiaux : paramètres représentant le mouvement des lèvres ( hauteur, largeur et surface ) utilisés dans le modèle maître/esclave.
Post-traitement : cadre d'un sujet de DEA faisant intervenir le compilateur.
Pseudo-diphones : unités acoustiques fines prenant en compte les parties stables et transitoires des sons.
RAP : Reconnaissance Automatique de la Parole : cadre du sujet de la thèse.
Règles phonologiques : cluster et coarticulation.
Réseaux multi-niveaux : MMC possédant plusieurs niveaux de modélisation. Le compilateur permet la création de tels réseaux.
Sous-dictionnaire : ensemble de mots correspondants à une suite de classes majeures.
TDNN : Time Delay Neural Network : réseau de neurones avec notion de durée.
TLHMM : Two Level Hidden Markov Model : MMC avec adjonction d'un deuxième niveau pour modéliser la durée.
Transition : lien d'un état vers ses suivants dans un MMC.
Il y a quelques années, la recherche en Reconnaissance Automatique de la Parole (RAP) était considérée par le grand public comme un aimable passe-temps où l'on ne se préoccupait que de problèmes sans fondement réel. Aujourd'hui les temps ont changés, les enfants ne s'étonnent plus de voir Goldorak commander à la voix son vaisseau spatial ou de regarder Deckard réaliser vocalement un agrandissement polaroïd en sirotant un gin dans "Blade Runner". L'honnête homme est tout de même troublé par les performances des systèmes de reconnaissance actuels ayant quelques difficultés à réaliser correctement quelque chose d'aussi trivial que de reconnaître sa voix, à l'heure où l'informatique triomphe dans les calculs sur des milliards de données avec des résultats spectaculaires. S'il reste en effet un domaine où la réalité a du mal à dépasser la fiction, celui-ci risque fort d'être la Reconnaissance Automatique de la Parole.
L'enregistrement du signal lui-même ne suffit pas à identifier les prononciations étant donné l'extrême variabilité du signal due aux locuteurs et au milieu environnant. La solution idéale réside dans une représentation adéquate du signal et l'élaboration d'un réel système de reconnaissance indépendant du vocabulaire et du locuteur. A l'heure actuelle, les modules classiques de reconnaissance de la parole les plus efficaces utilisent une approche statistique et plus particulièrement des Modèles de Markov Cachés ( MMC ). Il en existe une grande diversité car leur utilisation est très dépendante de l'application à laquelle ils sont destinés, les recherches autour de ces modèles sont nombreuses, chacune apportant sa "pierre". Mais néanmoins, comme nous le verrons au cours du premier chapitre de ce manuscrit, le système idéal n'existe pas et les études en reconnaissance automatique de parole donnent l'impression de piétiner. Il semble que pour surpasser les performances actuelles, il faille faire preuve d'idées originales et d'audace. Certains chercheurs le montrent en voulant introduire de nouveaux paramètres (prosodie), de nouveaux modèles (modèles articulatoires, modèles dynamiques, fusion de données). Posséder un outil suffisamment souple permettant d'accéder à ces différents niveaux d'abstraction, est un réel besoin en recherche fondamentale sur la reconnaissance automatique de la parole. Afin d'apporter une aide dans la conception de systèmes de reconnaissance fondés sur la notion de réseau probabilisé, nous avons conçu un outil permettant de compiler des réseaux multi-niveaux à partir d'un langage de compilation simple et contenant le moins de contraintes possible. La compilation permet l'assemblage de réseaux élémentaires, ce qui permet à l'utilisateur de décomposer la réalisation de ses modèles. La conception de modèles complexes peut alors s'avérer être plus simple et plus claire. Cet outil est modulable et rapidement adaptable à de nouveaux besoins sans pour cela être expert en informatique. Nous avons réalisé quelques applications dans le cadre de la reconnaissance automatique de parole afin d'évaluer cet outil informatique.
Ce manuscrit s'articule autour de trois principaux chapitres :
-- Dans un premier chapitre, nous présentons les principales méthodes utilisées en reconnaissance automatique de la parole. Nous nous penchons plus précisément sur les applications les plus répandues faisant intervenir des Modèles de Markov Cachés. Cette introduction est suivie d'une description succincte de quelques systèmes représentatifs dans ces diverses applications. L'examen de ces bases ainsi que des extensions apportées récemment aux Modèles de Markov Cachés, nous a conduit à définir le cahier des charges de notre outil informatique.
-- Dans le deuxième chapitre, la description de l'outil informatique est présentée. Nous expliquons comment générer des MMC allant de réseaux élémentaires à des réseaux multi-niveaux. Nous montrons comment intégrer des règles phonologiques, des lois multi-gaussiennes et/ou des multi-modèles à un réseau global. Nous finissons la présentation du compilateur en décrivant la structure modulaire des réseaux générés et les fonctions d'apprentissage et de reconnaissance adaptées à cette structure.
-- Au cours du chapitre trois, sont développées les applications réalisées avec le compilateur de réseaux afin de valider notre outil informatique :
* Une application classique de filtrage lexical, dans le cadre de la RAP, dans lequel nous développons un algorithme de reconnaissance en deux étapes : un sous-dictionnaire est d'abord sélectionné en utilisant comme unités de base d'un MMC global, les classes majeures. Au cours de la deuxième étape, un MMC classique modélisant les mots du sous-dictionnaire à partir d'unités de type pseudo-diphone, est construit afin d'effectuer la recherche du mot inconnu. Nous nous sommes attachés à détailler le mode de construction des MMC utilisés. Nous exposons ensuite les résultats obtenus en fonction de la complexité des modèles employés.
* Une variante d'utilisation des Modèles de Markov Cachés afin d'étudier la faisabilité d'implémentation d'extensions à partir de notre outil : nous avons adapté le compilateur afin qu'il réalise la conception d'un MMC équivalent à un modèle parallèle de type Maître-Esclave. Ce modèle permet l'intégration de paramètres labiaux dans un système de reconnaissance acoustique. Nous comparons cette approche avec une approche classique par un MMC global où les vecteurs d'observations sont la concaténation des vecteurs acoustiques et des vecteurs labiaux. Nous détaillons les modifications apportées au compilateur pour la construction du modèle Maître/Esclave et exposons les résultats obtenus dans le cadre du projet AMIBE.
* Une application où le compilateur est utilisé comme outil de vérification : la validation d'un système de Décodage Acoustico-Phonétique (DAP) à partir d'unités phonétiques issues d'une quantification vectorielle.
* Une dernière application où l'on teste la compatibilité des réseaux ainsi construits avec un autre système : une proposition de post-traitement parmi les N-meilleures solutions trouvées par un traitement principal développé au CNET.
-- Le quatrième et dernier chapitre conclut ce document en développant les extensions possibles du compilateur de réseaux. Nous discutons des algorithmes d'apprentissage et de reconnaissance adaptés à des modèles présentés dans le chapitre un. Nous nous penchons plus précisément sur les modèles traitant les observations sur plusieurs niveaux et à des échelles de temps différentes.
Les applications réalisées en Reconnaissance Automatique de la Parole ( R.A.P ) s'articulent actuellement autour de deux grandes tendances :
-- les serveurs vocaux : ces systèmes traitent des vocabulaires limités ( <= 1000 mots ). Une difficulté essentielle de mise en oeuvre de tels systèmes réside dans le fait que l'application doit être indépendante du locuteur et du canal de transmission ( radio-téléphone par exemple ). On distingue deux orientations principales dans ce style d'application :
* les systèmes à commandes vocales : le système doit reconnaître des mots isolés qui sont interprétés comme des commandes élémentaires. Il est recommandé de choisir un vocabulaire composé de mots suffisamment contrastés au niveau phonétique pour réduire les risques d'ambiguïté.
* les systèmes de compréhension : l'utilisateur peut poser une question plus complexe en utilisant des mots clés dans une phrase. On doit adjoindre au système un module de compréhension pour donner un sens à la commande afin de fournir une réponse. La syntaxe de la phrase est généralement très rigide et le mode d'élocution contraint.
-- les systèmes de dictée vocale : à l'inverse des systèmes précédents, le vocabulaire peut être de l'ordre de 20.000 à 50.000 mots et plus, la syntaxe étant celle du langage naturel. Ces systèmes sont très souvent dépendants du locuteur.
Quel que soit le type d'application envisagée et de manière très schématique, un système de reconnaissance se décompose en deux modules principaux, à savoir un pré-traitement acoustique dont le but est de réduire l'information, et un module de décision de type reconnaissance de formes. L'approche statistique est actuellement nettement privilégiée par rapport à l'approche structurelle, elle constitue le cadre de travail des systèmes les plus performants.
Les applications que nous avons nous même traitées au cours de ce travail de thèse, s'insèrent dans le cadre des systèmes à commandes vocales. Le premier système est un système de reconnaissance automatique de mots isolés prononcés à travers le canal téléphonique, multilocuteur. Bien que le vocabulaire que nous avons traité, soit limité à 500 mots, nous avons cherché à étudier au travers de cette application, la faisabilité et l'intérêt d'un filtrage lexical que l'on pourrait ensuite étendre à des systèmes de reconnaissance "grand vocabulaire". Ce filtrage consiste à définir au travers d'une première phase de reconnaissance un sous-ensemble de mots candidats et à en extraire à l'aide d'une reconnaissance plus fine la bonne solution.
Le deuxième système de reconnaissance que nous avons étudié, a pour cadre le projet AMIBE ( Applications Multimodales pour Interfaces et Bornes Evoluées ). Il s'agit d'étudier l'apport complémentaire des informations visuelles et acoustiques dans des tâches de type vérification du locuteur ou reconnaissance automatique du message oral [Jourlain, 94]. Dans le système de reconnaissance que nous proposons, l'information provenant du mouvement des lèvres est corrélée à l'information issue du signal acoustique qui peut être éventuellement bruité, à l'aide d'une machine markovienne. La tâche est monolocuteur et traite de petits vocabulaires.
Afin de mieux comprendre et mieux cerner les problèmes liés à la RAP et plus particulièrement ceux que nous avons rencontré au travers des deux applications mentionnées ci-dessus, nous consacrons ce premier chapitre à la description des principaux outils et méthodes utilisés couramment en RAP. Nous nous attardons plus particulièrement sur les méthodes statistiques puisque, non seulement elles sont présentes dans quasiment tous les systèmes de RAP, mais elles servent de base aux travaux présentés dans ce manuscrit. Nous illustrons les stratégies mises en oeuvre, les choix et critères par quelques exemples pertinents.
Un système de paramétrisation du signal, appelé aussi pré-traitement acoustique, se décompose en trois étapes, un filtrage analogique, une conversion analogique/numérique et un calcul de coefficients (figure 1.1). Son rôle est de fournir et d'extraire des informations caractéristiques et pertinentes du signal pour produire une représentation moins redondante de la parole. Le signal analogique est fourni en entrée et une suite discrète de vecteurs, appelée trame acoustique est obtenue en sortie.
Figure 1.1 Schéma général d'un traitement acoustique
L'information acoustique pertinente du signal de parole se situe principalement dans la bande passante [ 50 Hz - 8 kHz ], la fréquence d'échantillonnage devrait donc au moins être égale à 16 kHz, selon le théorème de Shannon[1] [Kunt, 91] ; mais elle peut varier en fonction du domaine d'application ou des besoins ou contraintes matériels. Pour les applications de type téléphonique, comme dans le cas de notre étude, cette fréquence descend à 8 kHz. Il s'ensuit qu'en fonction de la fréquence d'échantillonnage choisie, un filtrage analogique passe bande est effectué, afin de réduire la bande passante correctement, et il est suivi de l'échantillonnage numérique.
La trame acoustique est un ensemble de coefficients ou paramètres, calculés sur un bloc d'échantillons. Dans la plupart des applications, ce bloc d'analyse est de taille fixe, il correspond à un temps de parole de 20 à 40 ms. La suite de vecteurs d'analyse est obtenue en déplaçant ce bloc de 10 à 20 ms ; il y a recouvrement de blocs, ce qui apparente cette analyse à une analyse de type fenêtre glissante.
En reconnaissance de la parole, les paramètres extraits doivent être :
- pertinents :
extraits de mesures suffisamment fines, ils doivent être précis mais leur nombre doit rester raisonnable afin de ne pas avoir de coût de calcul trop important dans le module de décodage.
- discriminants :
ils doivent donner une représentation caractéristique des sons de base et les rendre facilement séparables.
- robustes :
ils ne doivent pas être trop sensibles à des variations de niveau sonore ou à un bruit de fond.
De nombreuses paramétrisations ont été utilisées en parole ; les méthodes issues du traitement de signal sont classiquement répertoriées en trois catégories :
A) Les méthodes fondées sur un modèle de perception comme certains vocodeurs.
B) Les transformées non paramétriques usuelles telles que la transformée de Fourier
C) Les méthodes paramétriques qui s'appuient sur un modèle simplifié de production de la parole et qui exploitent le couplage "source/conduit" (codage prédictif linéaire et cepstre).
D) Dans une quatrième partie nous verrons plus précisément la représentation que nous avons choisie pour caractériser le signal : les coefficients cepstraux.
Des modèles de perception ont pu être obtenus à partir d'études de perception et d'études psycho-acoustiques. Ils consistent à définir des bandes critiques de perception, correspondant à la distribution fréquentielle de l'oreille humaine. Les coefficients sont les sorties de bancs de filtres calibrés à partir de ces résultats : cette technique est celle utilisée dans les vocodeurs à canaux [Zurcher, 80]. Des modèles du système auditif humain sont plus récemment apparus, ils visent à rendre compte de l'activité électrique des fibres nerveuses ; cette approche est peu utilisée comme paramétrisation d'un système de RAP complet [Wu, 90].
Ce type de paramétrisation fait appel aux techniques classiques utilisées en traitement de signal : les transformées temps fréquence et temps échelle [Flandrin, 94]. Malgré quelques tentatives récentes d'exploitation des transformées de type ondelettes [Malbos, 95], la transformée la plus utilisée en parole reste la transformée de Fourier discrète. La Transformée de Fourier Rapide (FFT) permet d'obtenir des spectres en temps réel et en accroît l'importance. La description acoustique des sons qui s'appuie sur cette représentation se réalise de la façon suivante :
- un filtre de pré-accentuation est appliqué afin d'égaliser les aigus toujours plus faibles que les graves,
- un fenêtrage de type Hamming est effectué sur chaque bloc d'analyse de façon à diminuer les effets de bords dus au découpage en fenêtre,
- une FFT est calculée ; seule son module est retenu, la phase de la transformée de Fourier numérique du signal de parole ne contient pas d'information suffisamment pertinente pour la reconnaissance de parole.
Cependant, d'une part, la période fondamentale fait apparaître de nombreuses harmoniques sur le spectre d'amplitude ainsi obtenu, et d'autre part, l'information reste redondante. Il est donc courant d'effectuer des lissages dans le domaine spectral. Pour tenir compte de la perception humaine, le spectre est ramené à une échelle non linéaire Bark ou Mel, donnée par les formules suivantes :
B = 6 Arcsinh F B en Bark
600 M en Mel
M = 1000 Log ( 1 + F ) F en Hz
Log2 1000
Afin de réduire l'information, une suite de filtres (triangulaires, rectangulaires...) est appliquée dans le domaine spectral selon l'une des échelles précédemment décrites. Les coefficients obtenus sont alors synonymes d'énergie dans des bandes de fréquence. La figure 1.2 donne un exemple de répartition d'une suite de filtres selon l'échelle Mel, couramment utilisée.
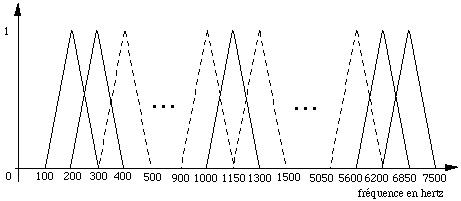
Figure 1.2 Répartition fréquentielle de filtres triangulaires (utilisée au CNET)
Ces méthodes tiennent compte du processus de phonation et s'appuient sur un modèle linéaire simplifié de production de la parole [Fant, 60]. Le signal vocal est considéré comme la sortie d'un filtre excité par une source. Le filtre modélise le conduit nasal, le conduit vocal et le rayonnement aux lèvres, tandis que la source correspond à un signal périodique ou un bruit aléatoire. L'analyse LPC (Linear Prediction Coding) simplifie ce modèle de production en supposant que le filtre ne comporte que des pôles [Markel, 76]. Les paramètres sont alors les coefficients du filtre, ils décrivent la fonction de transfert du conduit vocal.
L'analyse cepstrale résulte du modèle de production ; son but est d'effectuer la déconvolution "source/conduit" par une transformation homomorphique : les coefficients sont obtenus en appliquant une transformée de Fourier numérique inverse au logarithme du spectre d'amplitude. Le signal ainsi obtenu est représenté dans un domaine appelé cepstral ou quéfrentiel ; les échantillons se situant en basses quéfrences correspondent à la contribution du conduit vocal et donnent les paramètres utilisés en RAP, tandis que la contribution de la source n'apparaît qu'en hautes quéfrences.
Les deux familles de coefficients cepstraux les plus utilisés en RAP sont issues de deux analyses différentes pour obtenir le spectre (figure 1.3) :
-- Lorsque le spectre d'amplitude résulte d'une FFT sur le signal de parole pré-traité, lissé par une suite de filtres triangulaires répartis selon l'échelle Mel, les coefficients sont appelés Mel Frequency Cepstral Coefficients (MFCC) .
-- Lorsque le spectre correspond à une analyse LPC, les coefficients se déduisent des coefficients LPC par développement de Taylor, d'où leur nom de Linear Prediction Cepstral Coefficients (LPCC).
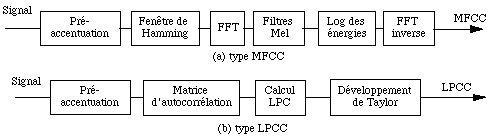
Figure 1.3 Calcul des coefficients cepstraux
Les paramétrisations présentées ci-dessus sont les paramétrisations de base. De nombreuses variantes ont été utilisées dans le but principal d'accroître la robustesse et la résistance au bruit [Mokbel, 92]. Ces coefficients caractérisent la forme statique du spectre. Afin d'introduire une information de nature dynamique sur la parole, signal composé de zones stables et transitoires, il est courant de calculer, dans le cas des coefficients cepstraux, les coefficients de régression associés qui sont les dérivées temporelles premières et secondes.
La parole est un des premiers sujets d'application de la reconnaissance des formes [Simon, 85]. Il n'est donc pas étonnant de retrouver comme principales méthodes de reconnaissance celles relevant de l'intelligence artificielle pour tenter de reproduire le raisonnement et les connaissances d'un expert, et celles empruntées au traitement de l'information [Haton, 91].
La deuxième approche est orientée vers un traitement statistique des données et a donné naissance à des systèmes dits auto-organisateurs fondés soit sur :
-- une comparaison directe par calcul de distances avec des références acoustiques [Sakoë, 78].
-- un calcul probabiliste à l'aide de modèles stochastiques ; les plus utilisés actuellement dérivent des modèles de Markov cachés (Hidden Markov Models HMM) [Levinson, 85].
-- des fonctions de coût liées à des réseaux de neurones [Waibel, 89] [Nocéra, 92].
Ces systèmes sont fondés sur les connaissances acquises par l'expérience des experts en traitement de la parole et intègrent explicitement les connaissances. Le trait principal de ces systèmes est de modéliser l'expertise de ces spécialistes sous forme de bases de données reflétant des connaissances, et d'ensembles de règles reproduisant leur "savoir-faire".
En général, ces systèmes se composent de trois modules principaux :
-- un module de pré-traitement au cours duquel sont extraits des paramètres complexes et de nature hétérogène ; des coefficients de type articulatoire comme les formants peuvent cohabiter avec des paramètres acoustiques tels que l'énergie dans des bandes de fréquence pré-déterminées.
-- un module de segmentation du signal : les données sont interprétées en termes d'unités phonétiques ou de segments minimaux proches d'unités linguistiques. Celles-ci sont modélisées à l'aide de connaissances d'experts et constituent ainsi une base de faits.
-- un module d'identification de ces unités phonétiques à partir de règles de production fondées sur les connaissances des experts dans les domaines articulatoire, acoustique, phonétique, phonologique ...
Une base de connaissances est ainsi conceptualisée par un moteur d'inférence à partir de la base de faits déjà existante.
Cependant, on ne peut modéliser entièrement le raisonnement d'un expert. Les systèmes automatisés n'en recèlent qu'une infime partie, ne serait-ce que par la limitation des connaissances que l'on peut représenter dans une machine. De fait, les performances de ces systèmes sont très inférieures à celles des experts. Par exemple, un phonéticien très entraîné peut reconnaître des phonèmes à partir d'un spectrogramme avec un taux de réussite de 85% environ [Carré, 91]. En revanche, les taux de reconnaissance de ces systèmes de décodage acoustico-phonétique ne dépassent pas 70 %.
Les connaissances ne sont qu'implicitement utilisées et automatiquement extraites au cours d'une phase d'apprentissage. Ces méthodes se distinguent de par l'existence d'unités de base apprises lors d'une phase d'apprentissage, qui peuvent être soient des exemples des formes à reconnaître (mots, phrases...), soient des modèles stochastiques (modèles de Markov cachés, réseaux de neurones...). La phase de reconnaissance s'opère alors par calcul de distances ou de vraisemblances.
Compte tenu de la forte variabilité inter-locuteur et même intra-locuteur, les prononciations d'un même mot se réalisent acoustiquement de manière fort différente ; entre autres, on observe une distorsion temporelle qui implique que les échelles temporelles des deux occurrences de ce mot ne coïncident pas. On ne peut donc comparer point à point les formes acoustiques issues de la paramétrisation, et il est nécessaire de procéder à un alignement dit temporel.
Cette comparaison s'effectue par programmation dynamique. Elle est fondée sur les travaux de R. Bellman en 1957 [Bellman, 57] pour la recherche de la trajectoire optimale. Pour formuler un système de pondération simple, celle-ci a été reprise par Sakoë et Shiba en 1970 [Sakoë, 78].
Étant donné deux images acoustiques T = (Ti, 1 <= i <= I) et R = (Rj, 1 <= j <= J) de longueurs respectives I et J et la connaissance des distances entre deux vecteurs Ti et Rj, d(i,j), la distance entre T et R est constituée de l'accumulation des distances entre les événements Tik et Tjk que l'on peut pondérer, le long d'un chemin C = ((ik,jk), 1 <= k <= K) de longueur K. La comparaison entre T et R revient à faire la recherche du chemin optimal C qui minimise cette somme cumulée en respectant les contraintes minimales suivantes:
-- faire coïncider les extrémités : le chemin doit commencer en (T1, R1) et finir en (TI,TJ),
-- obtenir une croissance temporelle stricte C k-1 < Ck ∪ k ,
-- respecter la continuité du chemin.
L'application de ces contraintes permet de respecter la dimension temporelle des signaux : on ne peut progresser indéfiniment dans les trames d'un signal en restant dans la même trame dans l'autre signal . On ne peut pas non plus régresser dans le parcours des signaux. On est obligé de parvenir en fin d'analyse à la fin des représentations des deux images acoustiques comparées.
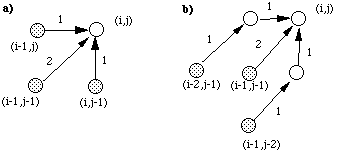
Figure 1.4 Exemples de contraintes de cheminement
S'ajoutent ensuite des contraintes locales dites de cheminement liées aux connaissances a priori sur le débit oral (figure 1.4). Le coût d'un chemin est obtenu par la formule récurrente de Sakoe et Shiba ici appliquée à la contrainte représentée en figure 1.4.b).
1) Initialisation : D(1,1) = d(1,1) et D(1,j) = D(j,1) = ∞ ∪ j != 1
2) Récurrence :
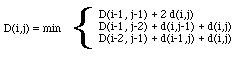
3) Coût du chemin optimal = D(I,J)
I+J
Dans un système de reconnaissance de mots isolés, fondé sur cette méthode, un ensemble de références est constitué lors de la phase d'apprentissage : pour chaque mot de vocabulaire, est acquise une (ou plusieurs) prononciation, chacune d'elles est paramétrée et donne naissance à une référence ou suite de vecteurs acoustiques R. Lors de la phase de reconnaissance, pour chaque prononciation à reconnaître T, on calcule toutes les distances entre l'observation T et les références R par comparaison dynamique. Le mot reconnu est celui qui correspond à la référence pour laquelle la distance à T est de coût minimal.
Cette approche peut s'étendre à la reconnaissance de mots connectés dans le cadre de vocabulaires restreints.
La comparaison dynamique était une des méthodes les plus utilisées dans les cartes vocales. Le système MOZART développé au LIMSI et commercialisé par la société VECSYS donne de très bons résultats [Gauvain, 82].
Cette carte permet :
-- la reconnaissance de mots isolés avec des pauses inférieures à 200 ms.
-- la reconnaissance de mots connectés avec un premier apprentissage en mots isolés puis un second en mots connectés.
-- la détection de mots clé ( word-spotting ) avec un premier apprentissage en mots isolés puis un second en prononçant une phrase contenant les mots clés dont on garde les références.
Dans les deux derniers cas on peut adjoindre au vocabulaire une grammaire du langage permis.
La tendance actuelle est d'utiliser des Modèles de Markov Cachés qui produisent aussi de bons résultats pour le même type d'application : la référence est constituée par un ou plusieurs MMC modélisant globalement le mot [Rabiner, 86].
Un modèle de Markov caché ( MMC ) ou Hidden Markov Model en anglais ( HMM ) est un graphe probabilisé dans lequel chaque noeud est censé produire un ou plusieurs segments stables ou transitoires du signal vocal. A chaque état ou noeud est associée une distribution de probabilité d'émettre un vecteur spectral.
Un modèle de Markov caché est un double processus stochastique (Xt,Yt) 1<=t<=T. La chaîne interne Xt non observable, et la chaîne externe Yt observable, s'allient pour générer le processus stochastique. La chaîne interne est supposée, pour chaque instant, être dans un état où la fonction correspondante génère une composante de l'observation. La chaîne interne change d'état en suivant une loi de transition. L'observateur ne peut voir que les sorties des fonctions aléatoires associées aux états et ne peut pas observer les états de la chaîne sous-jacente, d'où le terme de Modèles de Markov Cachés ( ou Hidden Markov Model ).
Le processus (Xt) 0<=t<=T est une chaîne de Markov d'ordre 1, il doit vérifier :
P( Xt+1 = qj / Xt = qi, ... , X0 = q0 ) = P( Xt+1 = qj / Xt = qi )
= aij pour tout t >= 0. ( 1 )
Le processus (Yt) 0<=t<=T, processus observable, vérifie :
P( Yt = yt / Xt = qi,...,X1=q1, Yt-1=yt-1,...,Y1=y1) = P( Yt=yt / Xt = qi )
= bi( yt ) ( 2 )
Les observations sont supposées indépendantes les unes des autres conditionnellement à la suite d'états. Chaque réalisation de Yt ne dépend que de l'état courant caché. Les observations yt peuvent être de nature :
-- discrète => bi est une distribution de probabilité discrète : une loi discrète est généralement représentée par les fréquences d'apparitions des observations discrètes.
-- continue => bi est une fonction de densité de probabilité définie sur Rd : les densités traditionnelles utilisées sont des densités gaussiennes, entièrement définies par le vecteur moyenne et la matrice de covariance, ou des densités de type multi-gaussiennes (sommes pondérées de densités gaussiennes).
Il s'ensuit qu'un modèle de Markov caché est caractérisé par :
-- son ensemble fini d'états Q = ( q1, ......, qN )
-- son ensemble de probabilités de transitions entre les états A = ( aij ) 1<= i <=N 1<= j <=N
-- son ensemble de lois (ou densités) de probabilités associées à un état B = ( bi (...) ) 1<= i <=N
-- son ensemble de probabilités initiales Π = ( π i ) 1<= i <=N , π i désigne la probabilité d'entrer dans le modèle par l'état initial qi. Cette probabilité est généralement égale à ( 1 / nombre d'états initiaux ).
Un modèle de Markov caché est ainsi décrit par le jeu de paramètres λ = ( Π, A, B ).
La vraisemblance d'une suite d'observations par rapport à un tel modèle, est calculée comme ci-dessous :
soient :
Y= y1,......,yT la suite d'observations
Qi = qi1,......, qiT la suite d'états de longueur T le long du chemin i
P( Y1 = y1 , ... , YT = yT / λ )
= Σ Qi P( X1 = qi1, ... , XT = qiT , Y1 = y1, ... , YT = yT / λ )
= Σ Qi P( Y1 = y1, ... , YT = yT / X1 = qi1, ... , XT = qiT , λ ) *
P( X1 = qi1, ... , XT = qiT / λ )
En réutilisant les formules (1) et (2) et après réarrangement, on obtient :
P( Y1 = y1, ... , YT = yt / λ ) = ΣQi [ π i1 bi1( y1 ) * [ Πn=2...T a in-1 in bin( yn ) ] ]
Il existe différentes manières d'utiliser les MMC en reconnaissance automatique de la parole, selon l'application visée :
-- dans le cadre d'une reconnaissance de mots isolés en nombre limité (< 100 mots), chaque mot mv du vocabulaire V est modélisé par un MMCv. La phase de reconnaissance consiste pour une suite d'observations acoustiques données, à calculer la vraisemblance de ces observations par rapport à chacun des modèles et à considérer comme mot reconnu le mot correspondant à la vraisemblance maximum. Cette approche n'est qu'une version améliorée de l'approche de type programmation dynamique.
Cette approche n'est réalisable qu'avec un vocabulaire limité dans la mesure où l'algorithme de reconnaissance considère tous les chemins modélisant chaque mot mv, ce qui entraîne un important coût de calcul.
-- lorsque la taille du vocabulaire augmente et/ou lorsqu'il s'agit de reconnaissance de mots connectés, un modèle de Markov global est construit à partir de modèles élémentaires.
* en reconnaissance de mots isolés en nombre inférieur à 1000, chaque mot mv du vocabulaire V est modélisé par un MMCv . Tous les MMCv sont liés entre eux par une entrée et une fin commune dans un réseau global. L'entrée correspond à un MMC représentant un silence précédant le mot, tandis que la fin correspond à un MMC modélisant un silence suivant le mot (figure 1.5).
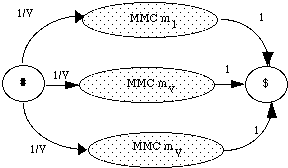
# : MMC silence précédant le mot ; $ : MMC silence suivant le mot ;
Figure 1.5 Schéma général d'un MMC global pour la reconnaissance de mots isolés
Chaque chemin du réseau global correspond à la prononciation d'un mot. En phase de reconnaissance, le mot reconnu correspond alors au chemin le plus probable étant donné la suite d'observations.
Cette approche se différencie de la précédente par l'algorithme de reconnaissance : dans ce cas, celui-ci ne prend en compte que le chemin le plus vraisemblable parmi tous ceux modélisant les mots du vocabulaire V, réduisant ainsi considérablement le coût de calcul.
* en reconnaissance de mots connectés, pour des vocabulaires de taille importante, l'utilisation de modèles globaux pour tous les mots du dictionnaire soulève quelques problèmes :
-- le stockage de tous les mots du vocabulaire devient très important
-- une grande quantité de parole est nécessaire pour réaliser l'estimation statistique de tous les paramètres ( probabilité de transitions, lois d'émissions d'observations ).
C'est pourquoi on préfère représenter phonétiquement les mots à partir d'unités phonétiques. [Jelinek, 75] [Cohen, 74] ont montré comment obtenir les représentations des mots et leurs variantes phonologiques à partir de ces unités. Un MMC élémentaire correspond alors à une unité phonétique.
Actuellement le choix de l'unité phonétique reste un problème ouvert. On peut choisir des unités de l'ordre du phonème, mais on peut alors difficilement traduire les variations dues aux contextes.
Pour pallier cet inconvénient, sont apparus les allophones qui modélisent chaque unité de l'ordre du phonème dans un contexte phonétique précis.
Une unité plus simple d'un point de vue modélisation est le fenone ; unité introduite dans les systèmes développés chez IBM, elle correspond à un MMC élémentaire au sens "machine", réduit à un seul état émetteur et à une boucle, et représentant un état acoustique élémentaire.
a) Modèle du fénone :
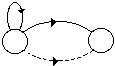
b) Forme fénonique :

Figure 1.6 Modélisation avec l'unité élémentaire du fénone
A partir de ces modèles est construit par concaténation un modèle de Markov caché pour chaque mot du vocabulaire, en tenant compte des différentes variantes de prononciation ; le modèle global est obtenu en reliant les modèles de mots selon la syntaxe de l'application. Ce type de construction permet de prendre en compte lors des différentes substitutions et concaténations, des connaissances de type phonétique et phonologique.
Au niveau phonétique, il est ainsi possible de rendre compte de phénomènes spécifiques tels que la décomposition d'un son en phases élémentaires. La figure 1.7 donne une version simplifiée d'un MMC représentant une plosive non voisée.

Figure 1.7 Modélisation des événements phonétiques d'une plosive non voisée par MMC
Au niveau phonologique sont introduites des règles inter-mot et intra-mot afin de prendre en compte les phénomènes de coarticulation et d'assimilation.
Tout chemin du graphe ainsi obtenu correspond à une phrase du langage à reconnaître et la phase de reconnaissance consiste alors, comme précédemment, à rechercher au sein du graphe le chemin le plus probable pour la suite d'observations donnée.
Le problème posé est en fait celui de la modélisation à plusieurs niveaux par des modèles MMC : les modèles de phrases sont construits à partir de modèles de mots qui eux-mêmes sont réalisés avec des modèles acoustiques. Ce procédé peut être réalisé de manière récursive. Lorsque l'on aborde la reconnaissance de parole continue (très grand vocabulaire, syntaxe non contrainte), on ne peut compiler toutes les phrases possibles à partir des mots du vocabulaire. Une solution consiste à combiner les modèles MMC de mots en les connectant à tous les mots successeurs potentiels, selon un modèle dit de langage ; nous traiterons ce cas particulier dans le paragraphe I.3 page 31.
Pour prendre en compte plusieurs locuteurs, la modélisation du signal de parole doit être améliorée par une augmentation du nombre de paramètres des MMC. En général, l'accroissement du nombre de paramètres s'effectue selon deux grandes méthodes : l'utilisation de multi-modèles et l'emploi de densités multi-gaussiennes [Jouvet, 94].
Dans le cas des multi-modèles, chaque unité à reconnaître est modélisée par plusieurs modèles. En phase de reconnaissance, l'algorithme de Viterbi cherche le meilleur chemin dans le réseau global, chacune des branches menant aux modèles étant équiprobables. L'apprentissage peut être :
-- standard : les observations sont utilisées sans information a priori en utilisant l'ensemble du réseau (Baum Welch ou Viterbi).
-- à partir d'une classification a priori des locuteurs : on affecte à chaque branche les observations correspondants à un sous ensemble de locuteurs choisis ( l'approche classique consiste à définir deux sous ensembles correspondant aux locuteurs masculins et féminins )
-- à partir d'une classification automatique des locuteurs : les branches correspondent à des classes de locuteurs. Les observations sont alors affectées aux branches à partir d'un critère ( critère de vraisemblance ou de taux d'erreurs ).
Dans le cas des multi-gaussiennes, on augmente le nombre initial de lois d'émissions de probabilité jusqu'à approcher une distribution donnée.
En phase de reconnaissance l'algorithme de Viterbi cherche le chemin optimal en "mélangeant" toutes les lois d'émissions. L'apprentissage est itératif : avant toute nouvelle itération, chaque gaussienne donne naissance à deux nouvelles gaussiennes en perturbant légèrement les paramètres de la gaussienne considérée. Le nombre théorique de gaussiennes est multiplié par deux à chaque étape.
Pour un multi-modèles, lors de la phase de reconnaissance, une fois que l'algorithme de Viterbi a choisi un début de chemin, le reste du chemin est fortement "guidé", contrairement au modèle multi-gaussiennes ou le chemin optimal emprunte des lois d'émissions indépendamment de leur mode de séparation lors de l'apprentissage.
En conclusion, la réalisation d'un système de reconnaissance à base de modèles de Markov cachés, s'effectue en trois phases :
-- Décrire un réseau dont la topologie reflète les phrases, mots du vocabulaire ou unités élémentaires à traiter.
-- Réaliser un apprentissage des paramètres du (ou des) réseau(x) λ = ( Π, A, B ).
-- Effectuer la reconnaissance proprement dite par calcul de vraisemblance.
La phase de reconnaissance selon l'application visée, consiste à calculer pour une suite d'observations acoustiques, soit sa vraisemblance par rapport à un modèle λ, soit la probabilité du chemin optimal l'ayant générée. Deux algorithmes ont été développés pour résoudre ces deux problèmes, l'algorithme de Baum pour le calcul de vraisemblance et l'algorithme de Viterbi pour le calcul du chemin optimal.
* L'algorithme de Baum repose sur le calcul de deux fonctions :
si Y= y1,......,yT désigne une suite d'observations,
-- la fonction forward α( t , qj ) représente la probabilité d'observer les t premières observations et d'être à l'instant t dans l'état qj,
-- la fonction backward β( t , qj ) représente la probabilité d'observer les T-t dernières observations sachant que l'on est à l'instant t dans l'état qj.
Ces deux fonctions se calculent par récurrence sur le temps :
α ( t , qj ) = Σ α ( t-1 , qi ) * aij * bj( yt ) ∪ t > 1
qi
α ( 1 , qj ) = π j * bj( y1 ) ∪ j.
β ( t , qj ) = Σ aji * bi( yt+1 ) * β ( t+1 , qi ) ∪ t < T
qi
β ( T , qj ) = 1 ∪ j tel que qj soit un état final (= 0, sinon)
On en déduit la vraisemblance de la suite d'observations par rapport au modèle :
P( Y1 = y1 , ... , YT = yT / λ ) = Σ α ( T , qi )
qi
ou
P( Y1 = y1 , ... , YT = yT / λ ) = Σ πi * bi( y1 ) β( 1 , qi ).
qi
∪ i tel que qi soit un état final
* L'algorithme de Viterbi [Fornay, 73] recherche le meilleur chemin au sens probabiliste, ayant généré la suite d'observations Y= y1,......,yT :
Nous nous situons dans le cas général où les émissions des lois de probabilités sont sur les états et où il n'y a pas de transition vide. Si Qi = qi1,......, qiT désigne une suite d'états de longueur T le long d'un chemin i, le chemin î recherché vérifie
P( X1 = qî1, ... , XT = qîT , Y1 = y1, ... , YT = yt / λ ) =
Μax P( X1 = qi1, ... , XT = qiT , Y1 = y1, ... , YT = yt / λ )
i
Soit Ï( t , qj ) la probabilité d'émission de la sous suite d'observations y1... yt, le long du chemin le plus probable tel que Xt = qj,
Ï( t , qj ) = Max Ï( t-1 , qi ) * aij * bj( yt )
qi
avec Ï( 1 , qj ) = π j bj( y1 ).
et P( X1 = qî1, ... , XT = qîT , Y1 = y1, ... , YT = yt / λ ) = Μax Ï( T , qj )
qj ∪ qj état final
Le chemin optimal est obtenu à l'aide de la fonction auxiliaire
ψ( t , qj ) = arg Max Ï( t-1 , qi ) * aij
qi
par récurrence arrière.
La puissance de l'approche markovienne réside dans l'automatisation de l'apprentissage des paramètres λ = ( Π, A, B ), qui se réalise à l'aide des algorithmes de Baum-Welch ou de Viterbi [Celeux, 92] .
* APPRENTISSAGE par la procédure de BAUM WELCH :
Si W = ( w1,... , wn , ... , wN ) désigne un ensemble de prononciations de phrases acceptées, la phase d'apprentissage consiste à rechercher le modèle λ* par rapport auquel la vraisemblance de W est maximale :
λ* = arg Max Π P( wn / λ )
λ n
La maximisation directe de la fonction de vraisemblance est impossible et est remplacée par un algorithme itératif qui, à chaque étape, maximise une fonction auxiliaire définie comme suit :
Q( λ, λ' ) = Σ Σ P( i, wn / λ ) ln P( i, wn / λ' )
n i
où i est un chemin quelconque du modèle défini par λ.
Moyennant quelques hypothèses sur la nature des lois d'observations, [Baum, 72] et [Liporace, 82] montrent qu'à chaque itération, partant d'un modèle λ, le nouveau jeu de paramètres λ* qui maximise la fonction Q par rapport à λ' , est meilleur dans le sens où :
Π P( wn / λ* ) >= Π P( wn / λ )
n n
La maximisation de la fonction Q est explicite et les formules de réestimation mettent à profit les fonctions forward et backward de Baum.
* APPRENTISSAGE par la procédure de VITERBI :
Si W = ( w1,... , wn , ... , wN ) désigne de nouveau un ensemble d'apprentissage, le modèle λ* est défini comme suit :
λ* = arg Max Π P( î(n), wn / λ )
λ î(n),n
où î(n) représente le chemin optimal générant la suite d'observations wn par rapport à λ.
La procédure de réestimation est semblable à celle développée dans l'algorithme de Baum Welch. Elle consiste à maximiser la fonction auxiliaire :
Q( λ, λ' ) = Σ Σ d ( i, î(n)) P( i, wn / λ ) ln P( i, wn / λ' )
n i
où i est un chemin quelconque du modèle défini par λ, î(n) le chemin optimal générant wn selon le modèle λ et d la fonction de Kronecker.
Les formules de réestimation s'apparentent alors à de simples comptages d'événements, en utilisant l'algorithme de Viterbi pour spécifier pour chaque prononciation le chemin optimal.
L'arrêt de ces deux procédures s'effectue lorsque les variations du critère utilisé sont inférieures à un seuil donné ou lorsque le nombre d'itérations est supérieur à un seuil également.
Un inconvénient de la RAP par MMC réside dans le choix du corpus d'apprentissage : il doit être le plus complet possible afin de pouvoir estimer correctement toutes les lois de transition et toutes les lois d'émissions d'observations. Dès que la syntaxe de l'application devient trop complexe, voire naturelle, et dès que la taille du vocabulaire dépasse certaines valeurs (> 1000 mots), la phase d'apprentissage devient longue et fastidieuse ; le volume des observations de l'ensemble d'apprentissage peut être prohibitif dans certaines applications. Des algorithmes de type multi-niveaux sont alors utilisés (cf Chapitre IV.2.2 et IV.2.3. pages 157-158 ).
C'est initialement par analogie avec le fonctionnement du cerveau humain que les réseaux de neurones ont été conçus. De tels réseaux sont composés d'états appelés "neurones" et de transitions appelées "synapses". Les réseaux de neurones ont des propriétés d'association, de classification, de représentation, d'apprentissage et de généralisation.
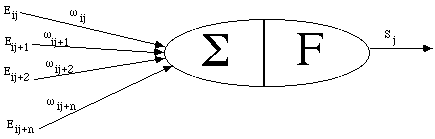
Figure 1.8 Schéma d'un neurone formel
L'ancêtre des réseaux de neurones est le Perceptron [Rosenblatt, 58], qui était un réseau très simple à une seule couche, et ne permettait pas de traiter tous les problèmes de classification. L'idée du perceptron a été reprise pour donner naissance à des réseaux multicouches.
Chaque neurone a pour tâche la propagation d'un stimulus Sj. Le stimulus est la somme pondérée des stimulisenvoyés par les neurones auxquels il est connecté.
Sj = F( Σ i ω ij * Ej ) * Tj où F est une fonction en général sigmoïde et Tj un seuil.
Chaque neurone a un seuil propre Ti de réponse à un stimulus et à chaque synapse est associé un poids ω ij.
Les réseaux multicouches sont composés :
-- d'une couche d'entrée
-- d'une ou plusieurs couches dites "cachées"
-- d'une couche de sortie
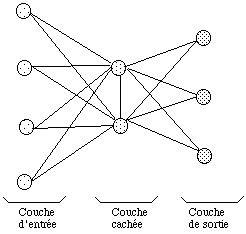
Figure 1.9 Schéma général d'un réseau multicouches
Chaque couche est composée de neurones élémentaires. Les stimulis issus d'un neurone ne sont liés qu'aux neurones des couches supérieures ou de la même couche. La couche de sortie donne le résultat de la propagation des observations dans le réseau.
Comme dans les réseaux de Markov, un réseau de neurones doit être appris avant d'être utilisé en phase de reconnaissance.
La phase d'apprentissage est généralement réalisée à partir de l'algorithme de rétropropagation du gradient qui consiste à comparer les résultats de la couche de sortie avec les résultats escomptés, en calculant la valeur de l'erreur et en la minimisant. Cette erreur est rétropropagée dans le réseau de façon à ajuster les poids et les seuils.
Evaluation et ajustement sont répétés jusqu'à l'obtention des résultats escomptés ou stabilité des résultats obtenus. L'apprentissage est fait par présentation unique ou répétée de chaque observation, de façon supervisée ou non [Austin, 92] .
La reconnaissance consiste simplement à injecter les observations dans le réseau. Elles sont propagées jusqu'à la couche de sortie donnant le résultat. Généralement le résultat est :
-- soit direct : le neurone en sortie donnant le meilleur score correspond à la forme reconnue.
-- soit indirect : l'ensemble des sorties rend compte d'une forme test qui va être comparée à toutes les formes ou références apprises.
Des variantes de réseaux de neurones multicouches ont été conçues pour prendre en compte la durée des sons [Mariani, 89] :
-- les réseaux contextuels,
-- les réseaux à retard temporel ou masque temporel ou "Time Delay Neural Network" ( TDNN )
Dans la reconnaissance de phonèmes, ils donnent de bons résultats, souvent meilleurs que ceux des MMC. Leur très grand pouvoir de discrimination permet de distinguer des phonèmes ayant des comportements acoustiques très proches [Bourlard, 92].
Leur principal désavantage est qu'ils nécessitent un apprentissage "supervisé" avec un volume de données très important et traitent assez mal la dimension temporelle de la parole.
* Les méthodes fondées sur les connaissances demandent un traitement conséquent pour ne formaliser qu'une partie du raisonnement d'un expert.
* Les méthodes de comparaison dynamique bien qu'ayant fait leurs preuves, montrent certaines limitations :
-> nécessité d'une grande capacité de stockage surtout pour les grands vocabulaires,
-> calculs relativement longs,
-> souplesse relative :
* on cherche à "obtenir un moule" d'une forme acoustique ce qui implique une certaine rigidité,
* les mots connectés le sont artificiellement,
* la reconnaissance multi-locuteurs est coûteuse,
* Les méthodes fondées sur les HMM demandent un important volume de données pour l'apprentissage. Cependant :
-> elles sont plus robustes que celles fondées sur la comparaison dynamique. Elles prennent en compte des événements imprévus qui auront une répercussion moindre sur la reconnaissance.
-> elles possèdent une plus grande souplesse de l'alignement phonétique ce qui implique une meilleure reconnaissance des début et fin de mots imprécis.
-> le problème multi-locuteur est résolu plus facilement puisque l'on peut obtenir un modèle par mot pour l'ensemble des prononciations tous locuteurs confondus.
-> pour les mots connectés, un HMM apprend les connexions, mais ne les crée pas artificiellement.
-> la structure même d'un HMM permet de modéliser à la fois des unités de base phonétiques, des mots, des phrases et des grammaires, donc un langage dans son ensemble.
* Les méthodes connexionistes donnent des résultats comparables aux HMM. Elles ont l'avantage d'être robustes au bruit, matériellement réalisables, d'être adaptatives (apprendre et généraliser des informations). Cependant on rencontre certains problèmes tels que :
-> la convergence
-> la détermination du nombre de couches
-> la détermination du nombre d'états
Les différentes méthodes peuvent se compléter : des systèmes fondés sur les connaissances utilisent des traitements statistiques sur des points précis ( différenciation de deux phonèmes proches acoustiquement par exemple ) et inversement de plus en plus de systèmes statistiques intègrent des connaissances pour améliorer leurs performances ( établissement de corpus, choix des paramètres sur lesquels porteront les calculs [Bourlard, 92] [Nocéra, 92] [Waibel, 89] ) .
La reconnaissance automatique de parole continue "grands vocabulaires" , ainsi que l'une de ses applications, la reconnaissance automatique de parole dictée, enregistrent des progrès notables ces dernières années. La plupart des systèmes de RAP "grand vocabulaire" sont fondés sur une approche purement statistique, qui autorise un apprentissage par estimation statistique entièrement automatique. La décision de reconnaissance est prise au sens du maximum de la probabilité a priori :
Si W = w1, ... , wL désigne une des phrases du langage à reconnaître et Y = y1, ... , yT, la sortie d'un processeur acoustique, la phrase reconnue U = u1, ... , uN vérifie :
U = arg Max P ( W / Y )
W
L'application de la règle de Bayes et l'indépendance par rapport à tout W, de la probabilité a priori d'observer Y, entraînent que :
U = arg Max P ( Y / W ) P ( W )
W
La probabilité P ( Y / W ) est évaluée à partir de modèles de Markov cachés créés pour chaque mot, en utilisant ou non des unités intermédiaires de modélisation (cf § I.1.2.B.b.B page 17 ) , et la probabilité P ( W ) en utilisant un modèle statistique de langage [ Haton 91].
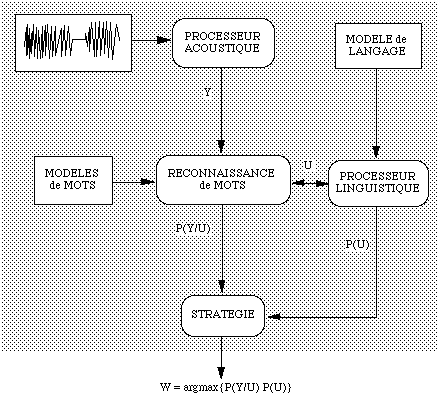
Figure 1.10 Modèle stochastique de reconnaissance de la parole comportant un niveau de reconnaissance de mots et un niveau de traitement linguistique.(d'après [Haton 91]).
Par définition, la probabilité d'observer une phrase W = w1, ... , wK s'écrit :
P ( W ) = P ( w1 ) Π P ( wk / w1,...,wk-1)
1<k<=K
Afin de réduire la complexité du langage, et par voie de conséquence son apprentissage par l'intermédiaire de ses lois, un grand nombre de systèmes n'utilise que des modèles n-grammes ou n-classes.
Pour les modèles n-grammes, on suppose que la probabilité d'observer un mot conditionnellement aux mots précédents, ne dépend que des derniers (n-1) mots prononcés. Pour les modèles n-classes, le vocabulaire est réparti en un nombre C de classes, et cette probabilité dépend de la classe à laquelle le mot appartient et des classes à laquelle appartiennent les (n- 1) mots précédents. Soit ces classes sont trouvées automatiquement ( [Jardino, 94] par le procédé de "recuit simulé" ) , soit elles correspondent à une classification a priori telle que la classification syntaxique [Brown, 92] [Derouault, 84].
modèle n grammes P ( wk / w1,...,wk-1) = P ( wk / wk-n+1, ,wk-1)
modèle n classes P ( wk / w1,...,wk-1) = P ( wk / ck-n+1, ,ck-1)
= Σ P ( wk / ck ) P ( ck / ck-n+1, ,ck-1)
ck
Dans le cas des modèles bi-classes, les modèles sont des classiques modèles de Markov cachés ; les états représentent les classes du vocabulaire, les probabilités de transitions désignent la probabilité qu'une classe Y succède à une classe X donnée, les lois d'émission la probabilité d'observer un mot dans la classe Y.
( L'outil informatique présenté au Chapitre II page 45, est réalisé dans l'optique de pouvoir intégrer ce type de modèle de langage. Cet outil permet de créer des MMC multi-niveaux. Parmi ces niveaux, certains peuvent être dédiés à des modèles de langages ).
Nous donnons dans le chapitre I.4 ci-après des applications de cette dernière approche.
Une première génération de systèmes a montré la faisabilité et l'intérêt des systèmes de RAP ; ces systèmes commercialisés dans les années 80 permettaient la reconnaissance mono-locuteur de petits vocabulaires, en ambiance calme et donnaient de bonnes performances [Gauvain, 82], [Gagnoulet, 82]. Les applications potentielles de la reconnaissance automatique de la parole ont conduit au développement de systèmes robustes au bruit pour un vocabulaire modeste, ou de systèmes dits "grands vocabulaires" dans des conditions plus clémentes. Trois principaux types de systèmes sont actuellement étudiés : les systèmes de décodage acoustico-phonétique, les systèmes robustes au bruit spécialisés dans les petits vocabulaires, les systèmes de type machine à dicter reconnaissant de grands vocabulaires et utilisant un modèle du langage. Nous nous proposons de donner un rapide aperçu de quelques uns d'entre eux.
Le rôle du décodage acoustico-phonétique est de transformer le signal acoustique, en une suite d'unités phonétiques, sans connaissance des niveaux supérieurs. C'est une tâche difficile : peu de systèmes s'approchent du taux de reconnaissance souhaitable (85%) pour s'intégrer dans des systèmes complets de reconnaissance. C'est pourquoi nombre de systèmes sont actuellement fondés sur une approche globale et non analytique, qui dispense d'un niveau intermédiaire explicite de représentations : on ne cherche pas à reconnaître une suite de sons qui serait ensuite analysée pour identifier un mot, mais on cherche directement à identifier le mot dans sa globalité. La programmation dynamique comme les modèles de Markov cachés sont alors utilisés comme outils de reconnaissance de mots et non de sons.
En décodage acoustico-phonétique cohabitent les différentes approches possibles, l'approche système expert, l'approche markovienne et l'approche neuromimétique.
Le système SERAC-IROISE [Bonneau, 86] [Gillet, 84] est un système expert inspiré du système de reconnaissance analytique de parole KEAL [Mercier, 84] ; il se compose d'une base de données ou base de règles partitionnée en modules, chacun correspondant à un type de problème, d'une base d'objets représentant les hypothèses et d'une pile de problèmes à résoudre. Les principaux modules sont l'ÉTIQUETAGE qui fournit une étiquette phonétique grossière pour chaque trame de signal, la SEGMENTATION qui vise à regrouper les étiquettes en syllabes, la LOCALISATION qui précise la partie stable des syllabes. Les données acoustiques sont de type analyse par bandes spectrales ( vocodeur 16 canaux ), la gestion est assurée par un superviseur écrit en langage orienté objet, l'ensemble contient environ 500 règles.
Le système DIRA [Caelen, 88a] [Caelen, 88b] est un système multi-experts à base de réseaux procéduraux. Il est organisé autour d'une architecture de type "tableau noir". Les experts ( décodeur acoustico-phonétique, analyseur lexical, analyseur syntaxico-sémantique, module de compréhension ) sont des automates. Au niveau du DAP, les connaissances acoustiques sont composées d'un ensemble de règles et de procédures. L'analyse acoustique consiste à extraire les paramètres fondamentaux que sont le spectre, la fréquence fondamentale, les formants, une série d'indices acoustiques et fournir une pré-segmentation infra-phonétique. Cinq réseaux phonétiques ( occlusives sourdes, fricatives, voyelles, autres consonnes et les pauses ) représentent les sources de connaissances phonétiques, le superviseur fonctionne selon deux modes, le mode proposition et le mode vérification.
Le système APHODEX [Fohr, 86] [Smaïli, 91] est un système à base de connaissances, formalisées sous forme de règles de production. Les règles sont apprises à partir de l'expertise d'un phonéticien. Après une segmentation grossière du signal, des règles contextuelles permettent d'affiner la segmentation et de fournir pour chaque unité une liste ordonnée d'étiquettes phonétiques. Chaque étiquette est pondérée par des coefficients de vraisemblance. Ce système est utilisée comme premier niveau dans la version initiale de la machine à dicter MAUD.
Le système de reconnaissance SPHINX [Lee, 88a] est fondé sur des modèles phonétiques markoviens. Chacun des 48 modèles élémentaires se décompose en un modèle à 7 états, 8 lois d'observations discrètes. Un vecteur d'observations est le résultat du codage par quantification vectorielle au travers de trois dictionnaires de 256 références chacun de 12 LPCC, de 12 dérivées de LPCC, de l'énergie et la dérivée de l'énergie. Le système de DAP donne un taux de reconnaissance de l'ordre de 65% [Lee, 88b] [Lee, 92].
Comme nous l'avons signalé précédemment, les réseaux neuromimétiques ont un fort pouvoir discriminant. Ils sont utilisés afin de distinguer des mots acoustiquement très semblables ne se différenciant que par un phonème [Anglade, 92] ; pour chaque famille de mots, est définie la zone acoustique caractéristique et un réseau de neurones à une couche cachée. Après localisation de la zone, un vecteur de paramètres de type cepstral est présenté en entrée au réseau de neurones, chaque neurone de sortie correspond à un mot.
Ces systèmes, spécialisés dans la reconnaissance d'un nombre limité de mots peuvent être considérés comme des systèmes sur mesure ; la reconnaissance est robuste pour ces mots, elle supporte des conditions de bruit sévères et une grande variété de prononciations. Les systèmes sont fondés aussi bien sur des algorithmes de type comparaison dynamique que sur la modélisation markovienne pour des résultats très comparables.
L'application "radio téléphone mains libres" suscite de nombreuses recherches. Il s'agit de reconnaissance de mots isolés en ambiance très bruitée. Afin de rendre plus robuste les systèmes, les paramètres cepstraux sont adaptés (PLP, SMCC [Mokbel, 93]) et un débruitage systématique des données peut être effectué.
-- Matra Communication applique une soustraction spectrale non linéaire (NSS) dans le cadre de la reconnaissance d'une vingtaine de noms d'un agenda, en ambiance de voiture ; chaque mot est modélisé par un HMM continu ( 16 états, 1 gaussienne par état ) et les observations sont de type "root MFCC". Le système reste monolocuteur [Lockwood, 92].
-- Le système développé par le CSELT concerne la reconnaissance d'un vocabulaire de 34 mots dans un environnement voiture. Chaque mot est modélisé par des MMC de 12 états, avec un mélange de 16 gaussiennes par état, pour traiter les différentes conditions de bruit ( différents types de conduite, rapport signal/bruit inférieur à 30dB ) et l'indépendance vis à vis du locuteur. Les observations sont de type MFCC. Le taux de reconnaissance est de l'ordre de 99%.
La reconnaissance de mots connectés nécessite la définition d'un vocabulaire de base et celle d'une syntaxe rigide. L'approche privilégiée est actuellement l'approche markovienne.
Dans le cadre d'une application de type reconnaissance d'une suite de chiffres indépendamment du locuteur, L. Rabiner a choisi de modéliser par une ou plusieurs sources markoviennes chaque mot du vocabulaire. En utilisant quatre modèles par mot, huit états par modèle, un mélange de cinq gaussiennes par état et en prenant en compte la durée de séjour dans chaque état, le taux de reconnaissance atteint 98,2% avec connaissance du nombre de chiffres et 97,1% sans cette connaissance a priori [Rabiner, 86].
Une autre application est la téléphonie mains libres où le numéro de téléphone est reconnu automatiquement comme une suite de nombres. Le système PHIL86 développé par le CNET propose la reconnaissance de nombres de 0 à 999 à partir d'un vocabulaire d'une quarantaine de mots, indépendamment du locuteur. Chacun des mots du vocabulaire est modélisé en allophone ( phonème différencié selon ses contextes possibles ). Les modèles MMC sont continus et les lois sont gaussiennes ( matrices diagonales ). Pour des observations centisecondes de type MFCC, le taux de reconnaissance est de 97% en mots connectés pour l'application des chiffres [Jouvet 91]. Limité à la reconnaissance des dix chiffres, ce modèle donne un taux de reconnaissance de 99%.
Dès que le vocabulaire croit (>1000 mots), les systèmes de reconnaissance sont amenés à intégrer un modèle de langage et il devient impossible de concevoir un modèle global pour traiter l'application dans sa totalité : l'espace mémoire nécessaire et le temps de calcul d'une recherche globale seraient prohibitifs. Un des soucis principaux de mise en oeuvre devient la réduction de l'espace de recherche sans en exclure la bonne solution.
De nombreuses stratégies reposent sur une reconnaissance en plusieurs passes : chaque nouvelle passe permet d'introduire de nouvelles connaissances.
Une approche consiste à définir des cohortes de type (CV)* [Béchet, 94] : le signal et les entrées du lexique sont codés en macro-classes du type "Voyelle/Consonne" et la réduction de l'espace de recherche s'effectue par l'application de filtres lexicaux composés de comparaisons des suites de "Voyelle/Consonne". Des pénalisations temporelles inter-phonèmes, ainsi que des règles articulatoires complètent la sélection des mots candidats. Ce système permet de réduire une cohorte de mots à 1% de la taille du vocabulaire avec 97% de chance d'avoir la bonne solution dans les cinquante premiers candidats.
Dans le cadre d'un système de reconnaissance de parole continue fondé sur une approche markovienne, Roxane Lacouture du CRIM [Lacouture, 93] propose une première phase au cours de laquelle une recherche avant puis arrière fournit un arbre des meilleures hypothèses de phrases (algorithme de type A*). La recherche avant est composée de deux sous-recherches : une approfondie en début de mot et une plus restreinte pour les fins de mots. En effet, la différence entre le meilleur chemin global et le meilleur chemin local est plus grande en début de mot ; en revanche, en fin de mot, assez d'évidences ont été accumulées pour ou contre le mot pour qu'on puisse le reconnaître avec une recherche plus simple. On peut alors intégrer des sources de connaissances plus complexes pour effectuer les phases suivantes. Cette méthode appliquée à la tâche ATIS (1410 mots) réduit du tiers le temps de la phase de reconnaissance.
Le système de Y. Minami [Minami, 93] propose une reconnaissance pour de très grands vocabulaires par modèles de type MMC et grammaires organisées en tables LR. Les réseaux de Markov représentent les phonèmes. Le résultat est un treillis de séquences de phonèmes. L'augmentation de la taille du treillis est contrôlée par une fenêtre d'ajustement et la séquence ayant le meilleur score ( calculé par un algorithme Forward -- vérification MMC / signal -- et Backward -- estimation de la succession des phonèmes ) et acceptée par la grammaire est le résultat.
Les taux de reconnaissance sur 51 phrases contenant 184 mots clés prononcés par 8 locuteurs dans le cadre d'une application de renseignements téléphoniques sont de :
- en mode phrase continue, 64% de phrases reconnues et 88% de mots clés reconnus,
- en mode phrase spontanée, 50% de phrases reconnues et 81% de mots clés reconnus.
Le système SPHINX [Lee, 90] est un système de reconnaissance, parole continue, indépendant du locuteur (masculin). Le vocabulaire est de 997 mots. Le système est fondé sur la description statistique de chaque mot en utilisant comme unité de base, l'allophone et sur une grammaire récursive à états finis ( RFSG ). Les modèles phonétiques de type MMC sont appris sur 100.000 phrases prononcées par 500 locuteurs masculins [Lee, 92] ; la reconnaissance fonctionne en temps réel sur MacIntosh. On obtient un taux de reconnaissance de 98% sur l'ensemble d'apprentissage. En parole spontanée, le taux d'erreur est multiplié par 2 ou 3 .
L'application privilégiée de la reconnaissance automatique de parole continue "grands vocabulaires" est certainement la machine à dicter vocale. Les premières furent proposées par IBM :
-- dans le système français monolocuteur [Mérialdo, 87] [Mérialdo, 88], les mots sont prononcés en distinguant chaque syllabe. La modélisation du vocabulaire comprend trois niveaux distincts :
* chaque mot se décompose en une suite de syllabes phonétiques (6400 syllabes)
* la syllabe phonétique s'écrit comme une suite d'unités phonétiques
* une unité phonétique est modélisée par un MMC à 7 états (130 MMC contextuels)
Une première phase de reconnaissance consiste à sélectionner un sous-dictionnaire en utilisant un modèle markovien dont les unités sont des classes de syllabes. Les N meilleures classes sont soumises à un décodage détaillé pour préciser la syllabe.
Ce procédé de présélection par sous-dictionnaire réduit les calculs d'un facteur de 14,17 [Mérialdo, 87].
-- le système TANGORA développé par l'équipe L. Balh, propose une reconnaissance de phrase dépendante du locuteur, à partir d'un vocabulaire de 5.000 à 20.000 mots. Il utilise un modèle de langage tri-gramme et le "fenone" ( cf page 19 ) comme unité acoustique. Les observations sont composées de 20 coefficients cepstraux ( modèle d'oreille ). Les MMC élémentaires sont discrets, fondés sur un dictionnaire de 200 références. Il est adapté à plusieurs langues. Pour 5.000 mots est atteint un taux de reconnaissance de 97,1%, pour 20.000 mots un taux de 94,6% [Cerf-Danon, 91].
Le système DRAGON-DICTATE 30K est commercialisé depuis 1990 par Dragon Inc. [Baker, 89]. Il peut reconnaître 30.000 mots dont 5000 sont définis par l'utilisateur. Il utilise des phonèmes en contexte PIC modélisés par des MMC et un modèle de langage statistique : le premier apprentissage s'effectue sur la segmentation des réalisations de plusieurs milliers de mots choisis pour représenter tous les phonèmes dans la plupart des contextes existants. L'adaptation au locuteur se réalise pendant les reconnaissances successives : il faut prononcer entre 1000 et 2000 mots. Ce système est adapté à la plupart des langages européens [Bamberg, 91] [Baker, 93]. Le taux de reconnaissance pour un locuteur ayant réalisé l'apprentissage est de 94%, pour un locuteur novice de 84%.
Le système de reconnaissance en parole continue de PHILIPS RESEARCH SYSTEM utilise un modèle de langage bi-gramme et l'unité acoustique de base est le phonème. Il est adapté à l'allemand pour un vocabulaire de 13.000 mots [Steinbiss, 93]. Ce système est utilisé dans le cadre d'une application réelle par des radiologues et des avocats. Un des atouts de sa phase de reconnaissance repose sur la réduction de l'espace de recherche par une organisation en arbre du lexique et une technique de prévision des phonèmes successeurs à partir d'un seuil : seuls les successeurs les plus probables font partie de l'espace de recherche. Pour un apprentissage de 9 heures de parole par locuteur, le taux de reconnaissance est de 90% .
Le système de dictée vocale développé par le LIMSI [Gauvain, 94] [Lamel, 92] utilise également un modèle markovien : les paramètres acoustiques sont les MFCC, leurs dérivées premières et secondes, l'unité de base est l'allophone, modélisé par des multi-modèles correspondant aux modèles homme et femme et aux variantes inter et intra mots. La durée des phones est prise en compte ainsi que des règles inter et intra mots pour tenir compte des différentes variantes phonologiques. Le vocabulaire de base est de 20 000 mots. Le modèle de langage est bigramme au cours d'une première passe de reconnaissance et trigramme lors de la deuxième passe. Ce modèle est appris à partir de textes issus du corpus écrit du Wall Street Journal ( 37 millions de mots écrits ). Un sous-ensemble acoustique de ce corpus est utilisé pour l'apprentissage acoustique. En phase de reconnaissance, dans la mesure où la couverture lexicale du WSJ (64 000 mots) n'est pas assurée par le vocabulaire de base, des tests dits ouverts sont réalisés et permettent d'afficher des taux de reconnaissance de l'ordre de 91%.
Malgré les indéniables progrès réalisés en reconnaissance de parole, les performances humaines restent supérieures dans bon nombre de tâches et des questions demeurent en suspens : il est particulièrement frustrant de constater que l'introduction de connaissances dans les modèles classiques proposés ne permettent pas d'apporter l'amélioration tant attendue ! Très souvent, des dégradations peuvent même apparaître dès que l'on s'éloigne de la paramétrisation type MFCC ou de la modélisation markovienne standard.
L'introduction de connaissances peut se faire de deux manières différentes :
-- modifier le pré-traitement et introduire dans un MMC de nouveaux paramètres sans précaution préalable et notamment sans prendre en compte d'éventuelles corrélations
-- modifier le pré-traitement et adapter la structure markovienne.
Au niveau du pré-traitement acoustique, une segmentation automatique du signal est effectuée et chaque segment est paramétré et donne UN vecteur d'observations de nature spectrale. Ce pré-traitement peut n'être utilisé qu'en apprentissage [Lee & Soong, 88] pour aider la phase d'apprentissage. Il peut aussi être utilisé en apprentissage comme en reconnaissance, le modèle de Markov caché doit être adapté au niveau de sa topologie [ André-Obrecht 90] (nous détaillerons plus largement cette approche au chapitre 3, puisqu'il s'agit de notre propre démarche).
Dans l'utilisation classique des modèles de Markov cachés, le temps de séjour dans un état correspond à la durée d'un son élémentaire, mais il suit une loi exponentielle, loi tout à fait inappropriée pour tenir compte de la réalité de durée des sons. Sont apparus les modèles semi markoviens pour lesquels les probabilités de transition de type aii sont remplacées par une loi de type gaussienne ou de type gamma, modélisant le temps de séjour dans un état (nombre d'observations liées à cet état).
La vraisemblance d'une suite d'observations y1, ... , yT relative à un tel modèle devient, en reprenant les notations du § I.1.2.B.b.A page 15 :
P( Y1 = y1... YT = yt / λ ) =ΣQi [ π i1Π1<=τ<=τ1 bi1(yτ) di1(τ1) x [ Πn=2...S a in-1 in [ Π1<=τ<=τn bin(yjτ)] din (τn) ] ]
où Qi = i1...in-1 in...iS avec in-1!= in ,
τn est le nombre de vecteurs observés en l'état in,
din ( ) est la loi modélisant le temps de séjour dans l'état in, pour tout n.
S est le nombre d'états distincts traversés S <= T.
Les paramètres modélisant la durée sont initialisés avec des données statistiques tirées de corpus ( par exemple une voyelle dure environ 60 ms ) . Ils sont réestimés en utilisant le temps de séjour dans les états acoustiques leur correspondant.
Afin de modéliser la durée d'un son et de manière plus générale afin de modéliser des paramètres supra segmentaux de nature phonétique tels que les paramètres prosodiques, un modèle à deux niveaux, un TLHMM ( Two Level Hidden Markov Model ), est défini [Suaudeau, 94b]. Un modèle de Markov classique est construit de manière hiérarchique -- la notion de hiérarchie sera développée dans le chapitre II, page 45 -- en utilisant une unité intermédiaire de type allophone. Chaque état acoustique dépend d'une unité unique ; est alors modélisée la durée de séjour dans une unité, définie comme la somme des durées de séjour dans chaque état acoustique de l'unité considérée. L'algorithme d'apprentissage et l'algorithme de Viterbi sont adaptés en conséquence.
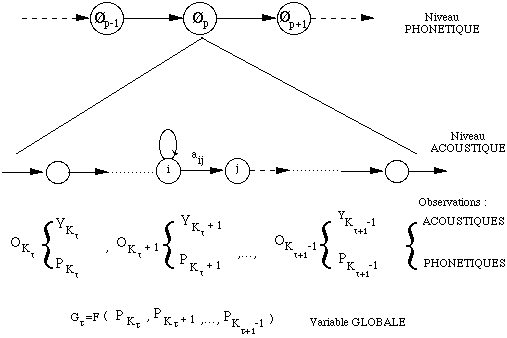
Figure 1.11 Hiérarchisation au sein du TLHMM, d'après [Suaudeau, 94a]
Comme nous l'avons dit précédemment, les modèles de Markov cachés permettent de gérer correctement la séquentialité du continuum qu'est la parole, alors que les réseaux de neurones sont plus discriminants au niveau de la caractérisation d'un son. Il est donc apparu des modèles dits hybrides dont le but est de tirer avantage des deux types de méthodes.
Il existe différentes manières de fusionner les deux approches [Tokkola, 94] :
-- substituer les sorties de réseaux de neurones employés comme classificateurs de type phonétique, aux résultats de la traditionnelle quantification vectorielle utilisée dans les MMC discrets.
-- utiliser des perceptrons multi-couches pour évaluer des lois de probabilités en guise de lois d'observations [Bourlard, 92].
-- proposer comme modèles élémentaires dans une approche de type DTW ou markovienne, des réseaux de neurones [Cheng, 92].
Le principal inconvénient du MMC est son inefficacité à gérer des données de nature hétérogène ou provenant de sources différentes . Différentes solutions sont apparues selon que les observations provenaient de capteurs différents (deux microphones, image et son...) ou deux pré-traitements différents d'un même signal acoustique (formants, cepstre...)
* Modèles combinés : l'idée la plus simple est de proposer un modèle de type Markov pour chaque source d'observations et de combiner les modèles au sens probabiliste, c'est à dire en utilisant des produits de mesure. Ce type de modèle est utilisé en reconnaissance de parole en milieu bruité, le bruit étant une source d'observations, et la parole l'autre [Gales, 94].
On peut également citer [Jourlin, 95 ] qui propose un système combinant le mouvement des lèvres avec le signal acoustique afin de pallier la perte d'information engendrée par le bruit au niveau acoustique. Nous nous sommes penchés sur une étude similaire en utilisant deux modèles parallèles.
* Modèles parallèles : lorsque deux types d'observations sont disponibles, deux sources markoviennes sont créées mais elles ne sont pas indépendantes comme elles peuvent l'être dans l'approche précédente. Les deux modèles sont reliés par une relation de type maître/esclave, les lois du modèle esclave (matrice de transitions, lois d'observations) dépendent à tout instant de l'état dans lequel se trouve le modèle maître. Cette modélisation est utilisée pour introduire une modélisation de la durée des sons [Brugnara, 92] ; nous l'avons nous-mêmes utilisé pour traiter simultanément des données labiales et des données acoustiques. Nous détaillons ces expériences chapitre III.B page 119.
* Modèles articulatoires : :pour intégrer des connaissances de type articulatoire, voire dynamique, deux études sont proposées selon leur caractère explicite ou implicite :
-- si l'on considère qu'il existe un niveau intermédiaire de représentation qui n'est pas le niveau phonétique traditionnel, mais un niveau articulatoire, il faut alors repenser l'écriture lexicale, introduire les règles d'assimilation et de coarticulation [Deng, 94a] ; les connaissances sont introduites implicitement dans la topologie des modèles.
-- certains phénomènes articulatoires peuvent se traduire explicitement par des équations de liaison entre données ; le problème est alors d'introduire ces dépendances au niveau des observations. Une première tentative est actuellement expérimentée pour reconnaître des voyelles en contexte occlusif, elle consiste à expliciter les variations linéaires des formants au cours du temps, en liant les moyennes des lois d'observations des modèles markoviens [Deng, 94b].
D'après ces quelques points de repères, les meilleurs résultats en Reconnaissance Automatique de la Parole sont issus de systèmes fondés sur des Modèles de Markov Cachés. La raison en est, entre autres, l'extrême variabilité du signal vocal, et les systèmes de reconnaissance globale -- ne considérant seulement que la forme acoustique des mots -- semblent les mieux adaptés.
Il est néanmoins intéressant de pouvoir prendre en compte les nombreuses autres connaissances que l'on peut extraire du signal de parole ( cf paragraphe I.5 page 38 ). Les outils existants ne permettent pas d'accéder facilement à des modèles dérivés des MMC classiques. Pour aborder de telles études, nous avons voulu construire un outil suffisamment souple pour permettre de créer des systèmes de reconnaissance hiérarchiques, où il est possible d'accéder à tout niveau de construction, l'unité de base restant un réseau de type MMC. Les fonctions d'apprentissage et de reconnaissance sont adaptées à ces structures de réseaux. Les réseaux de Markov ainsi générés peuvent intégrer les décompositions successives de phrases, de mots sur plusieurs niveaux et sont capables de prendre en compte des règles phonologiques. Il est possible d'obtenir des réseaux possédant des mélanges de lois gaussiennes, contenant des multi-modèles, et des flux de lois.
Après avoir présenté cet outil, et afin de le valider, quelques applications le mettant en oeuvre sont exposées :
-- La première présente une approche pour la reconnaissance de mots isolés dans le cadre de vocabulaires importants, fondée sur l'apport d'une segmentation a priori du signal, sur la modélisation de type MMC d'un lexique en utilisant la notion de classes majeures, et sur la modélisation temporaire de type MMC d'un sous-dictionnaire à partir d'unités de type pseudo-diphone.
-- La deuxième propose une étude sur l'apport du mouvement des lèvres par rapport au signal vocal. Le compilateur de réseaux génère un modèle équivalent à celui d'un modèle de Markov de type maître/esclave, le modèle générant les observations labiales pilotant celui émettant les observations acoustiques.
-- Nous nous sommes servi du compilateur comme d'un outil de validation d'un système de Décodage Acoustico-Phonétique par rapport aux alignements d'un expert.
-- Cet outil a été utilisé pour concevoir un système de post-traitement des solutions proposées par un module de reconnaissance développé par le CNET ; l'application concerne la reconnaissance des 500 mots les plus fréquents du français, en mode multi-locuteurs.
Des pré-traitements acoustiques segmentaux et des unités de base différentes sont utilisés selon l'application (phonème, classe majeure, pseudo diphone), et des systèmes de reconnaissance multi-passes (phase de reconnaissance, post traitement) sont évalués.
La plupart des applications en reconnaissance de la parole utilisent des modèles de Markov cachés (MMC), construits de manière hiérarchique à partir de réseaux élémentaires. De nombreux outils sont actuellement disponibles tels que PHIL90 [Jouvet, 86] ou HTK [Young, 92]. Malheureusement, nos besoins en matière de création et de gestion de graphes et d'arbres ne correspondaient pas à leurs caractéristiques.
La composante du système de reconnaissance PHIL90 est un générateur ou compilateur de réseaux MMC d'utilisation conviviale pour la reconnaissance de la parole. L'application est modélisée à partir de niveaux définis selon une hiérarchie précise: le niveau syntaxique, le niveau lexical, le niveau phonétique et le niveau acoustique. Chaque niveau correspond à un réseau, et chaque noeud d'un réseau correspond à un réseau de niveau inférieur. Par concaténation et substitution, on obtient ainsi un réseau global, appelé réseau compilé. Au niveau inférieur, le niveau acoustique, les réseaux correspondent à des MMC séquentiels de type "gauche-droite". L'ensemble des états du réseau global est strictement ordonné : après renommage, un état ej ne peut être atteint qu'à partir d'un état ei, i<=j. Les algorithmes de reconnaissance et d'apprentissage dépendent de cette structure de réseau.
Le logiciel HTK est un outil très complet, offrant une grande variété de modélisations acoustiques et de topologies de réseaux possibles avec des fonctions d'apprentissage et de reconnaissance performantes. Nous désirions toutefois avoir la possibilité de garder une trace des étapes de modélisation des réseaux construits ; or HTK ne met à la disposition de l'utilisateur que le résultat final.
L'outil de base que nous développons est un compilateur de réseaux inspiré de PHIL90. A partir de réseaux élémentaires de type MMC et d'instructions de base, un réseau hiérarchique structuré en niveaux est obtenu :
-- le niveau "le plus bas" représente le réseau actif ; les transitions et états de ce niveau sont dits actifs ; il comprend en particulier les transitions porteuses des lois d'observations.
-- les niveaux supérieurs représentent les étapes successives de la construction du réseau actif.
Le compilateur de réseau doit être un outil d'aide à la mise en oeuvre de Modèles de Markov Cachés. Dans cette optique, nous développons un langage composé d'instructions élémentaires pouvant décrire ces réseaux avec le moins de contraintes possibles. Ces instructions sont regroupées dans un fichier texte en entrée du compilateur. Celui-ci crée en mémoire le modèle correspondant. Ce MMC est construit dynamiquement afin de ne réserver que l'espace mémoire minimal nécessaire, ceci dans l'optique de créer des réseaux importants.
Le modèle compilé peut être sauvegardé, restauré et servir de support aux diverses fonctions d'apprentissage et de reconnaissance.
Nous distinguons, dans l'ensemble des instructions, trois grandes familles de rubriques :
-- la première famille contient des rubriques construisant des réseaux élémentaires,
-- la deuxième est relative à la gestion de réseaux, par exemple l'imbrication de réseaux élémentaires dans un réseau global,
-- la troisième rassemble les rubriques prenant en compte l'interprétation de règles phonologiques, par exemple les coarticulations.
Nous présentons ensuite les particularités des structures de réseaux générées et les variantes de construction des modèles de Markov pour obtenir une approche des mélanges de lois gaussiennes et des réseaux formés de multi-modèles.
La description de cet outil se termine par la présentation des algorithmes d'apprentissage et de reconnaissance adaptés à ces structures.
Un réseau se caractérise par l'ensemble de ses états et de ses transitions. Après avoir précisé la syntaxe de leur description, nous indiquons comment former un réseau élémentaire.
* Les états :
Les états sont destinés à représenter des unités telles que des sons infra phonétiques, des classes majeures, des pseudo-diphones, des mots... Il nous a semblé utile de pouvoir regrouper les occurrences d'une même unité : tous les états représentant le phonème /a/, peuvent être modélisés par un même MMC (même topologie et mêmes lois de probabilités), si l'on ne considère pas le contexte, par exemple.
Figure 2 . 1 : Exemple de classes d'états
Pour introduire cette notion de classe d'états, correspondant à une unité, la syntaxe du nom d'un état est formée d'une racine et d'une extension. La racine désigne le nom de la classe et l'extension permet de spécifier un état unique dans le modèle global. Dans l'exemple présenté Figure 2.1, la classe"m" regroupe les états "m.ma" et "m.mur", deux occurences de l'unité phonétique /m/.

Figure 2 . 2 : Exemple de nom d'état
* Les transitions :
Les MMC que nous générons émettent des observations sur les transitions et non sur les états eux-mêmes à la différence du modèle théorique présenté au paragraphe I.1.2.B.b.A page 15.
Il s'ensuit qu'une transition est entièrement spécifiée par un couple d'états et une loi d'observation. Les transitions peuvent supporter des lois discrètes ou continues, ou être éventuellement vides, c'est à dire ne générant aucune loi. La particularité des transitions vides est de permettre de changer d'état sans avoir de progression temporelle. On doit toutefois faire attention à ne pas créer de cycle vide dans la topologie des MMC : les états du cycle seraient examinés dans une boucle infinie pour un même instant donné.
A chaque transition est donc associée une probabilité de transition et un numéro de loi. Par convention, les transitions vides portent le numéro de loi 0 et sont représentées par des traits pointillés dans ce document. Tout autre numéro réfère à une structure de calcul caractérisant une loi. Une structure de calcul permet de définir les paramètres de la loi de probabilité concernée :
-- pour une loi discrète, la structure de calcul contient les valeurs des probabilités discrètes
-- pour une loi gaussienne, la structure de calcul possède les valeurs de la moyenne et de la matrice de covariance ( Figure 2.3 ) .
Figure 2 . 3 : Différence entre transitions pleines et vides : un lien est établi entre la transition non vide et la structure de calcul de la loi gaussienne qui lui est associée
Une transition ne générant qu'une seule loi de probabilité, si entre deux états, des observations peuvent être émises par plusieurs lois de probabilité, il est nécessaire de créer autant de transitions que de lois désirées. Une même structure de loi peut être associée à plusieurs transitions.
Un "chaînage miroir" est associé à chaque transition : par exemple, à une transition entre deux états correspond un chaînage arrière ( Figure 2.4 ) . Lors du parcours d'un tel graphe, on peut ainsi connaître à tout instant les prédécesseurs d'un état et, bien entendu, ses suivants.
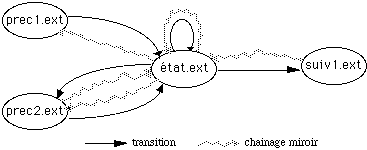
Figure 2 . 4 : Exemple de chaînage miroir
L'intérêt de ces chaînages réside dans le fait que les algorithmes de calcul du coût maximum du chemin d'un état initial à un état courant, recherchent les prédécesseurs de cet état courant. Pour atteindre les états prédécesseurs, les méthodes couramment utilisées sont telles que :
-- tous les états du graphe sont examinés et seuls sont considérés ceux qui ont une probabilité de transition non nulle à partir de l'état courant.
-- les états sont ordonnés pour des modèles gauche/droite par des indices et l'on réduit l'espace de recherche des prédécesseurs de l'état courant en imposant qu'un état ei ne peut être atteint qu'à partir d'un état ej avec j <= i.
Ces chaînages miroirs nous permettent d'accéder directement aux prédécesseurs de l'état courant.
* Définition d'un réseau :
La caractérisation d'un réseau simple d'un seul niveau s'obtient en décrivant ses états initiaux, ses états finaux, et ses transitions. L'utilisateur le définit en se servant des rubriques RESEAU donnant un nom au réseau, INITIAL et FINAL comprenant respectivement les noms des états initiaux et finaux, puis des rubriques TYPE et TRANSITIONS.
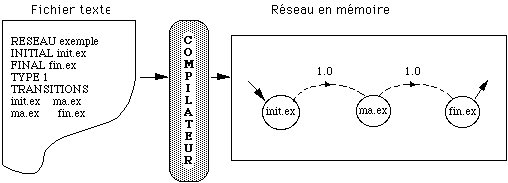
Figure 2 . 5 : Construction d'un réseau élémentaire
Bien que les modèles de Markov utilisés au cours de nos expérimentations soient pour la plupart des modèles "gauche-droite", la syntaxe des transitions permet des retours arrières.
Comme nous l'avons signalé précédemment, il est possible d'avoir plusieurs transitions entre deux états, une transition correspondant à une seule loi de probabilité. Les transitions sont décrites dans la rubrique TRANSITIONS en spécifiant le couple d'états, une probabilité de transition et un numéro de structure de loi
On peut distinguer ces transitions de celles présentées au paragraphe II.6 page 67 pour la création de multi-gaussiennes par le fait que celles décrites ici sont explicitées par l'utilisateur.
Afin de faciliter la saisie des transitions, une rubrique TYPE est introduite. Selon le code du type utilisé ( 1, 2 ou 3 ), l'utilisateur peut "alléger" la description des transitions en ne précisant qu'une partie de leurs caractéristiques ( cf Annexe A3 ).
La deuxième famille d'instructions est utilisée pour "imbriquer" des réseaux. L'opération de base consiste à remplacer une classe d'états appartenant à un réseau initial par un sous-réseau : le sous-réseau est instancié dans le réseau à la place de chaque état de la classe d'états référencée dans les rubriques ci-dessous.
Il existe deux sortes de sous-réseaux : les réseaux "locaux", dont les structures sont décrites dans le même fichier texte que le réseau global, et les réseaux "externes" dont la structure est déjà définie dans un autre fichier.
Les réseaux locaux permettent de construire un MMC global de manière hiérarchique, en décomposant la création du réseau niveau par niveau.
Les réseaux externes font appel à des MMC appris séparément afin de bénéficier des réestimations de leurs paramètres et de réutiliser leur topologie. A chaque appel , une copie du réseau externe est intégrée dans le réseau global. Le réseau original ne peut bénéficier des apprentissages effectués sur le réseau global. Nous envisageons cependant cette extension dans le paragraphe IV.2.3. page 158.
Nous désignons ici les sous-réseaux élémentaires dont la structure est définie dans le même fichier texte que la structure du réseau global. Les instructions utilisées pour décrire ces sous-réseaux sont donc interprétées afin de construire les modèles élémentaires en mémoire avant de les intégrer au réseau global.
Les rubriques ci-dessous se rattachent à une description de réseau élémentaire et contiennent la liste des classes d'états à remplacer par ce sous-réseau selon différentes conventions. Pour chacun des états appartenant à ces classes, une copie du sous-réseau est effectuée. Cette copie peut s'effectuer de diverses manières selon le résultat recherché. On peut envisager par exemple pour un réseau modélisant les voyelles :
-- une même topologie pour toutes les voyelles : un modèle unique avec autant de lois que de voyelles.
-- les mêmes lois pour chaque unité appartenant à une voyelle commune : toutes les unités référant à un /a/ ont les mêmes lois : les réestimations des modèles de tous les mots contenant un /a/ concourent à l'apprentissage du modèle de cette voyelle.
-- des lois différentes pour chaque unité : on se rapproche d'un modèle global de mot contenant ses lois propres.
Ceci nous a conduit à créer trois rubriques d'imbrication de topologie de réseaux :
* rubrique LIENS : les états d'une classe héritent des mêmes lois de probabilités : on obtient un réseau par classe.
* rubrique LIAISONS : chaque état réfère à ses lois de probabilités propres. Chaque état hérite d'un réseau différent.
* rubrique COPIES : tous les états de toutes les classes ont les mêmes lois de probabilité. Tous les états héritent d'un réseau identique.
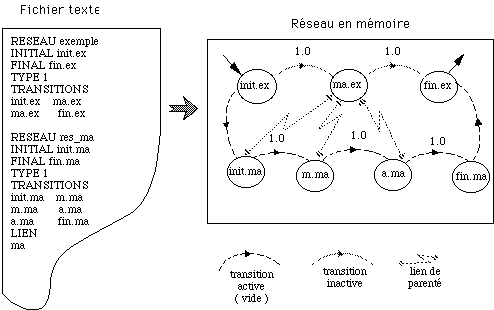
Figure 2 . 6 : Exemple de "Lien" de l'état "ma" au réseau "res_ma"
Tous les états ayant pour racine"ma" dans le réseau "exemple" sont remplacés par le réseau "res_ma"
Nous désignons par externe, un réseau dont la structure est déjà définie dans un autre fichier. Cet autre fichier contient la sauvegarde du réseau. En général, celui-ci peut déjà avoir fait l'objet d'une construction en multi-niveaux et avoir subi divers apprentissages. Ce réseau externe a donc ses propres lois d'émissions et ses propres probabilités de transitions entre ses états.
Pour être utilisé, un tel réseau doit être chargé en mémoire à partir de son fichier de sauvegarde. Il est identifié de manière unique par son nom .
* rubrique CORRESPONDANCES : ce mot clé détermine l'entrée du bloc de commandes d'instanciations d'états par des réseaux externes.
Les rubriques suivantes sont répétées autant de fois qu'il y a d'instanciations .
* rubrique NOM_RESEAU : référence un réseau externe par son nom . Celui-ci doit être chargé en mémoire.
* suivant le mode d'imbrication désiré, on active les rubriques LIENS, LIAISONS ou COPIES.
Afin de prendre en compte les variantes phonologiques des mots, nous introduisons les notions de "Cluster" et de "Coarticulation".
Les "Clusters" sont inspirés du besoin de traduire le fait que deux phonèmes consécutifs produisent parfois un autre son. La modélisation de ce son doit donc remplacer les modélisations des deux phonèmes consécutifs. Ce remplacement revêt un caractère obligatoire.
Par exemple les phonèmes /t/ /r/ produisent le son /tr/ qui est traité comme une seule entité.
Les "Coarticulations" permettent de prendre en compte le fait qu'une suite de phonèmes consécutifs peuvent s'influencer pour réaliser un son différent. Une suite de modélisations de phonèmes peut donc être doublée par une autre modélisation.
Par exemple le mot "venir" peut se prononcer "v'nir", ce mot pourra être modélisé avec les deux suites de phonèmes /v/ /e/ /n/ /i/ /r/ et /v/ /n/ /i/ /r/.
Ces fonctions mettent en place de nouvelles liaisons dans les décompositions déjà effectuées des mots du vocabulaire.
Ces nouvelles liaisons peuvent être obligatoires ("Cluster"), ou facultatives ("Coarticulation" ). Les "Coarticulations" et les "Clusters" peuvent faire appel à des réseaux locaux ou externes. Dans le premier cas nous parlerons de "Clusters locaux" ou de "Coarticulations locales", dans le second cas nous parlerons de "Clusters externes" ou de "Coarticulations externes".
* rubrique CLUST_LOCAUX :
Syntaxe : <racine d'état_1> <racine d'état_2> = <racine d'état cluster>
Toutes les transitions entre les états appartenant aux classes 1 et 2 sont supprimées ; un état-cluster est créé et relié par des transitions aux états adjacents ( Figure 2.7 ).
L'état cluster doit ensuite être rattaché à un sous-réseau local dans la définition d'un modèle élémentaire décrit ultérieurement dans le même fichier texte.
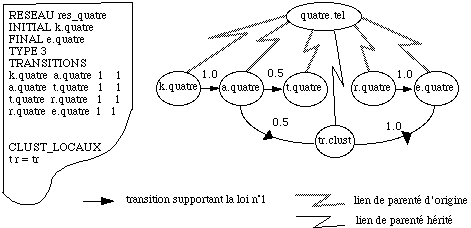
Figure 2 . 7 : Exemple d'un "Cluster" local sur le <tr> Toutes les transitions ayant pour état de départ une racine "t" et pour état d'arrivée une racine "r" sont remplacées par l'état "tr"
* rubrique CLUSTER :
Syntaxe : <racine d'état_1> <racine d'état_2> = <nom de réseau>
Toutes les transitions entre les états appartenant aux classes 1 et 2 sont supprimées ; un modèle déjà chargé en mémoire identifié par le nom de réseau est relié comme précédemment aux états adjacents des états extrémités de la transition supprimée ( Figure 2.8 ).
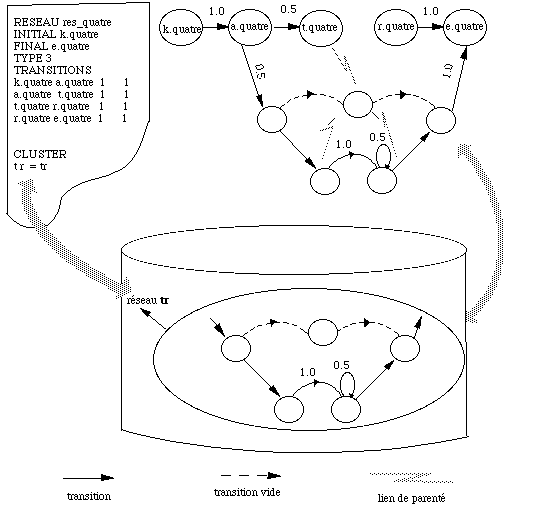
Figure 2 . 8 : Exemple d'un "Cluster" sur le <tr> avec un réseau déjà chargé en mémoire
Toutes les transitions ayant pour état de départ une racine "t" et pour état d'arrivée une racine "r" sont remplacées par le réseau "tr" en mémoire
* rubrique COART_LOCALES :
Syntaxe : <racine d'état_1>......<racine d'état_n> = <liste racines d'états coart.>
Toute suite d'états S appartenant à la suite de classes d'états 1 à n est doublée ; une chaîne de coarticulation, formée de transitions vides et d'états précisés dans la liste de coarticulation, est reliée aux états adjacents des extrémités de la suite S ( Figure 2.9 ).
Les états de la chaîne de coarticulation doivent ensuite être un à un rattachés à un sous-réseau local dans la définition d'un modèle élémentaire décrit ultérieurement dans le même fichier texte.
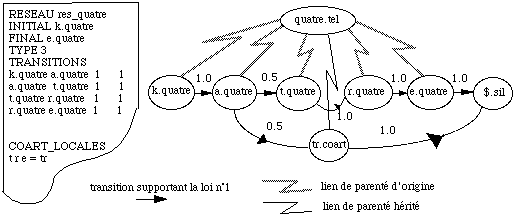
Figure 2 . 9 : Exemple de "coarticulation locale" sur le <tre> Toutes les suites d'états du réseau global ayant pour racines "t" , "r" et "e" sont doublées par une liaison avec l'état "tr.coart"
* rubrique COARTICULATION :
Syntaxe : <racine d'état_1> ......<racine d'état_n> = <nom de réseau >
Toutes les transitions entre les états appartenant aux classes 1 et 2 sont doublées ; un modèle déjà chargé en mémoire identifié par le nom de réseau est relié comme précédemment aux états adjacents des états extrémités de la transition supprimée ( Figure 2.10 ).
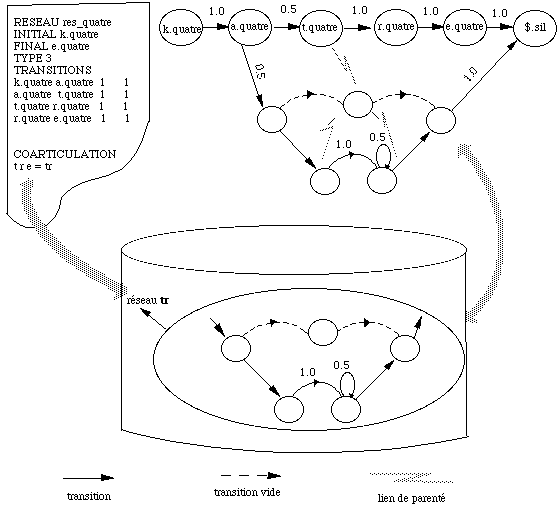
Figure 2 . 10 : Exemple de "coarticulation locale" sur le <tre> avec un réseau chargé en mémoire. Toutes les suites d'états du réseau global ayant pour racines "t" , "r" et "e" sont doublées par le réseau "tr". Les états de plus haut niveau du sous-réseau "tr" ont les mêmes pères que ceux de l'état "t.quatre"
Il s'établit entre l'état instancié, dans les cas "Liens", "Liaisons" ou "Copies" et le sous-réseau qui le remplace, un lien de parenté du type père/fils : tous les états appartenant au sous-réseau voient la racine de leur arbre généalogique augmentée d'un ancêtre ; réciproquement l'état substitué reconnaît comme ses fils tous les états du sous-réseau ( Figure 2.6 ). Dans le cas "Correspondances" un lien de parenté père/fils s'établit entre l'état substitué et les ancêtres de plus haut niveau dans le sous-réseau .
L'état qui est instancié, ainsi que les flots entrant et sortant de ses transitions, sont rendus inactifs. Les états inactifs sont les ancêtres des états du réseau actifs et sont liés entre eux par des relations inactives. Au cours de la compilation du Modèle de Markov, le réseau actif évolue avec les instanciations successives des sous-réseaux ( Figure 2.11 )
Chaque génération d'états forme ainsi un niveau du réseau global. Il est possible de connaître à tout instant dans le parcours d'un tel graphe les ancêtres et les descendants d'un état.
Les états doublant ou remplaçant une transition dans les cas "Cluster locaux" ou "Coarticulations locales" héritent des mêmes ancêtres que l'état de départ de la transition ( Figures 2.7, 2.9 ).
De la même manière, les sous-réseaux dans les cas "Clusters" ou "Coarticulation" voient la racine de leur arbre généalogique hériter des mêmes ancêtres que l'état de départ de la transition qu'ils doublent ou remplacent. ( Figures 2.8, 2.10 ).
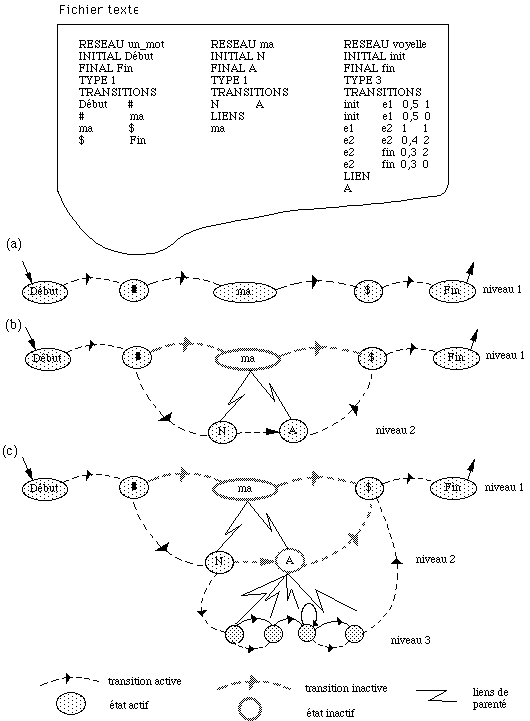
Figure 2 . 11 : Evolution du niveau actif : du modèle initial (a), après instanciation du sous-réseau phonétique "ma" (b), et enfin après création d'un 3ième niveau acoustique (c). ( Pour ne pas alourdir la figure, les extensions des états ne sont pas indiquées )
Lors d'une instanciation d'un état par un sous-réseau, les caractéristiques principales des transitions actives ( en particulier les informations relatives aux lois de probabilités ) rattachées à cet état sont réutilisées dans les transitions reliant le sous-réseau au modèle global.
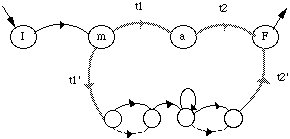
Figure 2 . 12 : les transitions reliant l'état "a" dans le niveau supérieur sont ré-utilisées pour instancier le sous-réseau des voyelles remplaçant "a". Les probabilités de transitions t1 et t1' sont rendues équiprobables, de plus t1 et t1' ont la même loi de probabilité. Il en est de même pour les transitions t2 et t2'.
Les transitions utilisées pour introduire des notions de Cluster et de Coarticulation sont mises en oeuvre de manière similaire.
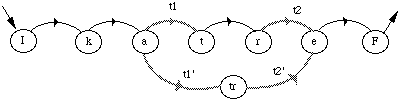
Figure 2 . 13 : Pour relier l'état-coarticulation "tr" les caractéristiques des transitions avec les états adjacents sont ré-utilisées. Les transitions t1 et t1' ont les mêmes caractéristiques ( mêmes lois de probabilité et probabilités de transitions rendues équiprobables), ainsi que les transitions t2 et t2'.
Le nombre de niveaux n'est pas limité. Le nombre des décompositions successives des états les uns par rapport aux autres n'est pas contrôlé ( un état peut avoir deux générations de descendants tandis qu'un autre au même niveau peut ne posséder qu'une génération de descendants par exemple ). Comme nous le verrons plus loin dans le paragraphe II.9. page 76, la gestion de ces niveaux ne pénalise pas le temps d'exécution de l'algorithme de Viterbi qui ne s'exécute que sur les transitions actives. Le concepteur du réseau doit cependant en tenir compte s'il désire naviguer dans une ou plusieurs génération(s) d'états ancêtres.
Il est bien connu que les réseaux organisés de manière arborescente permettent de minimiser la taille des modèles et augmente de manière significative la rapidité d'exécution des algorithmes de reconnaissance. En effet, les transitions à l'intérieur des mots sont mises en commun et les calculs les faisant intervenir voient leur coût diminuer.
Afin de modéliser un vocabulaire important, une fonction du compilateur permet de structurer automatiquement à partir d'un fichier texte un niveau intermédiaire sous forme arborescente. Si l'on dispose de deux niveaux, un niveau père et un niveau fils correspondant, la déclaration du réseau se réduit à la syntaxe suivante :
<état père_1> = <liste d'états fils_1>
<état père_2> = <liste d'états fils_2>
: :
: :
<état père_n> = <liste d'états fils_n>
Figure 2 . 14 : Syntaxe du fichier texte modélisant un niveau arborescent intermédiaire
Implicitement, les états pères sont encadrés par deux états représentant des silences Une construction automatique de leur modélisation MMC du type "gauche-droite" à partir de la liste des états fils est effectuée. Toutes les transitions utilisées sont vides.
Les états fils sont intégrés dans une structure d'arbre et ont un lien de parenté avec l'état père. Cette arborescence a pour racine un état initial suivi d'un état représentant un silence de début de mot. Toutes les feuilles de l'arbre sont reliées à un état représentant un silence de fin de mot. Les débuts communs entre les listes d'états fils sont factorisés en une seule branche. Les états appartenant à ces débuts communs ont plusieurs pères.
Figure 2.15 : Exemple de construction d'un niveau intermédiaire en arbre à partir d'un fichier texte d'un niveau supérieur de cinq états.
La construction de niveaux inférieurs décomposant les états du niveau intermédiaire peut être réalisée avec les rubriques précédentes.
Il peut être intéressant d'organiser les mots d'un vocabulaire en sous-dictionnaires. Les critères de classification des mots dans ces ensembles peuvent varier selon le degré de finesse attendu ou le type de résultat recherché.
Une fonction du compilateur permet d'organiser les états d'un modèle en sous-ensembles à partir d'un fichier texte. Celui-ci contient la liste des états composant ces sous-ensembles. Un sous-ensemble est identifié par son nom. La syntaxe du fichier texte est la suivante :
<nom ensemble 1> = <liste d'états éléments de l'ensemble 1>
<nom ensemble 2> = <liste d'états éléments de l'ensemble 2>
: :
: :
<nom ensemble n> = <liste d'états éléments de l'ensemble n>
Figure 2 . 16 : Syntaxe du fichier texte modélisant les ensembles d'états
Des états isolés -- n'étant reliés par aucune transition -- portant le nom des ensembles, sont implantés dans le réseau. Par leurs liens de parenté avec des états déjà existants du modèle, ils forment des ensembles d'états.
Ces états-ensembles se distinguent des autres états du graphe dans la mesure où ils ne font partie d'aucun niveau.
La figure 2.17 donne un exemple de représentation d'ensembles dans un réseau :
Figure 2 . 17 : Représentation d'ensembles dans un MMC
(a) schéma des ensembles à définir
(b) Fichier texte en entrée de la fonction de création d'ensembles
(c) Résultats du compilateur
Comme nous l'avons vu dans le chapitre II.2 page 47, les transitions sont associées à des lois d'émission. Qu'elles soient discrètes ou continues, ces lois font référence à des structures de calcul initialisées avec des valeurs par défaut.
Une quatrième famille de rubriques permet de modifier ces valeurs en les initialisant par les données de l'utilisateur. Il est possible d'initialiser soit la totalité des lois du réseau, soit seulement celles relatives à des transitions dont les états appartiennent à une classe d'états ancêtres.
Cinq types de rubriques sont définis :
* rubrique LOIS : elle détermine l'entrée du bloc de commandes d'initialisations des lois par l'utilisateur. Ce bloc doit être le dernier du fichier texte : en effet, on identifie les lois à initialiser par leur appartenance à des classes d'états décrites au chapitre II.2 page 46. Pour rester cohérent, l'utilisateur doit d'abord définir les classes d'états du réseau avant de les initialiser.
* rubrique TYPE : elle indique le type des lois soit D ( pour discrètes ), soit C ( pour continues ).
* rubrique LONGUEUR: elle précise le nombre de valeurs d'un vecteur d'observation.
Les rubriques suivantes sont répétées autant de fois qu'il y a d'initialisations :
* rubrique VALEURS : elle initialise les moyennes et variances pour une loi continue ou simplement les probabilités pour une loi discrète.
* rubrique RACINES : elle réfère par une liste de racines d'états les lois à atteindre par les valeurs d'initialisation précédentes. Toutes les lois se trouvant sur des transitions dont les ancêtres appartiennent à une liste de classes d'états donnée seront initialisées.
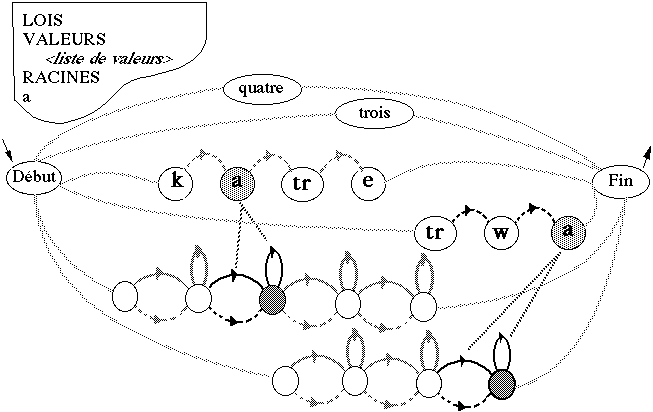
Figure 2 . 18 : Exemple d'initialisation des structures de lois par une liste de valeurs
Seules les transitions reliant les états ayant pour ancêtre un état de racine "a" sont initialisées.
Le mot clé "@" placé dans la rubrique RACINES déclenche l'initialisation de toutes les lois du réseau par les valeurs données précédemment dans la rubrique VALEURS.
L'ensemble des instructions détaillées dans les paragraphes précédents sont exécutées séquentiellement pour obtenir un réseau global ou compilé. Celui-ci est optimisé en supprimant en particulier les transitions vides inutiles et les états isolés ( pouvant être issus de l'application des "Clusters" ), dans le but de rendre l'exécution de l'algorithme de Viterbi plus performante.
* Exemple de suppression des transitions vides inutiles :
A)
B)
Figure 2 . 19 : Suppression d'une transition vide
La transition entre B.res et C.res de la Figure 2.19 A) ne peut supporter aucune observation et est unique à la sortie de B.res . Cette séquence d'états peut être simplifiée par le réseau de la Figure 2.19.B).
Le réseau est ainsi "allégé" d'un état et d'une transition tout en gardant strictement la même modélisation.
* Exemple de suppression d'états isolés :
A)
B)
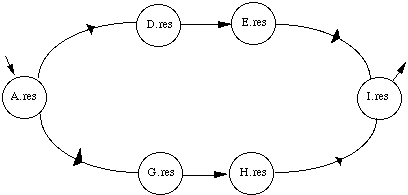
Figure 2 . 20 : Suppression des états isolés
Dans la Figure 2.20 A) l'état B.res n'est pas un état final et l'on ne peut en "partir". De même, l'état F.res n'est pas un état initial mais on ne peut l'atteindre. Nous considérons que ce sont des états isolés. Ceux-ci, ainsi que le flot de leurs transitions "entrantes" ou "sortantes" sont alors éliminés. Le réseau simplifié est montré dans la Figure 2.20 B).
Si nous voulons faire le parallèle avec l'exemple concret de la modélisation du mot "quatre", nous voyons dans la Figure 2.21 que les états isolés provenant des clusters ont disparus. De la même manière, les transitions vides servant de liens de construction entre les modèles acoustiques sont supprimées.
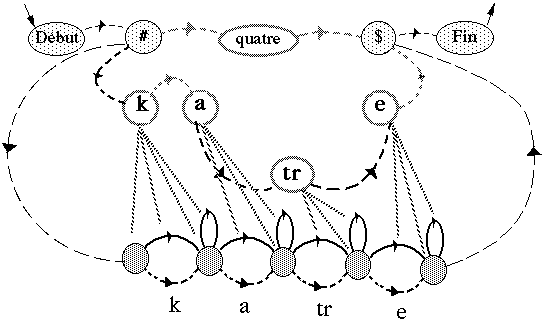
Figure 2 . 21 : Exemple d'optimisation sur le modèle du mot "quatre".
Afin de rendre plus réalistes les distributions probabilistes, une approche fréquemment employée de façon générale en modélisation d'objets physiques consiste à utiliser une somme ponérée de plusieurs lois de probabilité.
Une option du compilateur permet d'activer non pas ce traditionnel mélange de lois gaussiennes mais la construction d'un modèle dont on multiplie simplement le nombre de lois d'émissions initial. :
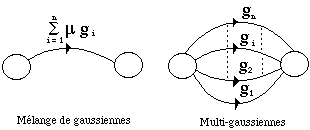
Figure 2 . 22 : Différence entre mélange et multi-gaussiennes
* rubrique NB_LOIS : indique le nombre de lois désiré.
Syntaxe : NB_LOIS : <nb_lois>
La description du réseau reste inchangée par rapport à celle présentée auparavant, et sa construction est dans une première phase inchangée. Ce réseau global initial obtenu, toutes les transitions non vides sont reprises et dupliquées en autant de fois que le paramètre <nb_lois> l'indique. Pour différencier les transitions ainsi créées entre deux états donnés, est attribué à chacune d'elles, un critère de loi ( numéro d'occurrence de copie de la loi compris entre 1 et <nb_lois>). Lorsque cette option est utilisée, une loi de probabilité est alors caractérisée par son numéro de loi et son critère de loi. Les probabilités de transitions sont adaptées de manière évidente.
Cette possibilité n'a pas pour but de rendre compte des traditionnels mélanges de lois gaussiennes ( rappelons qu'un mélange de lois gaussiennes est une loi de probabilité obtenue en sommant et pondérant correctement des lois gaussiennes ) : nous dupliquons des structures de lois pour éventuellement traduire un contexte spécifique (articulatoire par exemple), comme nous le verrons au cours de l'application AMIBE (chapitre III B, page 119).
Dans l'exemple donné ( figure 2.22.a ), un réseau élémentaire nommé "exemple" est décrit. Dans le fichier de commandes sont décrites 4 transitions : 2 vides et 2 autres générant la loi de probabilité de numéro 1. Les transitions vides restent inchangées. Les transitions générant la loi d'observation 1 sont dupliquées en trois exemplaires ( NB_LOIS = 3 ). Chaque duplicata de la loi porte un critère et les de probabilité transition sont mises à jour ( figure 2.22.b ).
Figure 2 . 23 : (a) Description réseau multi-gaussiennes
(b) Représentation en mémoire d'un réseau multi-gaussiennes
L'utilisateur peut initialiser les lois ainsi obtenues en précisant la classe d'état ancêtre comme précédemment, à la laquelle il faut adjoindre le critère de loi auquel elles se réfèrent, dans la rubrique RACINES.
LOIS
TYPE C
LONGUEUR 5
:
:
VALEURS
<moy 1> <moy 2> <moy 3> <moy 4> <moy 5>
<var 1> <var 2> <var 3> <var 4> <var 5>
RACINES
a 1
Figure 2 . 24 : Initialisations de lois multi-gaussiennes
Dans l'exemple donné figure 2.23, seules les lois de critère 1 ayant pour ancêtre des états de racine "a" sont initialisées.
La fonction d'apprentissage voit le nombre de ses paramètres augmenter d'une unité : si ce paramètre prend la valeur 0, l'apprentissage est réalisé en utilisant toutes les lois, quel que soit leur critère de loi. Dans ce cas, les probabilités de transitions seront réestimées. Si le paramètre est différent de 0, il est alors égal à un critère de loi : seules les lois portant le critère précisé seront prises en compte dans l'algorithme de Viterbi et seront réestimées. Les probabilités de transitions restent inchangées.
Le programme de reconnaissance utilisé pour le modèle de base reste compatible avec ce modèle multi-gaussiennes : l'algorithme de Viterbi continue à rechercher le chemin de probabilité maximale, mais dans un espace de recherche plus grand.
L'accroissement des paramètres dans un réseau peut aussi s'effectuer en augmentant le nombre de modèles représentant chaque unité à reconnaître ( cf § I.1.2.B.b.B page 17 ).
Une commande du compilateur permet de connecter parallèlement plusieurs réseaux déjà appris et chargés en mémoire afin de construire un seul réseau global.
Les états ancêtres ayant les mêmes noms fusionnent entre eux et mettent en commun leurs descendants. Ainsi, pour deux réseaux connectés identiques, chaque état ancêtre a deux modélisations au niveau actif. Les modélisations au niveau actif n'ont pas nécessairement la même topologie.
Dans l'exemple qui suit, nous considérons deux réseaux identiques modélisant chacun le mot isolé "ma". On peut supposer qu'ils ont été appris séparément et qu'ils possèdent chacun leurs lois d'observations et probabilités de transitions propres. Il peut s'agir du cas classique d'une modélisation séparée pour les locuteurs hommes et femmes.
Nous voyons dans la figure 2.24 que les unités phonétiques et les unités au niveau mot ont été fusionnées. Elles ont pour descendants deux modélisations au niveau acoustique. Nous avons utilisé cette fonction dans le cas classique d'une bi-modélisation Homme/Femme, mais le nombre des modèles par unité à reconnaître n'est pas figé.
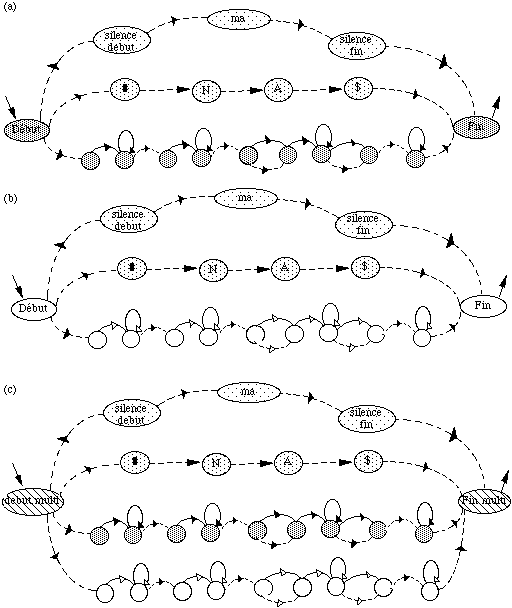
Figure 2 . 25 : Réseau "ma" appris avec les locuteurs hommes (a)
Réseau "ma" appris avec les locuteurs femmes (b)
Ces deux réseaux sont passés en paramètres de la fonction "multi" qui crée en mémoire le réseau multi-modèles hommes/femmes (c)
Le réseau construit est compatible avec les structures existantes et n'a pas besoin d'être adapté aux fonctionnalités des réseaux classiques.
Les algorithmes d'apprentissage et de reconnaissance sont adaptés aux structures des réseaux que nous avons présentés. Ceux-ci sont fondés sur l'algorithme de Viterbi dont le principe présenté pages 22 et 24 n'est pas modifié. Nous proposons un aperçu de son adaptation à cette structure de données.
L'algorithme de Viterbi tel que nous l'avons mis en oeuvre s'exécute dans le niveau actif du réseau. Rappelons que les émissions se font sur les transitions non vides.
L'environnement de notre structure de données et en particulier l'introduction des transitions vides, nous ont conduit à modifier légèrement la programmation de l'algorithme de Viterbi telle qu'elle est présentée au Chapitre I pages 22 et 24 ( Cf Annexe A2 ).
Ces modifications sont liées au fait que les transitions vides peuvent atteindre des états du réseau sans être alignées avec des observations. Pour un état et une observation donnés, tous les états successeurs reliés avec des transitions vides auront une probabilité non nulle d'être atteints pour cette même observation.
En particulier, en considérant les états pouvant être atteints à partir de ces transitions vides, l'ensemble des probabilités de transitions initiales se voit modifié.
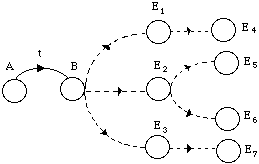
Figure 2 . 26 : Exemple de propagation des transitions vides
Si l'on peut émettre à l'observation "t", la transition entre A et B on peut atteindre avec une probabilité non nulle tous les états Ei avec la même observation "t".
L'algorithme d'apprentissage est essentiellement fondé sur l'algorithme de Viterbi.
Le choix de cet algorithme lors de l'apprentissage repose sur deux observations :
-- pour un pré-traitement segmental, l'algorithme de Viterbi est quasiment équivalent à celui de Baum-Welch car il n'y pas pratiquement qu'un seul chemin ayant une probabilité non nulle. Pour un tel pré-traitement et une modélisation acoustique relativement simple, semblable à celle utilisée dans cette étude, l'algorithme d'apprentissage utilisant le meilleur chemin est suffisant ( les taux de reconnaissance diffèrent de moins de 0,5 % ) [André-Obrecht 93, page 115].
-- il est plus simple à mettre en oeuvre
Lors de la phase d'apprentissage, nous devons restreindre l'espace de recherche, à l'intérieur du modèle global, aux chemins correspondant à la modélisation des observations traitées. Ce repérage s'effectue à l'aide d'une entête (REPERES) placée dans les fichiers d'apprentissage, indiquant les noms des états ancêtres auxquels correspondent les observations qu'ils contiennent. Tous les états faisant partie de leur descendance forment un sous-réseau. La restriction de l'espace de recherche est d'autant spécialisée que les états contenus dans l'entête sont de bas niveau.
L'algorithme de Viterbi s'effectue dans ce sous-réseau. Le sous-réseau est isolé du modèle global en utilisant les liens de parenté entre les générations d'états. Ainsi, le coût de l'apprentissage dépend seulement de la taille du sous-réseau sélectionné ( de la longueur du mot dans le cas d'un modèle pour mots isolés ) et non de la taille du réseau global.
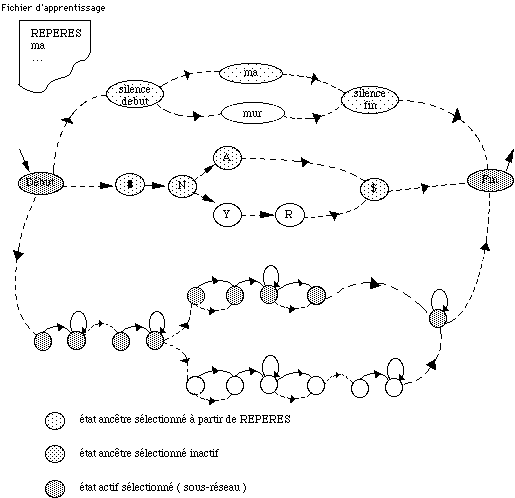
Figure 2 . 27 : Sélection du sous-réseau pour l'apprentissage du mot "ma"
Il est possible de réaliser un apprentissage classique ou un apprentissage avec une variance seuillée. La nouvelle valeur de la variance d'un coefficient d'une loi ne sera prise en compte que si elle ne dépasse pas un seuil donné par rapport à une valeur globale passée en paramètre. Cette valeur globale peut être obtenue en effectuant la moyenne et la variance des vecteurs d'observations de tous les fichiers d'apprentissage.
Les fichiers de reconnaissance possèdent une entête REPERES contenant le ou les unité(s) à reconnaître. Ces unités dépendent du niveau des noms d'états qui y sont décrits.
Cette rubrique est uniquement utilisée pour valider la reconnaissance des prononciations des fichiers.
Dans cette phase, l'algorithme de Viterbi s'effectue dans tout le réseau actif et produit le meilleur chemin, sa trace est traditionnellement donnée au niveau acoustique. Mais le mot ainsi reconnu peut être plus facilement identifié si l'on connait le nom de ses états ancêtres : en général, un chemin dans le niveau acoustique est trop détaillé pour y lire clairement la graphie du mot reconnu.
En utilisant les liens de parenté dans le sens "fils de", nous obtenons les noms des états des générations précédentes. En remontant suffisamment loin dans "l'arbre généalogique" des états, on peut produire plusieurs suites d'états caractéristiques à un mot ( Figure 2. 26 ).
Prenons par exemple un modèle possédant trois niveaux : un niveau orthographique où les états représentent la graphie des mots, un niveau phonétique où les noms d'états désignent des phonèmes et un niveau acoustique. Le chemin optimal est trouvé dans le niveau acoustique. Les liens de parenté des états du chemin réfèrent à des états du niveau phonétique, donc à la décomposition en phonèmes de la solution trouvée. Les pères des états du niveau phonétique désignent un état au niveau orthographique : son nom donne la graphie du mot reconnu.
Comme autre exemple d'utilisation, nous pouvons citer l'emploi du nom des états phonétiques pour réaliser un algorithme de reconnaissance de type Consonne/Voyelle.
La rubrique REPERES désigne un état ancêtre du modèle. La comparaison entre cet état et l'état ancêtre du mot obtenu sur le chemin optimal, donne le résultat de la reconnaissance.
L'utilisation des noms et états et de leurs liens de parenté nous dispense d'avoir deux modules : un de recherche du chemin optimal et un module de décodage. On peut discuter le fait que cette modélisation entraîne peut-être une trop forte dépendance entre les modèles et les fichiers d'observations étant donné que le modèle contient la solution.
Le compilateur offre la possibilité d'effectuer une reconnaissance en utilisant des ensembles :
-- La recherche du chemin optimal C s'exécute par l'algorithme de Viterbi.
-- Le mot attendu, indiqué dans la rubrique REPERES du fichier des observations est un élément de plusieurs sous-ensembles SEi .
Considérons SE = " SEi . Nous appelons SE "l'ensemble de référence" du mot attendu.
-- Le chemin C est élément des sous-ensembles SE'j .
Considérons SE' = " SE'j . Nous appelons SE' "l'ensemble de référence" du mot reconnu.
-- la reconnaissance du chemin est validée si l'ensemble de référence du mot attendu et l'ensemble de référence du mot reconnu ne sont pas disjoints.
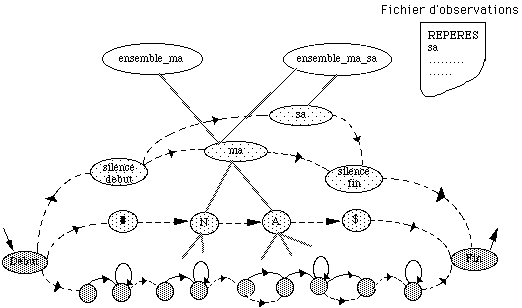
Figure 2 . 28 : Exemple de reconnaissance ensembliste
Dans cet exemple le mot à reconnaître est "sa". L'état "sa" est un élément de l'état-ensemble "ensemble_ma_sa". Ce dernier est l'ensemble de référence du mot attendu.
A l'aide des liens de parenté des états du chemin optimal ( à l'exception des états initiaux, finaux et silences ) , nous obtenons l'ensemble de référence du mot reconnu : { "ensemble_ma" , "ensemble_ma_sa" } .
L'ensemble de référence du mot attendu et celui du mot reconnu ont un sous-ensemble commun "ensemble_ma_sa" : le chemin optimal est donc validé.
Il est à noter que la définition d'ensembles dans un modèle change la signification des taux d'erreurs. Prenons par exemple un modèle initial dont les unités à reconnaître sont des phonèmes. Sur ce modèle sont créés des ensembles regroupant des mots en suites de "Consonne/Voyelle". La reconnaissance ensembliste ne donne plus les taux de reconnaissance en terme de phonèmes ( unité initiale ) mais en terme de suites "Consonne/Voyelle".
Nous tenons à faire remarquer que la reconnaissance ensembliste présentée ici n'est qu'une proposition d'utilisation de ce que nous avons appelé les états-ensembles. On peut noter que si un mot appartient à tous les ensembles on obtiendra immanquablement un taux de reconnaissance de 100%, taux flatteur en soit mais ne reflètant peut-être pas la réalité. Il faut donc apporter un soin attentif à la construction des ensembles.
On peut toutefois envisager d'augmenter la finesse de la reconnaissance en ne validant un mot que si son ensemble de référence contient en particulier le mot attendu.
Notre compilateur est librement inspiré de PHIL90 : il se distingue essentiellement dans l'apport d'un aspect multi-niveaux dans les réseaux générés et une certaine souplesse dans leur description. Notre but était de proposer un ensemble de fonctions manipulant des réseaux adaptés à nos propres travaux de recherche en RAP, mais nous espérons que son cadre d'utilisation se généralisera.
La gestion des multi-niveaux alourdit considérablement la quantité d'informations à stocker par rapport à un réseau n'ayant que l'équivalent de notre niveau actif.
Il faut toutefois faire remarquer qu'il s'agit d'un outil expérimental au service de la recherche ne bénéficiant pas d'une longue expérience.
Le compilateur donne en résultat une structure de réseau contenant les adresses des états initiaux , des états finaux, des états actifs, des états ancêtres inactifs et de la liste des structures de lois du modèle.
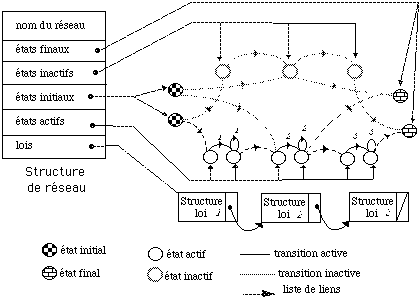
Figure 2 . 29 : Structure d'identificateur de réseau
La spécification de l'ensemble des états initiaux permet d'accéder directement aux entrées du réseau. De la même manière, nous pouvons déterminer si un chemin trouvé par l'algorithme de Viterbi arrive dans un état final grâce à l'identification de l'ensemble des états finaux.
Chaque état du réseau est créé isolément en mémoire vive par une structure contenant les états suivants dans le réseau ( transitions avant ), ses états prédécesseurs ( retours arrières ), ses états ancêtres directs ( liste des pères ) et ses états descendants ( liste des fils ). On lui adjoint l'indice qui lui est attaché dans la table de calcul pour la recherche du chemin optimal dans l'algorithme de Viterbi.
Les états peuvent être atteints dans le parcours d'un graphe à partir des états initiaux dans le sens "horizontal" avec les transitions et/ou dans le sens "vertical" en utilisant les liens de parenté. On peut également accéder directement à tous les états du réseau ( actifs ou inactifs ) à partir des listes d'états contenant leur nom et leur adresse d'implantation en mémoire. Ces listes sont organisées de deux manières : une liste linéaire pour les balayages séquentiels et une liste en arbre binaire pour les recherches d'états particuliers.
Á la différence des outils classiques de compilation présentés dans l'introduction, il est possible d'atteindre rapidement tout état de n'importe quel niveau, qu'il soit actif ou inactif.
Dans le même esprit, les émissions se faisant sur les transitions, un accès direct sur les structure de lois est réalisé en incluant son implantation en mémoire dans la structure de chacune des transitions qui la supporte.
Cette structure offre divers avantages :
-- La navigation dans un tel réseau est optimisée en minimisant les procédures de balayage de listes dans le but de ne pas pénaliser le coût d'exécution des programmes de reconnaissance et d'apprentissage utilisant l'algorithme de Viterbi.
-- La représentation du réseau en mémoire est très proche de sa représentation graphique sur le papier : à partir du moment où la conception graphique d'une modification est déterminée elle devient réalisable dans la structure du réseau.
-- Enfin, ce type de réseau est très modulaire et peut permettre de modéliser des réseaux plus complexes ( modélisations multi-niveaux semi-markoviennes, Cf Chapitre IV page 155 ).
La reconnaissance de la parole dans le cadre de très grands vocabulaires soulève des problèmes qui n'ont pas actuellement de solutions définitives. Pour une approche statistique, plus la taille du vocabulaire augmente, plus il devient difficile de créer un système de reconnaissance qui trouve réellement la solution de probabilité maximale tout en ne pénalisant pas le temps de comparaison de la prononciation recherchée parmi celles référencées dans le modèle.
L'introduction de contraintes sur la syntaxe du langage afin d'accroître la pertinence des informations utilisées tout en conservant un coût de calcul raisonnable, ou l'intégration d'informations supra-segmentales ( prosodie, durée ... ) afin d'améliorer la recherche de la bonne solution ne sont pas encore bien maîtrisées [Gauvain 94].
L'extrême variabilité des prononciations, dues entre autre à l'origine géographique du locuteur, à son état de fatigue, à son sexe... s'accroît avec les conditions d'enregistrement utilisées ( déformation du canal, environnement sonore...). Rendre le moins vulnérable possible les systèmes de reconnaissance à ces problèmes n'a pas de solution évidente. Il est difficile d'extraire du signal des informations pertinentes et robustes représentant fidèlement les prononciations.
Le choix de l'unité acoustique élémentaire à partir de laquelle les mots sont construits reste délicat. Elle doit être suffisamment "générale" pour factoriser les représentations acoustiques des mots afin d'éviter un apprentissage important et elle doit être assez détaillée pour représenter avec un degré de précision satisfaisant les événements acoustiques qui lui sont caractéristiques.
Enfin, l'accès lexical dans le cadre de très grands vocabulaires, est un problème important ; beaucoup de travaux antérieurs ont été consacrés à cette question cruciale. Lorsque la taille du vocabulaire augmente ( > 1000 mots ), il devient utile d'optimiser cet accès. Plusieurs tendances sont actuellement observées.
La plupart d'entre elles reposent
-- sur une organisation du lexique sous forme arborescente [Steinbiss, 93] ou sous forme de règles de grammaire [Minami, 93],
-- sur des algorithmes Forward-Backward [Kenny, 93], [Ljolje, 92].
Ces deux approches peuvent d'ailleurs coopérer [Mérialdo 88].
Dans le cadre de l'approche statistique classique de la reconnaissance grand vocabulaire, le lexique est formé à partir d'unités de parole fondamentales modélisées acoustiquement. En général, aucun lien n'est établi entre les mesures acoustiques du signal et les unités acoustiques du modèle. Celui-ci est entièrement appris à partir d'un ensemble fini de prononciations [Gauvain, 94].
Nous proposons dans le cadre de nos recherches, d'examiner le problème de l'accès lexical sous cet angle : rechercher un lien entre l'acoustique et les unités élémentaires afin de définir un filtre lexical en plusieurs passes. Notre motivation repose sur trois observations :
-- d'un point de vue acoustique, il est classique de répertorier les sons de la parole en classes majeures. Chaque classe peut se caractériser par des connaissances acoustiques telles que : des connaissances spectrales, des connaissances articulatoires sur l'évolution temporelle de paramètres tels que les formants ou les énergies, et enfin des connaissances contextuelles prenant en compte les parties voisines du signal [Calliope, 89] comme nous le détaillerons ultérieurement.
-- d'un point de vue traitement du signal, il existe des outils performants permettant l'accès à une segmentation statistique robuste du signal [Svendson, 94] [André-Obrecht,94]
-- des lexiques performants permettent une description multi-formes des mots. Entre autres, il est possible d'y obtenir les représentations en classes majeures des mots du vocabulaire. On peut citer le lexique BDLEX comportant pour chaque mot plusieurs codages selon différents ensembles de classes majeures [Pérennou, 88].
La combinaison de ces remarques conduit à penser qu'il est possible d'envisager deux étapes dans un système de reconnaissance :
-- la première consiste à relier classes majeures et segmentation : en utilisant la représentation en classes majeures des mots et une segmentation a priori, l'information acoustique est réduite. Dans cette première étape de reconnaissance, un filtrage lexical est appliqué pour sélectionner une cohorte de classes majeures que nous appelons sous-dictionnaire.
-- une deuxième phase poursuit la recherche parmi les mots du sous-dictionnaire en utilisant des unités plus fines telles que les allophones, les pseudo-diphones...
Dans le cadre de la reconnaissance de mots isolés, nous proposons un système fondé sur cette approche décrit à l'aide de trois modules :
-- le module de pré-traitement acoustique :
celui-ci est fondé sur une méthode de segmentation ; cette approche est originale dans le sens où les modules de DAP et de RAP classiques ne se servent pas de la segmentation comme apport d'information a priori.
-- un filtrage lexical :
il utilise une représentation en classes majeures des mots du vocabulaire pour modéliser le lexique en une réunion de sous-dictionnaires. Ce filtrage a pour but de sélectionner un seul sous-dictionnaire.
-- un module de reconnaissance :
les mots du sous-dictionnaire sont modélisés avec leur représentation en pseudo-diphones, unités plus fines que les classes majeures.
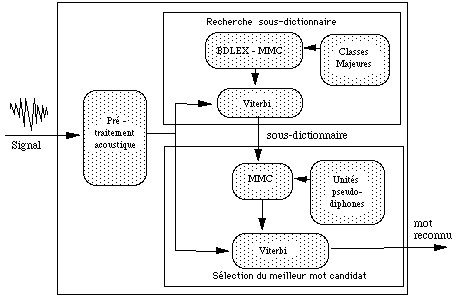
Figure 3A . 1 : Schéma général du système de reconnaissance
L'originalité de ce système repose sur deux points :
-- un pré-traitement acoustique sans connaissance a priori du signal,
-- une phase de reconnaissance en deux passes avec construction temporaire d'un MMC
Dans chacun de ces modules, nous utilisons une approche statistique : le pré-traitement est fondé sur un système probabiliste, le filtrage et la reconnaissance font appel à des modèles de Markov cachés classiques.
Le module de pré-traitement acoustique repose sur une méthode de segmentation fondée sur un test de décision statistique, la méthode de divergence Forward-Backward [André-Obrecht, 88].
Il se compose de deux principales étapes :
-- un premier module de segmentation statistique a priori,
-- un second module d'extraction des paramètres acoustiques sur chaque segment.
Cette méthode s'appuie sur une étude statistique du signal.
Comme nous l'avons vu au chapitre I, on considère que le signal ( yn ) peut être décrit par une suite de zones quasi-stationnaires, caractérisées par un modèle auto-régressif gaussien ( L.P.C ) ( cf paragraphe I.1.1.D page 11 ) :
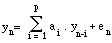
Figure 3A.2 : Formule L.P.C.
en est un bruit blanc gaussien centré de variance σ
p est l'ordre du modèle
Chaque modèle est paramétré par un vecteur ( AT, σ ) = ( a1 .. ap , σ) et est noté Mi ( Ai, σi ).
Le principe de la segmentation est la recherche de changement dans les paramètres du modèle. La méthode est caractérisée par :
- une évaluation des paramètres A et σ pour chaque échantillon,
- l'application d'un test statistique de décision: la divergence de Kullback,
- une détection séquentielle des ruptures.
Le test de divergence s'appuie sur la mesure de la distance au sens statistique du terme, entre deux modèles M0 et M1 (Figure 3A . 3 ) [Basseville, 83].
* M0 est un modèle à long terme estimé par un algorithme de Burg sur une fenêtre croissante,
* M1 est un modèle à court terme estimé par une méthode d'autocorrélation sur une fenêtre glissante.
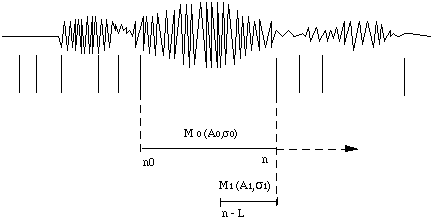
Figure 3A . 3 : Localisation des fenêtres d'estimation des modèles M0 et M1 à l'instant n ; l'instant n0 correspond à la dernière frontière validée.
Ces modèles sont initialisés après chaque détection de rupture sur une fenêtre de longueur L. La divergence des modèles est quantifiée par la somme cumulée :
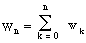
des distances statistiques wk calculées à chaque instant k par :
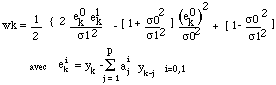
Une rupture est détectée en comparant les variations de la somme cumulée Wn à un seuil (Figure 3A.4 ) . Si la distance entre les modèles est inférieure au seuil, on se trouve toujours sur le même segment sinon une rupture est détectée.
La détection se fait grâce à la règle de
Page-Hinkley, en comparant les variations de la somme cumulée
biaisée
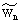 par un biais d à un seuil λ :
par un biais d à un seuil λ :
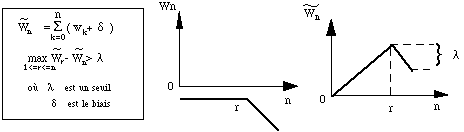
Figure 3A . 4 : Détection d'une rupture
Le résultat de cette segmentation est de nature infra-phonémique. Elle permet de détecter les zones stables et les zones transitoires des sons.
L'expérimentation a montré des omissions systématiques comme la transition entre un segment vocalique et un segment consonantique voisé : / ∂m /. Afin d'y remédier, des tests ont été mis en oeuvre dans une version Forward-Backward [André-Obrecht, 93].
Elle consiste à traiter le signal dans le sens rétrograde dès qu'une "omission est soupçonnée".
Principe :
Soient Lmin = durée minimale de deux segments adjacents
r = instant de localisation d'une rupture
nd = l'instant où l'on a détecté la dernière rupture r
La procédure forward traite le signal dans le sens chronologique. Quand une rupture est détectée à l'instant nd et localisée au temps r, on effectue le test suivant :
Si le segment courant est voisé et si sa longueur est supérieure à Lmin ( longueur minimale de deux sons voisés ), alors la procédure backward est déclenchée.
La procédure backward parcourt le signal dans le sens rétrograde : si aucune nouvelle frontière n'est détectée avant r, alors on recommence la procédure forward au temps r. Sinon, la procédure forward reprend à la nouvelle frontière détectée n0.
Cet algorithme forward-backward a prouvé son efficacité. On peut néanmoins lui adjoindre un module pilote pouvant effectuer le même travail de segmentation, mais sur le signal filtré, par un filtre passe-haut. Ceci afin de mieux prendre en compte les hautes fréquences.
Les unités obtenues peuvent être regroupées en 3 classes :
-- les segments quasi-stationnaires qui correspondent à la partie stable d'un phonème lorsqu'elle existe,
-- les segments transitoires,
-- les segments courts ( environ 20 ms ) où deux sons se superposent.
Signalons deux cas particuliers :
-- les occlusives sourdes qui contiennent 3 segments : la closion, le silence et l'explosion.
-- les voyelles nasales qui contiennent au minimum 2 segments correspondant à la partie orale et la partie nasale, plus des segments transitoires entre ces deux zones dans le cas de voyelles longues ( comme /ã/ par exemple ) .
On peut d'ores et déjà voir que cette segmentation paraît adéquate à la modélisation en pseudo-diphones, les deux faisant référence aux parties stables et transitoires des sons.
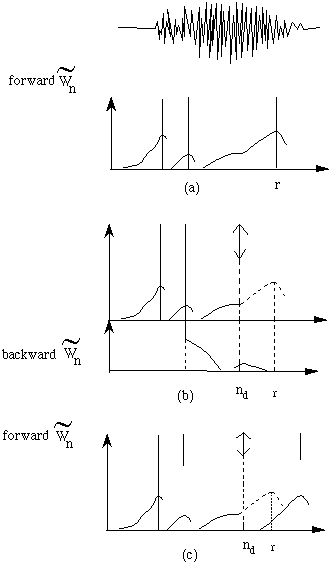
Figure 3A.5 : description de la méthode de divergence Forward-Backward : après avoir détecté une rupture au temps r (a) et si r > L min, le signal est parcouru dans le sens rétrograde (b). Si une nouvelle rupture est détectée au temps n0, le signal est reparcouru dans le sens avant à partir du temps n0; sinon, la recherche d'autres ruptures dans le sens avant reprend au temps r.
Les paramètres choisis pour caractériser les segments appartiennent au domaine cepstral. Ces paramètres sont extraits sans connaissance a priori sur les segments : ils seront calculés de la même manière qu'il s'agisse d'un segment appartenant à une zone consonantique, vocalique, transitoire ou non.
Une fenêtre de 10, 20 ou 40 ms, suivant la longueur du segment, est centrée sur celui-ci. Après pré-accentuation et transformée de Fourier ( cf paragraphe I.1.1.D page 11), 8 coefficients cepstraux ( MFCC ), l'énergie E ainsi que la durée du segment T sont calculés pour quantifier l'information contenue dans le segment. Les dérivées des 8 coefficients cepstraux et de l'énergie sont calculées à partir d'une régression de ces mêmes paramètres sur 5 fenêtres d'analyse de 20 ms chacune, décalées de 10 ms ( soit 60 ms ). Finalement, à chaque segment correspond une observation vectorielle de 19 coordonnées :
* 8 MFCC
* E
* 8 Δ MFCC
* Δ E
* T
Le filtrage lexical est effectué par un MMC permanent dont les unités à reconnaître représentent des classes majeures fondées sur celles du lexique BDLEX. Après avoir présenté le lexique BDLEX nous donnons une description des classes majeures.
Les connaissances de base sont empruntées au lexique BDLEX version 1. Celui-ci contient 23.000 entrées lexicales, chacune d'elles étant accompagnée d'une description linguistique centrée sur les niveaux morpho-syntaxique et phonologique du français [Pérennou, 88].
Les raisons ayant motivé notre choix en faveur du lexique BDLEX sont doubles :
-- d'une part ce lexique est couplé à une composante phonologique permanente
-- d'autre part des outils performants ont été développés et permettent d'envisager l'extension d'un système de RAP de mots isolés à un système de RAP en parole continue.
Nous ne développons ci-après que la première composante dans la mesure où nous n'avons exploité que cet aspect de BDLEX.
A partir du lexique et en utilisant un ensemble de règles flexionnelles, on obtient un corpus de 270.000 formes fléchies. Ces règles sont fondées sur l'association racine/désinence où la racine est la partie caractéristique du mot et la désinence celle qui porte les marques flexionnelles ( pluriel, féminin, temps, personne, mode ) [Ferrané, 91].
La composante phonologique de BDLEX est un modèle phonologique de type markovien, pouvant s'intégrer dans des modèles tels que les MMC. Il peut être aussi efficace pour des systèmes à base de connaissances [Nguyen, 93], [Smaili, 92].
Ce modèle fondé sur les gpm ( groupes à prononciations multiples ) et les gpc ( groupes phonologiques contextuels ), permet d'engendrer des modèles aléatoires pouvant se représenter sous forme de réseaux markoviens.
Les gpc rendent compte des variantes de prononciations dues au contexte du mot dans la phrase. Par exemple, le mot "membre" est représenté par mã<~br(TM)> au niveau phonologique. Le gpc <~br(TM)> engendre le gpm (~br(TM)>) devant une pause ou le gpm (~br(TM)) devant une consonne ou [br] devant une voyelle ou une semi-voyelle Les gpm apparaissent au niveau phonotypique. A ce niveau, les gpc sont transformés en gpm d'après leur contexte. La représentation obtenue est un modèle probabiliste attachant à chaque prononciation une probabilité ou simplement une plausibilité. L'apprentissage des modèles des gpm peut s'effectuer par leurs fréquences d'apparitions dans des corpus et fait actuellement l'objet de la thèse d'Alix de Ginestel à l'IRIT.
Les gpm rendent compte de toutes les variantes possibles de prononciations d'un ou plusieurs phonèmes contigu pour un groupe de locuteurs donné. Ils permettent de traduire des phénomènes phonologiques comme la chute du schwa ou les assimilations ...
Ainsi les gpm peuvent être probabilisés comme ci-dessous :
(~br(TM)) --> brÆ 0,6 , b 0,3 , m 0,1
Le gpm (~br(TM)) se réalise en brÆ dans 60% des cas, en b dans 30% et en m dans 10% ; en sachant que Æ est un gpm trivial qui peut être lui-même décomposé en plusieurs réalisations suivant le degré de finesse que l'on désire obtenir [de Ginestel-Mailland, 94].
Ainsi définis, les gpm peuvent être associés de diverses manières à des réseaux probabilistes, en particulier à des MMC.
L'apprentissage de ces gpm fait appel à une variante du système d'alignement VERIPHONE décrit dans [Pérennou, 89]. Il prend en entrée une chaîne de gpm qui est la transcription phonotypique issue de la composante phonologique et une chaîne qui est la transcription phonétique auditive. Le système d'alignement assigne à chaque gpm une suite d'unités phonétiques. Il produit en sortie l'énoncé aligné [de Ginestel-Mailland, 93a], [de Ginestel-Mailland, 93b].
Les règles initiales sont données par un expert. Celles-ci sont ajustées et adaptées par le module d'apprentissage. Les fréquences associées à chaque réalisation de gpm sont incrémentées à chacune de leurs apparitions. On peut alors procéder par estimation comme dans le cas des MMC.
Figure 3A. 6 : Apprentissage des règles phonologiques
Dans le cadre de notre application où nous nous intéressons seulement aux mots isolés, l'application des gpc, qui tiennent compte des variations d'élocution d'un mot selon son contexte, sera réduite au seul contexte "fin de phrase". Dans ce gpc les mots ne sont suivis par aucun autre. Nous n'avons donc pas à prendre en compte d'éventuelle coarticulation en fin de mot, ce qui correspond à notre contexte d'application en mots isolés. Nous ne prendrons en compte que les gpm correspondants.
Nous envisageons deux types de représentations des entrées lexicales de BDLEX : les classes majeures et les unités plus fines tenant compte des contextes des phonèmes.
Les classes majeures regroupent des phonèmes ayant le même comportement acoustique. Le choix du nombre des phonèmes composant ces classes majeures est critique pour un système de reconnaissance devant produire des cohortes[1] de phonèmes comme résultat d'un pré-filtre lexical. Le nombre de classes ne doit pas être trop élevé pour minimiser le coût du pré-codage, ni trop faible pour rester fiable.
* A partir de la représentation en fréquences ( spectrogramme ) , les phonèmes du français peuvent être regroupés en sept classes [Calliope, 89] :
Voyelle orales a , ε, e , oe , (TM) , i , o , u , y Voyelles nasales ã ,õ, É , Consonnes occlusives b, d , g , p , t , k Consonnes fricatives f , s , ∫, v , Z , Ô Consonnes nasales m , n, η, Ì Consonnes liquides l , R Semi-voyelles Á, ., jTableau 3A. 7 : Classes Majeures du Calliope
* M. El-Bèze propose des classes majeures en prenant la syllabe comme unité de base. La syllabe a pour intérêt d'avoir une structure bien définie et d'intégrer les coarticulations. Parmi les six classifications expérimentées, les plus performantes sont celles qui privilégient les voyelles. Celles-ci reposent sur la combinaison de dix voyelles ( a, u, ε, e, i, y, o, ã ,õ, É ) avec les consonnes et semi-voyelles pouvant suivre ou précéder ces voyelles. On trouve ainsi 237 suites possibles. Elles sont réparties en quatre classes consonantiques :
-- Liquides, semi-voyelles,
-- Occlusives,
-- Nasales,
-- Fricatives,
La première répartition est issue de l'observation manuelle des spectres, la seconde d'une classification automatique à partir d'un indice de similarité entre des suites de modèles de Markov. [El-Bèze,87]
* Le lexique BDLEX contient des classes d'équivalence afin de sélectionner des cohortes lexicales. On peut y trouver, à titre d'exemple divers types de codages notés selon [Pérennou, 86] :
-- un codage à deux classes X et V correspondant aux Consonnes et Voyelles
-- un codage en cinq classes Q ( Occlusives ) , F ( Fricatives ) , LN ( Liquides et Nasales ), V ( Voyelles) , SV( Semi-Voyelles )
-- un codage en onze classes Q( p ,t ,k ) , O ( b, d, g ), Z ( v , Z , Ô ) , S (f , s , ∫) , L (r , l) , N (m , n, η) , VF( i , u, y) , VM (ε, e,oe , (TM)) , VO (a) VN ( ã ,õ, É ), SV ( j, Á, . ).
* En s'inspirant de ces classifications, nous avons créé nos propres classes majeures :
Les voyelles ayant un poids considérable dans la reconnaissance des mots, chacune d'elle à sa classe spécifique.
Pour conserver un certain degré de finesse les occlusives et les fricatives ont été séparées selon leur caractère voisé et non voisé.
Les plosives se caractérisent par une suite d'événements acoustiques distincts : le silence et l'explosion. Nous avons modélisé ces événements dans les classes majeures en séparant le silence et l'explosion. Ainsi, pour la plosive [t], on aura la suite de classes majeures T# et T.
En outre, les phénomènes de coarticulation entre les classes des plosives et celles des liquides sont particuliers et font l'objet de deux classes majeures TR et TL .
A a Plosive voisée D b, d, g
E ε, Plosive DR dr
e voisée
e oe , (TM) liquide
Voyelles I i Plosives T p ,t ,k
O o silence T#
plosive
U u Plosives TR tr
Y y liquides TL pl
Voyelles % ã ,õ Plosive TR$ tr
liquide
nasales IN É fin de mot ( fin de mot
)
Voyelles %$ ã ,õ (fin Liquide fin R$ r ( fin de
mot) mot mot )
nasales fin IN$ É (fin mot) Fricatives S f , s ,
mot ∫
Nasales N m , n, Z v , Z , Ô
η, Ì
J j Liquides R R
Semi-voyelles W . L l
y Á Silences $ ( fin de mot
)
e final efin schwa # (début de
mot)
aspiration + h aspiré
Tableau
3A . 8: Tableau récapitulatif des classes majeures
Par exemple le mot ma sera représenté par la suite de classes majeures : N . A . Le MMC dont les unités de base sont les classes majeures le modélisant sera défini ainsi :
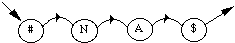
Figure 3A . 9 : Modèle de Markov Caché en Classes Majeures représentant "ma"
Un MMC principal est construit à partir du lexique et des classes majeures définies précédemment.
Il est composé de trois niveaux :
-- Le niveau orthographique : chaque état du MMC représente la graphie d'un mot. Notre système travaillant dans un contexte de mots isolés, les mots seront encadrés de silences.
Par exemple pour les mots "ma" ,"marin " , "marée" et "mur" la structure générale du niveau mot sera :
Figure 3A . 10 : Exemple de 1er niveau du MMC principal
-- Le niveau phonétique : chaque mot est décrit à l'aide du lexique issu de BDLEX et des classes majeures définies ci-dessus : chaque état de ce niveau réfère à une unité phonétique, c'est-à-dire une classe majeure. Les transitions probabilisées décrivent la décomposition phonétique des mots .
Pour résoudre le problème d'accès posé par la reconnaissance grands vocabulaires, le corpus à ce niveau est structuré de manière arborescente. Les représentations phonologiques en classes majeures sont factorisées à gauche. Les branches de l'arbre correspondant sont regroupées en une seule.
Les règles phonologiques traduites par les gpm de BDLEX sont interprétées à ce niveau par les fonctions Cluster et Coarticulation du compilateur de réseaux.
T # = # T R = TR W I = I W A = A y I = I T J = J Z J = Z L J = L N J = N S J = S R J = RTableau 3A. 11 : Règles de coarticulation utilisées
Par exemple pour les mots "ma" ,"marin " , "marée" et "mur" la structure générale du niveau phonétique sera :
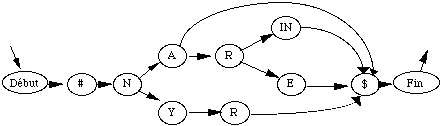
Figure 3A . 12 : Exemple de 2ième niveau du MMC principal
-- Le niveau acoustique : Chaque classe majeure du niveau supérieur est remplacée par son modèle acoustique pré-défini.
Les résultats qualitatifs de segmentation conduisent à classer les classes majeures en 12 catégories. Pour chacune d'elles, nous définissons un type de modèle acoustique en utilisant des connaissances a priori : la durée en nombre de segments de la classe majeure, sa stabilité spectrale permettent de proposer le nombre de lois d'observations. A titre d'exemple, une voyelle nasale est généralement formée de deux zones spectrales différentiables ( parfois trois ) : l'une est appelée classiquement la partie orale, l'autre la partie nasale. dans une nasale longue, ces deux parties sont obligatoirement présentes, à la différence d'une voyelle nasale dite brève. Ces considérations imposent d'utiliser 2 ( ou 3 ) transitions et 2 ( ou 3 ) lois d'observations [André-Obrecht, 93]. Le tableau 3A.13 donne la liste des modèles acoustiques utilisés.
A E e ITableau 3A . 13 : Modèles acoustiques des classes majeures ( le chiffre indique le numéro de loi )TR$ R$
O U Y S Z R schwa
D
% IN
DR
%$ IN$ T#
+
N J W y L T
#
TL TR
$
Par exemple pour le mot "ma", la structure générale du niveau acoustique est :
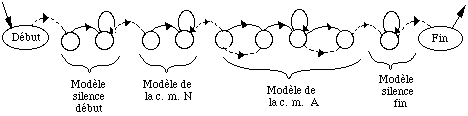
Figure 3A . 14 : Exemple de 3ième niveau du MMC principal
Les lois d'observations sont gaussiennes et les matrices de convergence sont diagonales.
Un lien de parenté de type "père/fils" est créé entre les états de deux niveaux adjacents. Ainsi, l'état référant à la graphie "ma" au niveau orthographique possède un lien de parenté avec les états désignant les classes majeures N et A au niveau inférieur, ceux-ci représentant sa décomposition phonétique. Suivant le même principe, ces états sont liés aux états du troisième niveau représentant leur décomposition acoustique.
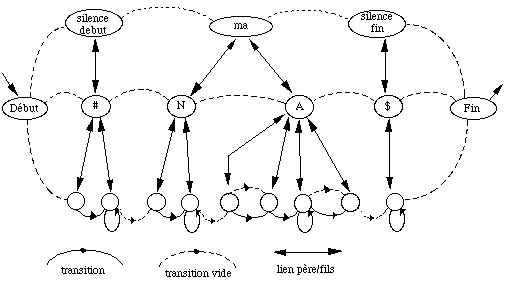
Figure 3A . 15 : Exemple des liens de parenté pour le mot "ma"
Etant donné la possibilité d'avoir plusieurs mots pour une même suite de classes majeures et la structure arborescente du niveau phonétique, un état référant à une classe majeure peut avoir plusieurs pères.
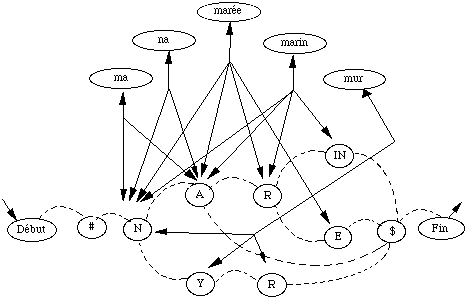
Figure 3A . 16 : Exemple d'un extrait des liens de parenté avec plusieurs pères
--Organisation en sous-dictionnaires : Les états du niveau mot sont regroupés en ensembles. Les états représentent la graphie des mots et les ensembles correspondent à des sous-dictionnaires. Le critère de regroupement choisi est, pour notre application, la représentation des mots en suites Consonnes/Voyelles. Selon notre propre notation, nous distinguons les consonnes facilement omises en début de mot par le code P, les autres consonnes par C et les voyelles par V. Les sous-dictionnaires sont composés de mots ayant des suites P/C/V communes. Afin de prendre en compte les variantes de prononciations, un mot peut faire partie de plusieurs sous-dictionnaires. Cette méthode de classification ne permet pas de prendre en compte les poids attachés à chacune des variantes de prononciations. Celles-ci sont donc considérées comme équiprobables.
Par exemple, les réalisations du mot "dur" peuvent être identifiées par les suites de classes majeures suivantes :
-- D Y R e --> dur ∈ sous dictionnaire "CVCV"
-- D Y R$ --> dur ∈ sous dictionnaire "CVC"
-- D Y --> dur ∈ sous dictionnaire "CV"
Sélection d'un sous-dictionnaire :
L'application de l'algorithme de Viterbi produit le meilleur chemin parmi les états du niveau acoustique.
Avec une reconnaissance classique, nous obtenons un sous-dictionnaire correspondant à une suite de Classes Majeures. En utilisant une reconnaissance ensembliste à l'aide des liens de parenté, nous obtenons les références des sous-dictionnaires sélectionnés en tant que suites de P/V/C.
Ces sous-dictionnaires désignent les sous-ensembles de mots à prendre en compte.
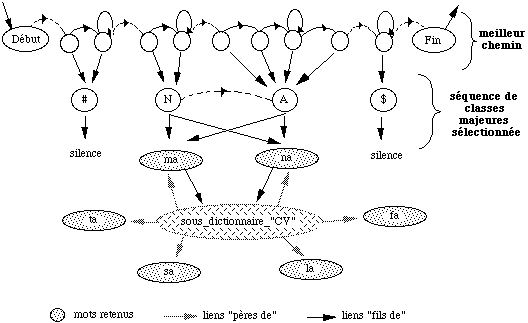
Figure 3A . 17 : Exemple d'obtention des mots du sous-dictionnaire à partir des liens de parenté et d'états-ensembles.
Les pseudo-diphones sont des unités phonétiques fines. Elles prennent en compte les parties stables des phonèmes ainsi que les transitions entre ceux-ci.
Par exemple le mot ma sera représenté par la suite de pseudo-diphones : #~m . m . m~a . a . a~$ Il est formé de deux sons stables m et a et d'une transition entre ces deux sons. Un MMC ( dont les unités de base sont les pseudo-diphones ) sera adapté au pré-traitement.
Cette deuxième phase de reconnaissance a pour but de rechercher le meilleur mot candidat dans le sous-dictionnaire trouvé précédemment. Ce sous-dictionnaire peut être issu d'une sélection par une suite de Classes Majeures ou par une suite de Consonnes/Voyelles. Le MMC modélisant le sous-dictionnaire est généré automatiquement par le compilateur de réseaux qui crée un réseau temporaire. Ce MMC "volatile" s'efface en même temps que l'arrêt de la phase de reconnaissance.
La recherche s'effectue par une nouvelle application de l'algorithme de Viterbi.
Le réseau modélisant le sous-dictionnaire est construit et organisé de manière similaire au précédent. Il comporte donc lui aussi trois niveaux :
-- Le niveau orthographique : chaque état réfère à la graphie d'un mot. La structure de ce niveau est identique à celle du MMC en classes majeures. Il y a autant d'états que le sous-dictionnaire comporte de mots.
-- Le niveau phonétique : le compilateur de réseaux fournit pour chaque mot un MMC dont les unités de base sont des pseudo-diphones : chacun de ces mots est décomposé en une séquence d'unités pseudo-diphones. Les règles phonologiques ( rubriques Cluster et Coarticulation du compilateur ) permettent d'accéder aux différentes prononciations des mots du sous-dictionnaire ainsi défini ( Figure 3A.17 ).
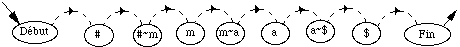
Figure 3A . 18 : Modèle phonétique pour le mot "ma" en unités pseudo-diphones
Le niveau phonologique de ce MMC temporaire n'est pas organisé en arbre. Par conséquent les états de ce niveau n'ont qu'un père.
Le vocabulaire retenu pour les tests ne comprend aucun couple d'homophones, nous n'avons donc pas eu à nous soucier de les distinguer. Cependant, on peut réaliser deux MMC phonétiques séparés et identiques ayant des pères orthogaphiques respectifs. Dans ce cas on identifie séparément deux mots homophones avec une même modélisation phonétique. La notion de sous-dictionnaire peut alors être utilisée pour effectuer un lien entre les homophones. Quant aux hétérographes, il faut différencier les noms de leur état au niveau orthographique et les lier avec leur modélisation phonétique respective.
-- Le niveau acoustique : à chaque unité pseudo-diphone correspond un modèle acoustique construit par le compilateur de réseaux. Ces modèles constituent le niveau acoustique de ce MMC.
La topologie de ces modèles provient de la visualisation des signaux acoustiques. Par rapport à la modélisation des modèles acoustiques des classes majeures, la modélisation des pseudo-diphones reflète quasiment le résultat de la segmentation : on a pratiquement une transition générant une loi d'observation par segment sur le signal, transition facultative pour les sons transitoires et obligatoire pour les sons stables. On peut observer une parfaite adéquation entre le pré-traitement et les unités phonétiques choisies.
Le choix des topologies des modèles des unités pseudo-diphones est identique à celui des unités en classes majeures ( cf page 96 ).
transitionTableau 3A . 19 : Modèles acoustiques des unités pseudo-diphonesconsonne
standard + double transition plosive~voyell e transition
plosive+
vers silence silences de fin début et fin +plosive~liqui de transition
plosive
plosive~silenc liquide e fin transition
liquide
obligatoire ( ex a~tr ) transition
voyelle
liquide~silenc nasale e de fin consonne+
diphtongue
voyelle + semi-voyelle
( les chiffres représentent les numéros de loi )
Les lois d'observations sont gaussiennes et les matrices de covariance sont diagonales.
Finalement , nous construisons un MMC dont la structure générale est de la forme :
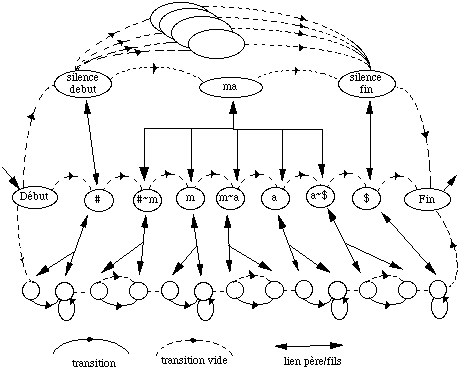
Figure 3A . 20 : Exemple du mot "ma" dans le MMC en pseudo-diphones
Sélection d'un mot :
Une autre application de l'algorithme de Viterbi produit le meilleur chemin parmi les états du niveau acoustique. En utilisant les liens de parenté dans le sens "père de" entre les états du chemin et ceux du niveau phonétique, nous obtenons une séquence de pseudo-diphones. Etant donné que les états du niveau phonétique n'ont qu'un seul père ( même dans les cas des mots homophones et hétérographes ), les liens de parenté de ces états phonétiques désignent le mot reconnu dans le niveau supérieur.
Afin de valider notre outil informatique, nous avons effectué les expérimentations sur un vocabulaire de base de 500 mots, les 500 mots les plus fréquents du français fournis par le CNET ( Cf Annexe A4 ). Ils sont constitués essentiellement de mots monosyllabiques et bisyllabiques.
Les données ont été enregistrées par 10 locuteurs ( 6 hommes et 4 femmes ). L'ensemble d'apprentissage se compose de 2 répétitions par locuteur de chacun des mots du vocabulaire ( soit 10 000 prononciations ). Une nouvelle prononciation de ces mêmes 500 mots pour chacun des 10 locuteurs est utilisée pour former l'ensemble de test ( soit 5 000 prononciations supplémentaires ).
Des sous ensembles de test et d'apprentissage spécifiques aux locuteurs hommes et femmes ont été réalisés.
Le but de ces expérimentations est essentiellement de valider l'outil présenté dans le chapitre II ; nous n'avons pas cherché à obtenir de taux de reconnaissance concurrentiels. Afin d'étudier la faisabilité de notre système, nous avons choisi un vocabulaire de taille modeste et une reconnaissance en mots isolés ; dans le cas où ces expériences seraient convaincantes, nous étendrions cette approche à des tâches de type dictée vocale.
Le corpus du CNET a été enregistré à travers le réseau téléphonique, rendant les conditions d'expérimentation sévères : bande passante de 3,3 kHz, échantillonnage de 8 kHz.
Le pré-traitement acoustique du signal fournit pour chaque segment 8 MFCC, l'énergie, les 8 dérivées des MFCC, la dérivée de l'énergie et la durée du segment.
Les apprentissages sont réalisés avec seulement 8 coefficients cepstraux et la durée du segment. La réestimation de la variance des lois d'observations est seuillée à 15% de la variance des observations de l'ensemble d'apprentissage considéré, pour éviter les problèmes liés à un manque de données.
Cette première série d'expériences a pour but d'étudier le comportement du compilateur et parrallèlement d'avoir une première mesure des performances du filtre lexical.
Nous avons extrait de manière aléatoire 50 mots de la liste des 500 mots cités ci dessus, cette sous liste est fixée pour tous les tests reportés dans ce présent paragraphe ( la liste de ces mots est donnée en Annexe A5 ).
L'ensemble d'apprentissage est formé de 50 mots x 2 prononciations x 10 locuteurs ( 1 000 occurences ). L'ensemble de test est composé de 50 mots x 1 prononciation différente x 10 locuteurs ( 500 occurences ). Chacun des ensembles est lui même scindé en deux sous ensembles, correspondant aux locuteurs hommes et femmes respectivement. La tâche est donc de reconnaître un mot sur 50 et non plus sur 500.
Les 50 mots ont été modélisés avec les gpm de BDLEX en contexte "fin de phrase", ce qui correspond à notre contexte de mot isolé. Ceux-ci ont été traduits en classes majeures compatibles avec les modèles acoustiques créés pour le filtrage lexical. Finalement, un Modèle de Markov Caché modélisant ces 50 mots avec des unités phonétiques en classes majeures a été construit.
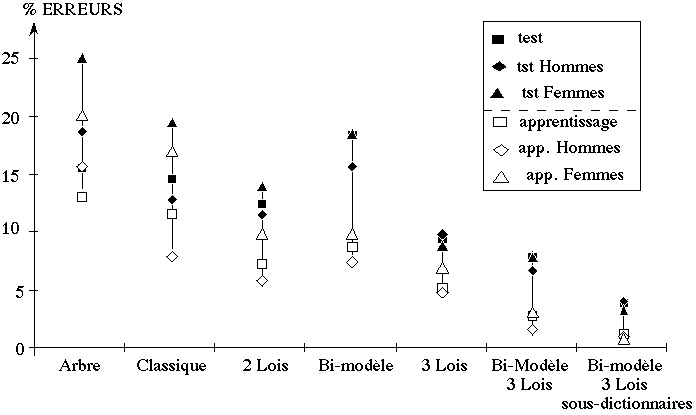
Figure 3A. 21 : Taux d'erreurs des modèles de 50 mots en Classes Majeures
Le graphique figure 3A.21 donne les courbes des taux d'erreurs en fonction des modèles expérimentés et des ensembles reconnus. Ces modèles sont classés suivant leur complexité. Les tests de reconnaissance sont réalisés systématiquement sur les six ensembles de données. De manière générale, trois modèles sont appris à partir respectivement de l'ensemble d'apprentissage total et des ensembles d'apprentissage homme et femme, les expériences de reconnaissance sont effectués sur ces mêmes ensembles et sur les trois ensembles test correspondants, à savoir l'ensemble de test total et les ensembles de test homme et femme. L'initialisation de chacun des modèles est spécifié lors des commentaires.
Pour les modèles de type MMC0 et MMC1, les lois de probabilité ont été initialisées avec les valeurs par défaut données par le compilateur : 0 pour tous les éléments du vecteur moyenne et 1 pour tous les éléments du vecteur variance.
* MMC en Arbre ( MMC0_50_CM ) :
Les niveaux phonétique et acoustique sont organisés de manière arborescente : les débuts de mots communs sont factorisés dans les mêmes branches. Cette organisation permet d'optimiser la place mémoire et le temps de calcul : dans notre application nous obtenons un gain de 14% de la taille du réseau en mémoire et la rapidité d'exécution de l'algorithme de Viterbi augmente de 42% par rapport au modèle classique. La perte d'information engendrée ( les probabilités de transitions infra-mots ) dégrade sensiblement ( d'environ 1% sur le modèle global ) les performances du réseau par rapport à une organisation classique comme le montrent les tableaux 3A.21 et 3A.22.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
15,3 % 12,8% 18,5% 24,8% 15,5% 19,9%
Tableau
3A.22 : Taux d'erreurs pour le modèle en arbre en fonction des
différents ensembles d'apprentissage et de test.
* MMC classique ( MMC1_50_CM ) :
Un modèle de Markov classique permet pour un mot, d'une part d'affiner sa représentation phonologique, et d'autre part d'obtenir une meilleure représentation probabiliste de celui-ci : les probabilités de transitions contenues dans le MMC du mot lui sont propres.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
14,3% 11,3% 12,7% 19,3% 7,6% 16,8%
Tableau
3A.23 : Taux d'erreurs pour le modèle classique en fonction des
différents ensembles d'apprentissage et de test.[Jouvet, 94] a montré que l'augmentation des paramètres conduit à une amélioration des performances de reconnaissance pour des modèles de Markov centisecondes. L'accroissement des paramètres peut s'effectuer selon deux manières :
-- l' utilisation de multi-modèles pour une même unité à reconnaître
-- l' utilisation de plusieurs gaussiennes
-- l'accroissement de la dimension du vecteur d'observations.
Nous avons testé des combinaisons successives des deux premières approches pour les modèles segmentaux de notre application.
* MMC avec 2 lois gaussiennes ( MMC2_50_CM ) :
Les transitions supportant les lois du modèle MMC1_50_CM sont dupliquées en deux exemplaires, en utilisant l'option multi gausienne de notre outil : un critère de loi au sens de notre outil, est attribué à chaque transition. L'apprentissage est réalisé en trois étapes : le modèle est appris avec les fichiers d'apprentissage correspondant aux prononciations des locuteurs masculins en ne prenant en compte que les lois de critère 1. Nous procédons de la même manière pour les lois de critère 2 avec les locuteurs féminins et enfin, nous réalisons un apprentissage global sur tous les critères de lois.
Les lois de critère 1 sont initialisées avec la moyenne des coefficients cepstraux correspondants aux fichiers d'apprentissage sur les 50 mots des locuteurs hommes. De même les lois de critère 2 sont initialisées avec la moyenne des coefficients cepstraux des fichiers d'apprentissage des locuteurs femmes, également sur les 50 mots de notre application. Cette initialisation se réalise par le bloc de commandes d'initialisations des lois ( bloc LOIS dans le cas des multi-gaussiennes ).
Les reconnaissances globales sont effectuées à partir des fichiers d'observations des hommes et femmes. Les reconnaissances pour les locuteurs masculins ne prennent en compte que les prononciations des hommes. Respectivement, les reconnaissances sur les locuteurs féminins ne considèrent que les observations des femmes. Toutes les reconnaissances s'effectuent sur le même MMC2_50_CM. Celles-ci ne diffèrent donc que par les fichiers d'observations qu'elles ont en entrée.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
12,2% 7 % 11,3% 13,7% 5,6% 9,6%
Tableau
3A.24 : Taux d'erreurs pour le modèle à 2 lois gaussiennes en
fonction des différents ensembles d'apprentissage et de test.
* MMC bi-modèle ( MMC3_50_CM ) :
Le modèle classique MMC1_50_CM est dupliqué en deux exemplaires MMC3_50_CM_H et MMC3_50_CM_F. Le premier est appris par les locuteurs masculins et le deuxième par les locuteurs féminins. Ces deux modèles sont fusionnés en un seul réseau multi-modèles MMC3_50_CM par la fonction décrite au chapitre II.7 page 69.
Les reconnaissances des locuteurs masculins et féminins ont été réalisées respectivement sur les modèles MMC3_50_CM_H et MMC3_50_CM_F avant la fusion en un bi-modèle MMC3_50_CM.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
18,2% 8,5% 15,4% 18,3% 7,1% 9,6%
Tableau
3A.25 : Taux d'erreurs pour le bi-modèle Hommes/Femmes en fonction des
différents ensembles d'apprentissage et de test.
* MMC avec 3 lois gaussiennes ( MMC4_50_CM ) :
MMC4_50_CM est une variante de MMC2_50_CM : les transitions du modèle initial sont multpliées par 3 correspondant à trois critères de loi :
Critère de loi 1 --> les lois d'observation sont apprises avec les locuteurs Hommes, initialisées avec la moyenne des fichiers d'observations des locuteurs masculins sur 50 mots
Critère de loi 2 --> les lois sont apprises avec les locuteurs Femmes , initialisées avec la moyenne des fichiers d'observations des locuteurs féminins sur 50 mots
Critère de loi 3 --> les lois sont apprises avec les locuteurs Hommes + Femmes, initialisées avec la moyenne des fichiers d'apprentissage sur 50 mots
Un apprentissage global est ensuite effectué sur tous les critères de lois.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
9,2% 5% 9,6% 8,6% 4,6% 6,7%
Tableau
3A.26 : Taux d'erreurs pour le modèle à 3 lois gaussiennes en
fonction des différents ensembles d'apprentissage et de test.
* MMC bi-modèle avec 3 lois gaussiennes ( MMC5_50_CM ) :
Le MMC4_50_CM appris est transformé en multi-modèles de manière identique au MMC3_50_CM : le MMC4_50_CM est dupliqué en un modèle MMC5_50_CM_H dédié aux locuteurs hommes, et un deuxième modèle MMC4_50_CM_F dédié aux locuteurs femmes. MMC5_50_CM_H et MMC5_50_CM_F sont ré-appris respectivement sur les ensembles d'apprentissage des Hommes et des Femmes. Les taux d'erreurs relatifs aux Hommes et Femmes sont issus des modèles MMC5_50_CM_H et MMC5_50_CM_F. Ceux-ci sont ensuite fusionnés en un bi-modèle MMC5_50_CM pour un test global.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
7,6% 2,2% 6,5% 7,6% 1,4% 2,8%
Tableau
3A.27 : Taux d'erreurs pour le bi-modèle Hommes/Femmes à 3 lois
gaussiennes en fonction des différents ensembles d'apprentissage et de
test.
* MMC bi-modèle avec 3 lois gaussiennes et sous-dictionnaires ( MMC6_50_CM ) :
Le MMC5_50_CM est organisé en ensembles d'états au niveau orthographique. Chaque ensemble d'états correspond à un sous-dictionnaire. Les sous-dictionnaires représentent les modélisations en Consonne/Voyelle des mots du vocabulaire. Compte tenu des variantes de prononciations, les mots peuvent appartenir à plusieurs ensembles. Nous avons créé 19 ensembles correspondants à des suites de :
- consonnes facultatives en début de mot ( P ). Cette classe particulière à pour but de regrouper les consonnes dont le burst est souvent confondu avec le silence de début, telles que les plosives par exemple.
-voyelles ( V )
- consonnes ( C )
dont la liste est donnée en Annexe A6.
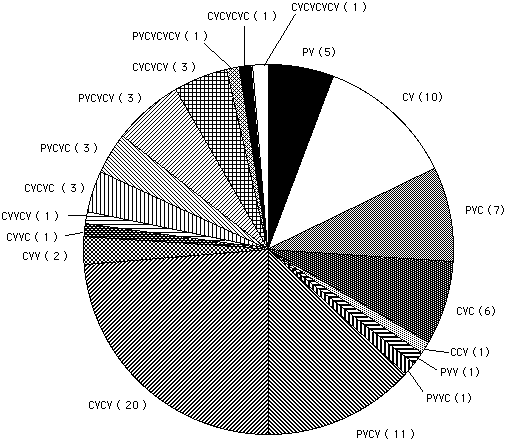
Figure 3A.28 : Nombre d'éléments par ensemble pour le modèle de 50 mots.
test global apprentissage test Hommes test Femmes apprentissage apprentissage
global Hommes Femmes
3,7% 0,9% 3,8% 3,1% 0,7% 0,5%
Tableau
3A.29 : Taux d'erreurs obtenus avec une reconnaissance ensembliste.pour le
bi-modèle avec 3 lois gaussiennes en fonction des différents
ensembles d'apprentissage et de test.
L'augmentation des paramètres obtenue en augmentant le nombre de gaussiennes améliore plus sensiblement les taux de reconnaissance qu'une augmentation due à un nombre croissant de modèles par unité : la modélisation classique Hommes-Femmes n'est peut être pas la mieux adaptée à notre application. Le meilleur taux de reconnaissance que nous obtenons est de 92,4% avec un bi-modèle et trois gaussiennes ( MMC5_50_CM ). En utilisant une reconnaissance ensembliste, nous réduisons environ de moitié le taux d'erreurs mais nous reconnaissons alors un sous-dictionnaire de type Consonnes/Voyelles.
Afin de tester la robustesse des réseaux construits, nous avons effectué quelques applications sur la totalité du lexique.
La Figure 3A.30 ci-dessous représente les taux d'erreurs obtenus avec des Modèles de Markov modélisant les 500 mots du lexique du CNET. Les conditions d'expérience sont identiques à celles utilisées dans l'application 50 mots. Seuls les résultats de reconnaissance sur les ensembles totaux d'apprentissage et de test sont donnés.
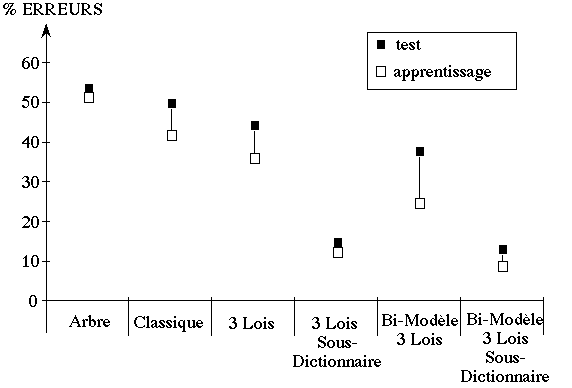
Figure 3A.30 : Taux d'erreur pour les modèles de 500 mots en Classes Majeures
* MMC en Arbre ( MMC0_500_CM ) :
L'avantage de l'organisation arborescente du lexique est confirmée, elle nous permet d'obtenir des gains de place mémoire et de temps de calcul dans les mêmes proportions que dans l'application des 50 mots.
Test Apprentissage
52,7% 50,6%
Tableau
3A.31 : Taux d'erreurs pour le modèle Classes Majeures en arbre sur 500
mots
* MMC classique avec 1 loi gaussienne ( MMC1_500_CM ) :
Test Apprentissage
49% 41%
Tableau
3A.32 : Taux d'erreurs pour le modèle Classes Majeures à 1 loi
gaussienne sur 500 mots
* MMC avec 3 lois gaussiennes ( MMC2_500_CM ) :
Les transitions supportant des lois dans le MMC classique sont triplées. Les lois sont initialisées et apprises de la même manière que le MMC4_500_CM des 50 mots mais en prenant en compte les fichiers d'observations correspondant à tous le corpus des 500 mots.
Test Apprentissage
43,5% 35,1%
Tableau
3A.33 : Taux d'erreurs pour le modèle Classes Majeures à 3 lois
gaussiennes sur 500 mots.
Les sous-dictionnaires utilisés dans les 500 mots sont construits de la même manière que ceux des 50 mots avec des suites P/V/C. Le nombre de sous-dictionnaires s'élève ici à 30 et la répartition des mots est donnée en Annexe A7.
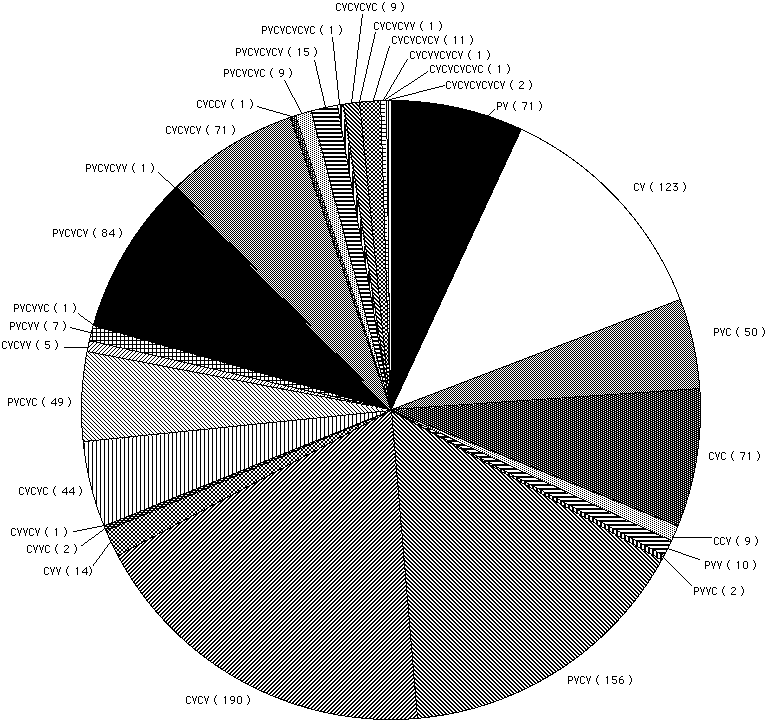
Tableau 3A.34 : Nombre de mots dans les ensembles de Consonnes/Voyelles pour les 500 mots.
* MMC avec 3 lois gaussiennes et sous-dictionnaires ( MMC3_500_CM ) :
Le MMC2_500_CM appris est organisé en ensembles d'états de façon identique au MMC6_50_CM des 50 mots. Il n'y a pas de nouvel apprentissage des paramètres de ce modèle.
Test Apprentissage
14% 11,4%
Tableau
3A.35 : Taux d'erreurs avec une reconnaissance ensembliste pour le
modèle en Classes Majeures à 3 lois gaussiennes sur 500 mots dont
les états orthographiques ont été regroupés en
ensembles Consonnes/Voyelles.
Les taux de reconnaissance sont ici donnés en termes de suites Consonnes/Voyelles et non de Classes Majeures.
* MMC bi-modèle avec 3 lois gaussiennes ( MMC4_500_CM ) :
La structure du MMC2_500_CM est dupliquée en deux modèles MMC4_500_CM_H dédié aux locuteurs masculins et MMC4_500_CM_F dédié aux locuteurs féminins. Ceux-ci sont appris respectivement sur les fichiers d'observations des 500 mots correspondant aux Hommes d'une part et aux Femmes d'autre part. MMC4_500_CM_H et MMC4_500_CM_F sont fusionnés en un bi-modèle MMC4_500_CM.
Test Apprentissage
36,9% 23,8%
Tableau
3A.36 : Taux d'erreurs pour le bi-modèle Hommes/Femmes en Classes
Majeures à 3 lois gaussiennes sur 500 mots .
* MMC bi-modèle avec 3 lois gaussiennes et sous-dictionnaires ( MMC5_500_CM ) :
Le MMC4_500_CM est organisé en ensembles d'états de la même manière que le MMC3_500_CM. Ce modèle ne subit pas de nouvel apprentissage.
Test Apprentissage
12,2 7,8%
Tableau
3A.37 : Taux d'erreurs avec une reconnaissance ensembliste pour le
bi-modèle Hommes/Femmes à 3 lois gaussiennes sur 500 mots dont
les états orthographiques ont été regroupés en
ensembles Consonnes/Voyelles.
Le meilleur taux que nous obtenons est de 63,1% en termes de mots et de 83,8% en termes de sous-dictionnaires Consonnes/Voyelles.
Cependant, on peut s'apercevoir que d'une manière générale, les résultats obtenus sur les modèles de 500 mots ne sont guère satisfaisants. Quelques remarques peuvent peut-être apporter un début de réponse :
* Si on compare ces résultats aux modèles de 50 mots, les taux de reconnaissance sont proportionnellement très inférieurs : bien que les modèles des 500 mots aient bénéficié d'un ensemble d'apprentissage plus important, ceux-ci ont servi de support à beaucoup moins d'expérimentions ( pour des raisons de temps de calculs ). Nous n'avons donc pas apporté autant d'améliorations aux modèles de 500 mots qu'aux modèles de 50 mots.
* De plus, il semblerait q'un pré-traitement lexical uniquement basé sur une segmentation ne soit pas adapté à un filtrage lexical. Par rapport à un découpage centisecondes, nous réduisons de beaucoup l'information contenue dans chaque segment. Comme on peut s'en rendre compte en synthèse de la parole, contrairement aux segments stables des sons, les segments transitoires supportent très mal cette réduction. Or nous réduisons tous les segments. Peut-être qu'une solution consisterait en un pré-traitement acoustique couplant une segmentation et un découpage centisecondes.
* Il faut aussi remarquer qu'un filtrage efficace basé sur un alignement par l'algorithme de Viterbi entre les représentants de classes majeures ( ou syllabiques [El-Bèze, 87] ) n'est pas aisée à réaliser pour un système monolocuteur. A plus forte raison, cela l'est encore moins pour un système multilocuteurs dont les unités utilisées pour le filtrage lexical sont apprises avec un signal réduit ne pouvant peut-être pas refléter la grande variabilité du signal existant entre plusieurs locuteurs.
* Enfin, on est en droit de penser que notre modèle est très pauvre en nombre de paramètres pour appréhender le problème de cette variablité entre plusieurs locuteurs. Nous n'utilisons seulement qu'un classique bi-modèle Hommes/Femmes avec 3 lois gaussiennes alors que pour le même corpus [Jouvet, 94] recommande un multi-modèles allant au delà de deux classes de locuteurs avec un nombre moyen de 8 gaussiennes.
Dans l'optique d'obtenir un système de reconnaissance complet, nous nous sommes penchés sur la deuxième passe de la reconnaissance avec les unités pseudo-diphones afin d'évaluer les performances du système complet.
Chaque apprentissage de modèle est réalisé en deux passes :
1deg.) Un premier apprentissage est effectué en utilisant seulement 8 coefficients cepstraux
2deg.) Au cours d'un deuxième apprentissage, est adjointe la durée du segment.
La réestimation de la variance des lois d'observations est seuillée à 0,07.
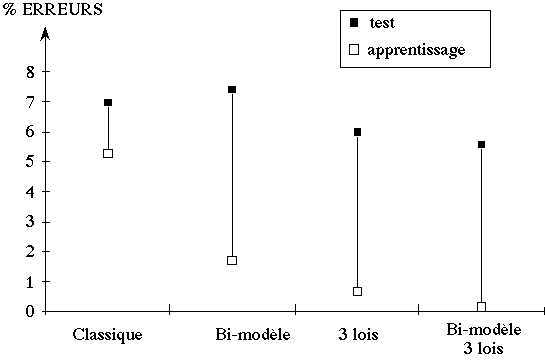
Figure 3A.38 : Taux d'erreurs pour les modèles de 50 mots en pseudo-diphones
La Figure 3A.38 représente les taux d'erreurs obtenus avec des Modèles de Markov sur les ensembles d'apprentissage et de test : les unités à reconnaître sont des pseudo-diphones et l'application est la reconnaissance des 50 mots, la complexité des modèles est croissante.
* MMC classique avec 1 loi gaussienne ( MMC0_50_PD ) :
Les lois ont été initialisées avec les valeurs par défaut.
Test Apprentissage
7% 5.2%
Tableau
3A.39 : Taux d'erreurs pour le modèle en pseudo-diphones à 1 loi
gaussienne sur 50 mots.
* MMC bi-modèle ( MMC1_50_PD ) :
La structure du modèle MMC0_50_PD est dupliquée en deux modèles MMC1_50_PD_H et MMC1_50_PD_F. Ces derniers sont respectivement appris avec les fichiers d'observations des locuteurs masculins et féminins. MMC1_50_PD_H et MMC1_50_PD_F sont ensuite fusionnés en un bi-modèle Hommes/Femmes appelé MMC1_50_PD. Il n'y a pas de nouvel apprentissage de MMC1_50_PD.
Test Apprentissage
7.4% 1,6%
Tableau
3A.40 : Taux d'erreurs pour le bi-modèle Hommes/Femmes en
pseudo-diphones sur 50 mots.
* MMC avec 3 lois gaussiennes ( MMC2_50_PD ) :
Les transitions supportant des lois dans le MMC0_50_PD classique sont triplées. Les lois sont initialisées puis apprises de manière similaire au MMC4_50_CM des 50 mots en Classes Majeures.
Test Apprentissage
5,9% 0,6%
Tableau
3A.41 : Taux d'erreurs pour le modèle en pseudo-diphones à 3 lois
gaussiennes sur 50 mots.
* MMC bi-modèle avec 3 lois gaussiennes ( MMC3_50_PD ) :
Le modèle MMC2_50_PD est dupliqué en deux modèles MMC3_50_PD_H et MMC3_50_PD_F. Ces derniers sont respectivement ré-appris avec les fichiers d'observations des locuteurs masculins et féminins. Les modèles MMC3_50_PD_H et MMC3_50_PD_F sont ensuite fusionnés en un bi-modèle Hommes/Femmes MMC3_50_PD. Il n'y a pas de nouvel apprentissage de MMC3_50_PD.
Test Apprentissage
5,5% 0,1%
Tableau
3A.42 : Taux d'erreurs pour le bi-modèle Hommes/Femmes en
pseudo-diphones sur 50 mots.
On observe une certaine stabilité des résultats en test. Cependant, les reconnaissances sur les fichiers d'apprentissages sont sensibles à l'augmentation des paramètres dans les MMC proposés. L'écart important entre les deux courbes de la figure 3A.38 et le grand nombre d'unités pseudo-diphones à apprendre ( en particulier les unités modélisant les transitions entre les sons ) permet de penser que l'ensemble d'apprentissage est peut-être insuffisant. L'utilisation d'une variance seuillée a permis d'augmenter sensiblement les taux de reconnaissance mais une utilisation sur l'ensemble des 500 mots serait peut-être plus significative.
Dans la mesure où il s'agit d'une étude préliminaire afin de valider outil informatique, il n'était pas envisageable de modéliser et surtout d'apprendre tous les réseaux liés à la totalité du BDLEX. Nous voulions surtout nous assurer que le processus de reconnaissance à travers un filtre lexical ne dégradait pas trop les performances du système.
La deuxième étape modélisant le sous-dictionnaire issu du filtre lexical en un MMC temporaire afin de réaliser automatiquement une reconnaissance avec des unités pseudo-diphones n'a pas été implantée dans notre système mais peut être faite manuellement.
Dans le but de montrer la faisabilité de cette approche, nous nous sommes limités à appliquer le filtre lexical sur le corpus des 500 mots isolés du CNET.
Les premiers résultats sont obtenus sur un vocabulaire de 50 mots tirés aléatoirement parmi ces 500 mots les plus fréquents du français. Il en résulte qu'il s'agit essentiellement de mots monosyllabiques ou bisyllabiques plus difficiles à reconnaître que les mots de plus grande longueur. Les taux de reconnaissance sont obtenus en ne prenant seulement en compte que les huit premiers coefficients cepstraux et la durée du segment. En termes de sous-dictionnaire correctement sélectionné, nous obtenons un taux de 96,3 % avec un algorithme de reconnaissance ensembliste et un taux de 92,4 % en alignant uniquement les observations sur les unités en classes majeures. Il est à noter que dans le cadre de cette expérience, un sous-dictionnaire identifié par une suite de classes majeures ne contient que rarement plus d'un mot.
Nous avons comparé cette approche à l'approche classique où chaque mot est directement modélisé par un MMC dont les unités de base sont des pseudo-diphones. Le taux de reconnaissance en termes de mots correctement identifiés est de 93,9 %. Un exemple de comparaison est donné en Figure 3A.43.
Dans le cadre de cette application , nous pouvons estimer le taux de reconnaissance de la totalité de notre système à 90,4 % en utilisant une reconnaissance ensembliste ou de 86,8 % sinon.

Figure 3A.43: Résultats des étapes de reconnaissance sur le mot "n'est-ce pas"
(a) sous forme de classes majeures
(b) sous forme de pseudo-diphones
Nous avons poursuivi cette étude en appliquant le filtre lexical sur les 500 mots. Nous obtenons un taux de sélection du bon sous-dictionnaire de 87,8 % avec une reconnaissance ensembliste et de 63,1 % sans celle-ci.
La dégradation que nous observons peut être essentiellement due à notre manque de connaissance pour modéliser les classes majeures et au manque de discernement du système entre les silences et les débuts de mots. Nous allons poursuivre cette recherche en améliorant les modèles de Markov élémentaires. Les modèles de silence de début et de fin de mots subiront un apprentissage spécifique et seront intégrés dans le réseau global à l'aide des fonctions du compilateur.
Le besoin d'implanter de telles améliorations ne peut se concrétiser que graduellement dans le cycle de vie d'un système et beaucoup de ces modifications seront certainement envisagées dans un proche avenir.
Néanmoins la base de notre système nous paraît suffisamment fiable pour que les apports successifs de ces améliorations contribuent à rendre le filtrage lexical performant.
Dans le cadre du projet Applications Multimodales pour Interfaces et Bornes Evoluées ( projet AMIBE soutenu par les PRC Informatique 1993 - 1995 ), est étudiée la bi-modalité naturelle auditive et visuelle de la communication orale. La reconnaissance automatique de parole s'opère en synchronisant une "lecture labiale" avec un module de reconnaissance des formes acoustiques, par Modèles de Markov Cachés.
Pour fusionner les données acoustiques et articulatoires, plusieurs alternatives se présentent. [Jourlin, 94] propose un traitement séparé des observations labiales et acoustiques dans deux MMC individuels dont les scores sont ensuite fusionnés. Nous pouvons citer également l'étude de [Robert-Ribes, 95] qui montre que la fusion de données auditives et visuelles donne de meilleurs résultats dans une reconnaissance automatique des voyelles qu'une reconnaissance acoustique seule.
Nous avons envisagé deux types de fusions des observations acoustiques et labiales. Dans une première méthode, les informations sont traitées sans prendre en compte leurs éventuelles corrélations, par un MMC classique ; le vecteur d'observations est la concaténation des deux familles de paramètres labiaux et acoustiques ; ils sont considérés comme indépendants mais l'utilisation de pondérations peut permettre de réduire l'importance de l'une par rapport l'autre (nous parlerons, dans la suite de ce manuscrit d'approche globale et de MMC global). Une deuxième alternative consiste à modéliser chaque famille de paramètres par un modèle de type MMC, et corréler les deux modèles par une dépendance entre les lois. Nous avons étudié plus particulièrement cette approche appelée par la suite approche maître-esclave ; nous nous sommes inspirés des travaux de Brugnara et De Mori qui ont appliqué cette liaison maître-esclave pour traiter la durée des sons (cf chapitre I.5 , [Brugnara, 92] page 38).
Au cours de cette partie, le principe de l'approche maître-esclave est rappelé brièvement et nous présentons comment à l'aide de l'outil informatique présenté au chapitre 2, nous réalisons un modèle équivalent à un modèle maître-esclave sous certaines hypothèses simplificatrices. Des résultats expérimentaux illustrent cette approche, dans les cas de la reconnaissance de suites de chiffres et lettres épelées. Une comparaison entre approche globale et approche maître-esclave est proposée.
Le principe des modèles dits "maître-esclave" repose sur la modélisation d'une application non plus par un MMC unique mais par deux MMC mis en parallèle et corrélés. L'idée générale est de parvenir à une adaptation dynamique des lois de probabilités d'un des modèles de Markov cachés, en fonction du contexte courant modélisé par l'autre MMC. Le contexte est une notion qui doit être prise au sens large, il peut s'agir d'un indice de voisement, de nasalisation..., d'un réel contexte phonétique, d'un indice suprasegmental comme la durée des sons ...tandis que le MMC piloté peut traditionnellement être lié à des paramètres acoustiques.
Un modèle maître-esclave se compose donc de deux modèles, un modèle maître λ' et un modèle esclave λ'', définis comme suit :
* Le modèle λ' est un MMC classique, composé de deux processus stochastiques X', Y' :
* le processus caché X' est à valeurs dans χ' = { x'}, ensemble d'états fini. Etant d'ordre 1, il vérifie les équations suivantes :
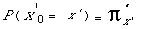
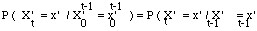
= a' z'x' avec z' = x' t-1 . ∪ t 0< t <=T
* le processus Y' est à valeurs dans un ensemble mesurable V' et vérifie :
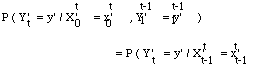
= b' z'x' (y'). ∪ t 0< t <=T
* Le modèle λ" est un MMC dont les paramètres dépendent à tout instant de l'état dans lequel se trouve le modèle maître :
* le processus caché X" est à valeurs dans χ" = { x"} ensemble d'états fini ; sa loi est définie de la manière suivante :
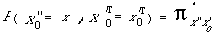
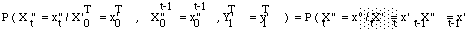 = a" z"x"x' avec z" = x" t-1 et x' = x' t .
= a" z"x"x' avec z" = x" t-1 et x' = x' t .
* le processus Y" est à valeurs dans un ensemble mesurable V" et sa distribution vérifie :
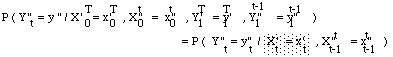
= b" z"x"x' (y").
Le modèle maître-esclave λ = ( λ', λ") est décrit par l'ensemble des paramètres
( π', π", A'.., B'... (.), A".., B"... (.) )
La vraisemblance d'une suite d'observations y1T = ( y'1T, y"1T) conditionnellement au modèle λ = ( λ', λ") est donnée par :
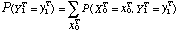
et peut se calculer, après application de la règle de Bayes, à l'aide des deux expressions suivantes :
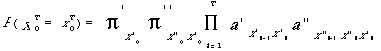
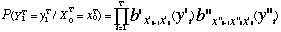
Etant donné une suite d'observations y1T = ( y'1T, y"1T), le chemin le plus probable ayant généré cette séquence vérifie :
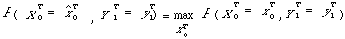
et s'obtient par un algorithme de Viterbi modifié :
considérons la fonction
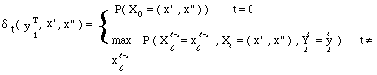
elle se calcule par récurrence
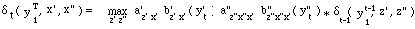
D'après [Brugnara, 92], un modèle maître-esclave est équivalent mathématiquement à un modèle classique de type MMC dont les lois obéïssent à certaines contraintes. En reprenant les notations du paragraphe précédent, le processus caché X est alors un double processus (X', X") à valeurs dans le produit cartésien χ'x χ" de cardinal N' x N" :
un état de X sera caractérisé par le couple d'états x=( x',x"),
Le processus observable Y = ( Y' , Y" ) est à valeurs dans l'ensemble mesurable V'x V" :
une observation de Y sera caractérisée par le couple d'observations y = (y',y")
Les N' N" probabilités initiales. et les (N' N")2 probabilités de transitions et lois d'observations du modèle de Markov caché λ = ( X , Y ) sont caractérisées par les contraintes (figure 3B.1) :
a xz = a'x'z' a"x"z"z'
bxz(y) = b' x'z'(y') b"x"z"z'(y")
πx = π' x' π"x"x'
et
Σ b'x'z' (y') = 1 et Σ b"x"z" (y") = 1 => Σ bxz (y) = 1
y' y" y
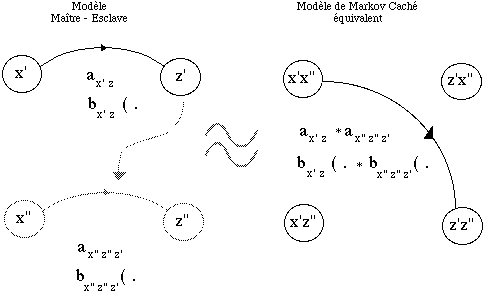
Figure 3B . 1 : Modèle maître-esclave et son modèle équivalent
L'inconvénient de ce modèle réside dans son important nombre d'états et de lois. Ne pouvant raisonnablement implanter un tel modèle, nous avons émis des hypothèses simplificatrices.
Dans le cadre de notre application, nous avons choisi arbitrairement le modèle maître pour décrire le contexte labial. Comme nous le verrons ci-après, le modèle maître est celui sur lequel nous faisons la plus forte hypothèse simplificatrice, à savoir que toutes les transitions sont équiprobables ( en test et en apprentissage ).
En supposant donc que toute configuration au niveau labial est équiprobable indépendamment de la précédente, la topologie du modèle maître est celle d'un modèle ergodique, où tout état est relié à n'importe quel état du modèle, y compris lui-même. En particulier, si N désigne le nombre d'états du modèle, il indique aussi le nombre d'états que l'on peut atteindre pour tout état du MMC. Ceci s'exprime par :
a'x'z' = 1 / N, si N est le nombre d'états.
Nous supposons de plus que les lois d'observation portées par les transitions ( x'z' ) ne dépendent que de l'état d'arrivée z'
b' x'z'(y') = b' u'z'(y') pour tout u',x',y'.
Il s'ensuit que l'on peut remplacer le modèle équivalent par un modèle simplifié dont le nombre d'états est le nombre d'états du modèle esclave, mais chaque transition du modèle esclave est dupliquée par le nombre d'états du modèle maître et chaque nouvelle transition est indexée par un état maître (figure 3B . 2). Les transitions émettent les observations Y = ( Y',Y" ). Sur une même transition, on aligne les vecteurs d'observation y = ( y',y" ) qui sont la concaténation des vecteurs acoustiques et labiaux. On indique au modèle maître-esclave, par des paramètres, les longueurs respectives des observations acoustiques et labiales afin d'effectuer des réestimations séparées.
Nous avons modélisé à l'aide du compilateur le modèle simplifié présenté ci dessus. Une option du compilateur permet d'activer la construction d'un tel modèle:
* rubrique NB_MAITRE: <nbétatmaître>
<nbétatmaître> indique le nombre d'états dans le réseau maître.
La description du réseau correspond à la celle du modèle esclave, elle suit la syntaxe présentée dans le Chapitre II ; le nombre de transitions non vides entre chaque couple d'états est multiplié par le nombre d'états précisé dans la rubrique NB_MAITRE, ainsi que le nombre de lois d'observations ; à chacune d'entre elles est attribué un critère de loi (indice entre 1 et <nbétatmaître>).
Le nombre de coefficients par vecteur d'observation correspondant à l'observation maître ( y' ) concaténée à l'observation esclave (y"), est indiqué lors de l'apprentissage. L'apprentissage s'effectue par la recherche du chemin optimal avec l'algorithme de Viterbi mais il est modifié de façon à effectuer les réestimations contraintes. La réestimation des paramètres maître et esclave font l'objet de deux sous-réestimations séparées, cette opération est facilitée par l'existence du paramètre "critère de loi".
Le programme de reconnaissance est classique.
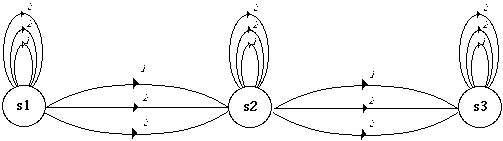
Figure 3B.2 : Représentation du réseau maître-esclave simplifié correspondant à un modèle maître de 3 états. Les transitions supportant une loi d'observation sont dupliquées en trois. Chaque duplicata de la loi porte un numéro d'état maître et les probabilités de transitions sont mises à jour.
Les lois peuvent être initialisées par l'utilisateur en précisant dans la rubrique RACINES des couples d'identifiants : ( classe d'états , numéro d'état maître ).
LOIS
TYPE C
LONGUEUR 5
:
:
VALEURS
<moy_cepst 1> <moy_cepst 2> <moy_cepst 3> <moy_lab 4> <moy_lab 5>
<var_cepst 1> <var_cepst 2> <var_cepst 3> <var_lab 4> <var_lab 5>
RACINES
a 1
Figure 3B . 3 : Initialisation des lois dans le cas d'un modèle maître-esclave simplifié à 3 états maîtres, le nombre de paramètres est 5, le nombre de paramètres maître est 2. Seules les lois correspondant à l'état maître ndeg.1 ayant pour ancêtre des états de racine "a" sont initialisées.
Dans le cadre du projet AMIBE, nous disposons de deux types de signaux : le signal acoustique et le signal articulatoire synchronisé. Le signal acoustique est échantillonné à 16 kHz, tandis que pour le signal articulatoire (issu d'un traitement d'image [Lallouache 91]), nous disposons d'un vecteur d'observations toutes les 20ms. Ce signal se compose de la largeur A et la hauteur B internes du contour des lèvres, et la surface intérolabiale S (figure 3B.4).
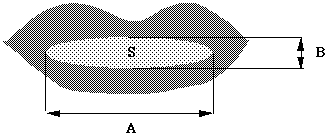
Figure 3B . 4 : Coefficients labiaux.
Le signal acoustique est segmenté automatiquement [André-Obrecht, 88] et une analyse spectrale est faite sur chaque segment : 8 coefficients cepstraux ( CC ) sont obtenus après recalage du spectre selon l'échelle Mel. Leur sont adjointes l'énergie (E) et la dérivée de ces coefficients ( Δ CC, Δ E ). Les frontières issues de la segmentation statistique sont projetées sur les signaux articulatoires. Pour chaque segment projeté, est calculée une valeur moyenne de chaque paramètre labial ainsi que les dérivées correspondantes .
Le vecteur d'observations est finalement composé de 18 coefficients de nature acoustique, de 6 coefficients articulatoires, auxquels est ajoutée la longueur du segment correspondant ( T ).
Pour fusionner les données acoustiques et articulatoires, nous avons envisagé un modèle équivalent simplifié correspondant au modèle maître-esclave suivant (figure 3B. 5) :
-- Un modèle Maître ergodique à 3 états modélisant le mouvement des lèvres.
Ces trois états représentent les trois configurations des lèvres suivantes : ouvertes , fermées et semi-ouvertes. Nous pouvons noter que les hypothèses sur ce modèle sont fortement simplificatrices : dans la réalité, le passage d'un état ouvert à un état fermé ne peut se réaliser de manière si abrupte.
-- Un modèle Esclave gauche-droite modélisant le signal acoustique.
Les unités acoustiques sont des pseudo-diphones ; le modèle esclave est organisé en une concaténation de modèles de mots, chaque modèle de mots est lui même construit à partir des modèles de pseudo-diphones (cf paragraphe III_A.4.1 page 99) .
Dans ce modèle, tous les duplicatas d'une loi reçoivent les mêmes initialisations acoustiques. Selon le numéro d'état maître auquel elles sont associées leur sont adjoints les paramètres labiaux A, B et S correspondant à des configurations de lèvres ouvertes, fermées ou à demi-ouvertes.
L'apprentissage du modèle maître-esclave se réalise par la recherche de chemin optimaux avec l'algorithme de Viterbi. Les réestimations des lois s'effectuent en deux étapes :
-- les paramètres acoustiques sont calculés de manière classique.
-- tous les paramètres labiaux des lois correspondant au même numéro d'état maître ( même critère de loi ) sont pris en compte pour faire la réestimation. Leur valeur est mise à jour dans les lois considérées.
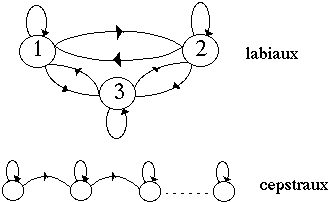
Figure 3B . 5 : MMC Maître-Esclave du projet AMIBE
Cette application est réalisée dans un environnement protégé en parole continue avec un seul locuteur. Elle est évaluée sur deux corpus de phrases :
-- Corpus des chiffres : chacune des phrases est composée de 4 chiffres connectés ou des mots "oui" ou "non". L'ensemble d'apprentissage est formé de 84 phrases ( 288 mots de base ). L'ensemble de test est formé de 35 phrases ( soit 125 mots ). L'ensemble d'apprentissage n'est pas suffisant pour apprendre correctement un nombre élevé de paramètres. Nous n'avons donc pas utilisé les dérivées des coefficients dans cette première expérience.
-- Corpus des lettres : chacune des phrases est composée de 4 lettres épelées. L'ensemble d'apprentissage contient 158 phrases ( soit 632 mots ) et l'ensemble de test se compose de 48 phrases ( soit 192 mots ).
Les données visuelles sont obtenues à partir de films pris à 50 images/secondes. Chacune de ces images doit ensuite être traitée pour extraire les paramètres labiaux que nous avons décrits ci-dessus. Ce travail est long et fastidieux, ce qui explique le faible nombre de prononciations disponibles en test comme en apprentissage.
Afin de valider l'approche "maître-esclave", nous avons comparé systématiquement les taux de reconnaissance à ceux obtenus à l'aide d'un modèle de Markov Caché global Mglob construit de manière classique ; chaque mot du langage est décrit à partir de la notion de pseudo-diphone, et chaque pseudo-diphone correspond à un MMC élémentaire. Un vecteur d'observations est traité globalement, à raison d'une loi gaussienne par transition ( matrice de covariance diagonale ).
Que ce soit dans l'approche globale ou l'approche maître-esclave le nombre de mots à reconnaître est connu a priori : 4 pour une série de chiffre et 1 pour les mots "oui" ou "non".
Le modèle global est appris avec 8 coefficients cepstraux, l'énergie du signal E, et la durée du segment T. à ceux-ci sont adjoints dans un deuxième temps.les 3 coefficients labiaux. Celui-ci est comparé à un modèle Maître/Esclave dont les coefficients labiaux font naturellement partie des paramètres initiaux.
modèle coefficients phrases / 35 mots / 125
M glob 8 CC + E + T 1 1
8 CC + E + T + A + B + S 3 3
M maître/esclave 8 CC + E + T + A + B + S 5 5
Tableau
3B . 6 : Nombre d'erreurs sur l'ensemble test en termes de phrases et mots
incorrectement reconnus, en fonction des coefficients et de la
modélisation utilisés.
Les meilleurs résultats sont obtenus avec un MMC classique M glob et 8 coefficients cepstraux (figure 3B - 6). Nous observons que le traitement segmental ne pénalise pas les performances de reconnaissance par rapport à un modèle classique centiseconde ( 1 erreur de substitution qui correspond effectivement à une erreur de segmentation ) et que l'ajout de paramètres labiaux n'entraîne qu'une petite dégradation ( 3 erreurs de substitution supplémentaires ).
Le modèle global s'avère être meilleur que le modèle Maître-Esclave ( 3 erreurs contre 5 ) mais nous devons observer que l'intervalle de confiance est trop grand pour tirer une conclusion définitive. De plus, étant donné la complexité du modèle Maître-Esclave, le nombre des paramètres à estimer est très important ( on multiplie par 3 le nombre de lois d'observations ainsi que le nombre de probabilités de transitions ) et le faible ensemble d'apprentissage dont nous disposons, ne permet pas une bonne estimation de la totalité des paramètres.
Dans une première série d'expériences, et quelle que soit l'approche envisagée, le nombre de lettres par phrase à reconnaître, égal à 4, est connu du système ; les topologies acoustiques sont obtenues à partir de la modélisation en pseudo-diphone, comme précédemment.
Cette deuxième évaluation sur le corpus des lettres épelées et connectées, nous permet d'examiner les performances du système afin de quantifier l'apport des paramètres labiaux, pour les deux sortes d'approches. Cette première série d'expériences avec ce corpus en ambiance calme a pour but d'étudier la pertinence de cet apport, ces paramètres supplémentaires pouvant n'être qu'une source de bruit.
Il est à noter que la tâche de décodage sur des lettres épelées est plus difficile en soi que la reconnaissance de chiffres. En effet, les chiffres sont composés de sons en général bien distincts et en nombre plus restreint que ceux composant les lettres de l'alphabet qui ne diffèrent parfois que par un son très proche.
Figure 3B . 7 : Taux d'erreurs en termes de lettres avec le MMC global
phrases mots
App. Test App. Test
8cc+ E 5,7 33,3 1,9 10,4
8cc+ E+ T 5,7 27,1 1,6 10
8cc+ E+ T + A 5,1 35,4 1,9 11
8cc+ E+ T + A+ ∂A 6,3 31,3 1,9 9,4
8cc+ E+ T + A+ B 6,7 33,3 1,9 10
8cc+ E+ T + A+ B+S 9,5 29,2 2,9 8,3
8cc+ E+ T + 4Δcc 6,7 31,3 2,2 9,4
8cc+ E+ T + 4Δcc+ A+ B 10,1 37,5 3,3 10,4
8cc+ E+ T + A + B+ S + 10,1 37,5 3,5 12
∂A+ ∂B+
∂S
8cc+ E+ T + 4Δcc+ A+ B+S 12 43,8 4,1 15,1
8cc+ E+ T + 4Δcc+ 9,5 41,7 3,2 16,2
A+B+S+∂A+∂B+
∂S
Tableau
3B . 8 : Récapitulatif des pourcentages d'erreurs avec le MMC
global
Le meilleur taux de reconnaissance, à savoir 91,6 % ( en taux mots, ce qui correspond à 16 erreurs ) est obtenu en utilisant la hauteur et la largeur des lèvres (figure 3B.7 modèle avec 8 coefficients cepstraux, l'énergie E, la durée T du segment, et les paramètres labiaux A et B). La matrice de confusion des lettres est donnée par le tableau 3B.9. On peut voir que l'on confond en majorité des lettres ayant des phonèmes proches, à l'exception des 3 substitutions A/R, Y/N et W/O. La suite "HE" est reconnue en "ST" et la suite "SB" en "MV".
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
A 5 1 1
B 6 1 1
C 7
D 7
E 6 1
F 7
G 5 2
H 5 1 1
I 7
J 1 5
K 4 1
L 6
M 7
N 8
O 8
P 1 7
Q 6
R 7
S 1 6
T 6
U 6
V 1 4
W 1 7
X 6
Y 5
Z 5
Tableau
3B.9 : Matrice de confusion des lettres dans l'ensemble de test pour le MMC
global
L'introduction de la surface des lèvres n'apporte pas d'information pertinente car elle est fortement corrélée aux paramètres A et B [Benoit 91]. Les dérivées des coefficients labiaux dégradent le taux de reconnaissance : une des causes principales peut être le manque de synchronisation entre les informations labiales et acoustiques, ou le manque de données d'apprentissage pour apprendre un si grand nombre de paramètres.
La figure 3B.10 donne un exemple de reconnaissance sur le meilleur modèle global ( avec les paramètres : 8 Coefficients Cepstraux, l'énergie E, la durée du segment T, et les paramètres labiaux A et B ) dont les unités à reconnaître sont des pseudo-diphones. Le signal a été segmenté automatiquement [André-Obrecht, 88] et correspond à la prononciation des lettres "M R,H Z".

Figure 3B . 10 : Exemple d'alignement des unités pseudo-diphones sur le signal avec le modèle global à partir de la segmentation. Le signal correspond à la prononciation des lettres épelées "M R H Z"
Le même protocole d'expérimentation est réalisé pour tester l'approche Maître/Esclave. Les coefficients labiaux A et B font partie des paramètres initiaux lors de l'apprentissage du modèle. Le nombre de lettres par phrase reste imposé et est égal à 4.
Figure 3B . 11 : Taux d'erreurs en termes de lettres avec le MMC Maître/Esclave
phrases mots
App. Test App. Test
4cc + A 8,8 35,4 2,8 13
8cc + E +T + A 4,4 25 1,4 10
8cc + E +T + A + ∂A 2 20,8 0,6 9,4
8cc + E +T + A + B 2,5 20,8 0,8 8,3
8cc + E +T + A + ∂A + B + 2,5 20,8 0,8 8,9
∂B
8cc + E +T + 4Δcc+ A 4,4 31,3 1,9 12
8cc + E +T + 4Δcc+ A + 4,4 35,4 1,9 13
∂A
8cc + E +T + 4Δcc+ A + B 4,4 31,3 2,2 12
8cc + E +T + 4Δcc+ A +B 4,4 35,4 2,1 11,5
+∂A +∂B
Tableau
3B . 12 : Tableau récapitulatif des pourcentages d'erreurs avec le MMC
Maître-Esclave
Le meilleur taux de reconnaissance est obtenu par le modèle dont les paramètres sont les 8 coefficients cepstraux, l'énergie E, la durée du segment T et les paramètres labiaux A et B à savoir 91,7 % ( figure 3B.11 ) en termes de mots correctement reconnus. Lorsque le nombre de paramètres augmente, les performances décroissent, la cause est très certainement liée là encore au relativement faible ensemble de données d'apprentissage par rapport au nombre de paramètres à apprendre.
La figure 3B.13 donne un exemple d'alignement sur ce modèle Maître-Esclave.

Figure 3B . 13 : Exemple d'alignement des unités pseudo-diphones sur le signal avec les états du modèle Maître et les états du modèle Esclave à partir de la segmentation. Le signal correspond à la prononciation des lettres épelées "M R H Z"
Nous avons repris le meilleur modèle Maître-Esclave dans le cadre d'une expérience de reconnaissance des lettres épelées sans connaissance a priori du nombre de lettres prononcées :
* sur l'ensemble d'apprentissage, nous avons observé 3 substitutions, 6 insertions et 1 omission, ce qui correspond à un taux d'erreurs en termes de phrases, de 4,4 % (7 sur 158), et en termes de mots, de 1,6% (10 sur 632).
* sur l'ensemble de test, nous avons observé 14 substitutions, 11 insertions dont la moitié sont des "I", ce qui correspond à un taux d'erreurs en termes de phrases, de 33,3 % (16 sur 48), et en termes de mots, de 13% (25 sur 192).
I T D I F T
G rowd rowd rowd rowd
own] own] own] own] own] own]
] ] ] ] ] ]
I N T
U R Q G H W rowd rowd
own] own]
] ]
K I
N R Z Y U Z X
rowd rowd
own] own]
] ]
I
V
rowd
own]
]
Tableau
3B . 14 : Insertions sur l'ensemble de test. Les flèches montrent
l'emplacement des insertions dans une suite de lettres
épelées.
lettre lettre à lettre lettre à
reconnue reconnaîtr reconnue reconnaîtr
e e
I U D V
L N K A
S H T E
G J D P
F Y MQ LW
A K D B
N H
Tableau
3B . 15 : Substitutions sur l'ensemble de test
Les expériences précédentes ont montré que l'introduction de paramètres labiaux ne dégradait pas un système de reconnaissance en ambiance calme. Une nouvelle série d'expériences a été menée afin d'étudier leur influence en milieu bruité. Nous nous basons sur le fait que plus le milieu est bruité, plus la reconnaissance du signal acoustique seul se dégrade. En revanche, en utilisant uniquement les informations visuelles, on obtient un taux de reconnaissance de l'ordre de 30% du point de vue perceptif. Nous allons comparer comme précédemment les résultats du modèle Global ne corrélant pas les informations visuelles et acoustiques et ceux du modèle Maître-Esclave prenant en compte la bi-modalité de ces deux sources d'informations.
Afin de réaliser cette étude, nous reprenons les expériences du corpus des lettres en bruitant artificiellement à 15 dB les fichiers contenant le signal. Le bruit utilisé est de nature "cocktail party".
Nous n'avons pas utilisé la segmentation automatique, afin de ne pas ajouter les problèmes dus aux erreurs de segmentation à notre problème initial. Les observations acoustiques sont donc centisecondes et les modèles acoustiques des unités pseudo-diphones liés à un pré-traitement segmental sont remplacés par des modèles acoustiques plus adaptés à un découpage centiseconde. Ceux-ci, inspirés de [Jouvet, 88] sont donnés dans le tableau 3B.16 .
parties 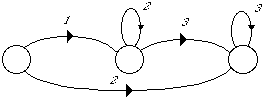 transitoires
parties stables
transitoires
parties stables 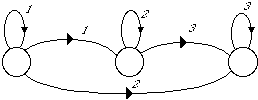 liquide /r/
liquide /r/ 
Tableau
3B . 16 : Modèles acoustiques centisecondes des unités
pseudo-diphones [Jouvet, 88]
Le nombre de lettres, c'est à dire 4, est connu du système. Etant donné que la durée du segment est maintenant constante, le paramètre T ne fait plus partie des paramètres du modèle Global et du modèle Maître-Esclave.
Dans le modèle Global, les paramètres de base sont les coefficients cepstraux auxquels nous ajoutons progressivement des paramètres labiaux et/ou acoustiques. Les résultats sont montrés par la figure 3B.17.
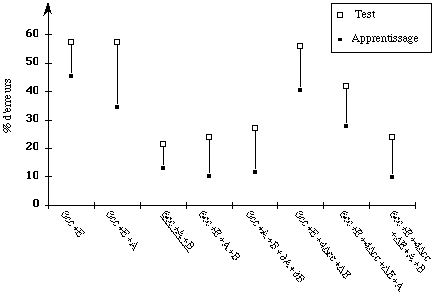
Figure 3B . 17 : Taux d'erreurs à 15dB pour le modèle Global en termes de lettres
phrases mots
App. Test App. Test
8cc + E 79,7 85,4 45,4 57,3
8cc + E + A 65,2 89,6 34,5 57,3
8cc + A + B 33,5 52,1 13 21,3
8cc + E + A + B 27,8 58,3 10,3 24
8cc + A + B + ∂A + 29,7 62,5 11,5 27,1
∂B
8cc + E + 4Δcc + ΔE 81 91,7 4,3 55,7
8cc + E + 4Δcc + ΔE + A 62,7 79,2 27,7 41,7
8cc + E + 4Δcc + ΔE + A 27,8 60,4 9,6 24
+ B
Tableau
3B . 18 : Récapitulatif des pourcentages d'erreurs en milieu
bruité à 15 dB avec le MMC global
Le meilleur taux de reconnaissance que nous obtenons est de 78,7% ( soit 41 lettres sur 192 non correctement reconnues ). Ce modèle n'utilise que les paramètres de base et les paramètres labiaux A et B. L'introduction des dérivées qu'elles soient de paramètres acoustiques ou labiaux n'apporte rien aux performances du système. Nous constatons que l'apport de l'énergie E dégrade les taux de reconnaissance en milieu bruité.
Dans le modèle Maître-Esclave, le paramètre labial A et les quatres premiers coefficients cepstraux constituent les paramètres de base. On ajoute progressivement dans les modèles Maître et Esclave les paramètres labiaux et acoustiques. Etant donné les dégradations observées dans le modèle Global, l'énergie E du signal n'a pas été retenue dans le choix des paramètres. Les résultats sont donnés dans la figure 3B.19 .
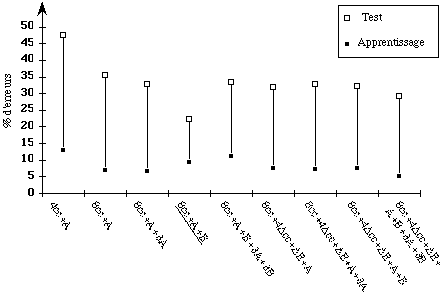
Figure 3B . 19 : Taux d'erreurs à 15 dB pour le modèle Maître/Esclave en termes de lettres
phrases mots
App. Test App. Test
4cc + A 31 83,3 13 47,7
8cc + A 19,6 68,7 7 35,4
8cc + A + ∂A 17,7 68,7 6,5 32,8
8cc + A + B 23,9 56,2 9,3 22,4
8cc + A + B + ∂A + 30,4 70,8 11,2 33,3
∂B
8cc + 4Δcc + ΔE + A 19,6 68,7 7,6 31,8
8cc + 4Δcc + ΔE + A + 19 75 7,2 32,8
∂A
8cc + 4Δcc + ΔE + A + B 19,6 78 7,4 32,3
8cc + 4Δcc + ΔE + A + B 14,6 66,7 5,1 29,2
+ ∂A + ∂B
Tableau
3B . 20 : Récapitulatif des pourcentages d'erreurs en milieu
bruité à 15 dB avec le MMC Maître/Esclave en termes de
lettres
Le meilleur taux de reconnaissance obtenu est de 77,6% ( c'est-à-dire 43 lettres incorrectement reconnues sur 192 ). Comme dans le modèle Global, les paramètres maximisant le taux de reconnaissance sont les 8 coefficients cepstraux ainsi que les paramètres labiaux A et B.
Les expériences réalisées en milieu bruité ont indiqué que les résultats obtenus avec les deux modèles Global et Maître-Esclave sont là encore comparables.
Cependant, il faut se rappeler de l'augmentation du nombre de paramètres de ces modèles dûe à une plus grande complexité des modèles acoustiques centisecondes par rapport aux modèles acoustiques segmentaux. L'ensemble d'apprentissage restant le même, ces modèles n'ont bénéficié que d'un apprentissage moindre. Si l'on tient compte du grand intervalle de confiance et de l'explosion combinatoire du nombre de paramètres du modèle Maître-Esclave par rapport au modèle Global les résultats obtenus sont alors comparables.
Afin d'étudier plus précisément ces modèles, nous réalisons actuellement des expériences basées sur une simplification des modèles acoustiques centisecondes et des unités à reconnaître moins détaillées ( comme les phonèmes par exemple ) afin de réduire le nombre de paramètres et d'en obtenir une meilleure estimation. Nous étudierons ensuite des rapports signal sur bruit plus faibles.
Pour traiter la fusion de données acoustiques et articulatoires dans un but de reconnaissance, nous avons présenté deux approches probabilistes, l'approche classique qui consiste à supposer indépendantes les informations issues des deux canaux et l'approche maître-esclave qui exploite une certaine corrélation par l'intermédiaire de liens entre les lois d'observations.
Les deux approches modèle global et modèle maître-esclave donnent des résultats très comparables dans le cadre de la reconnaissance mono locuteur de suites de chiffres connectés ou de lettres épelées :
-- 92 % de taux de reconnaissance en mots en ambiance calme
-- respectivement 79% et 78% en milieu bruité à 15 dB
L'avantage de la deuxième méthode est liée à une meilleure compréhension du phénomène labial et offre des perspectives intéressantes :
-- Au niveau maître, nous augmenterons le nombre d'états de manière à se rapprocher des études statistiques qui ont montré l'émergence de visèmes [Benoit 91].
-- Le modèle maître-esclave est, dans son actuelle implémentation, fort simplifié et certaines hypothèses sont trop fortes : le passage d'un état ouvert à celui de fermé ne se réalise pas de manière instantanée! En fonction du volume croissant de l'ensemble d'apprentissage qui nous sera ultérieurement fourni, nous complexifierons le modèle simplifié pour tendre vers le modèle exact et tester ses réelles possibilités.
-- L'étude d'une désynchronisation entre le labial et l'acoustique semble plus abordable par cette approche.
L'utilisation des paramètres labiaux a pour but de rendre plus robuste la reconnaissance automatique de parole en milieu bruité. Comme le montre le tableau 3B.21 les signaux articulatoires seuls permettent d'obtenir un taux de reconnaissance de 40% quel que soit le niveau de bruit. De plus, nous avons montré que cette information ne dégradait absolument pas les performances des systèmes actuels déjà très performants en ambiance calme.
phrases mots
App. Test App. Test
A + B 74,7 87,5 50,2 60,4
A + B + ∂A + 82,9 85,4 52,1 60,9
∂B
Tableau
3B .21 : Pourcentages d'erreurs en termes de lettres pour les signaux
articulatoires seulement avec le MMC Global
Notre objectif est maintenant de continuer nos expériences à différents niveaux de bruit avec une meilleur estimation des paramètres des modèles.
(Cette partie a été réalisée avec la participation de Nathalie Parlangeau dans le cadre de son stage de DEA)
De nombreux travaux au sein de l'équipe "Interfaces Homme Machine Parole et Texte" ont eu pour objet, ces dernières années, la segmentation automatique et l'étiquetage automatique du signal de parole en termes de classes majeures. Ils ont conduit à l'élaboration d'un système de décodage acoustico-phonétique (Segmentation Etiquetage Discontinuité SED [Kabré 91, Farhat 93]) qui consiste à transcrire le signal de parole, signal continu, en une suite discrète d'événement phonétiques : les paramètres sont de nature temporelle (énergie, taux de passage par zéro...) et le module de classification est fondé sur un ensemble de règles ; la segmentation du signal est obtenue a posteriori.
Nous avons cherché, dans un premier temps, à comparer ce type d'approche à une approche fondée sur une segmentation a priori du signal et des techniques de quantification vectorielle, sans faire intervenir aucune règle ni aucun seuil ; dans un deuxième de temps, nous avons évalué ce DAP, en alignement automatique.
En section III_C.1, nous rappelons le principe du décodage acoustico phonétique et celui de l'alignement automatique dans le cadre précis de notre étude. Nous détaillons ensuite en section III_C.2 la mise en oeuvre de l'alignement à l'aide de l'outil informatique, et les expériences réalisées sur la base de données EUROM0 [Fahrat 93] en section III_C.3.
Dans bon nombre de systèmes de reconnaissance automatique de parole dits analytiques comme dans les systèmes d'étiquetage automatique, une première étape consiste généralement à transcrire le signal acoustique en une suite d'unités élémentaires. Cette étape appelée décodage acoustico-phonétique se décompose en trois phases :
-- la paramétrisation du signal,
-- la segmentation ,
-- l'identification.
Très souvent la phase de segmentation est inexistante ou implicite.
La difficulté principale réside dans le choix de l'unité élémentaire. Dans le système SED, l'étiquetage phonétique a pour but de mettre en évidence à partir de paramètres temporels, des classes phonétiques majeures (figure 3C . 1).
Etiquette Signification
K voyelle
M voyelle grave
N voyelle aiguë
L U vocalique aigu vocalique grave
O Q occlusif voisé occlusif sourd
X fricatif de type R
F S Z fricatif faible fricatif sourd fricatif
voisé
A B attaque discontinue coda discontinu
Figure
3C . 1 : Liste des étiquettes utilisées dans le système
SED [Farhat 93]
Le système que nous proposons s'appuie sur une segmentation statistique a priori et une paramétrisation de type cepstral. Nous ne pouvons donc retenir les mêmes classes, en particulier les étiquettes de type dynamique sont éliminées (A et B). Dix étiquettes phonétiques sont définies (figure 3C . 2).
Etiquette Signification
K noyau vocalique central
M noyau vocalique grave
N noyau vocalique aigu
L consonantique voisée hautes fréquences
U consonantique voisée basses fréquences
O barre de voisement
Z fricative voisée
S fricative non voisée
Q silence
Figure
3C . 2 : Tableau des étiquettes phonétiques
L'algorithme L.B.G. [Su, 90], algorithme de type quantification vectorielle, couplé à un critère de Rissanen est appliqué aux 10 ensembles d'apprentissage des 10 étiquettes phonétiques et fournit un ensemble de références ou sous-dictionnaires pour chacune d'elles. Le dictionnaire des références est obtenu par la réunion de ces 10 sous-dictionnaires. En phase d'étiquetage, le signal est segmenté automatiquement et chaque segment est paramétrisé. Les paramètres quéfrentiels d'un segment inconnu comparés aux références du dictionnaire par la méthode du plus proche voisin associent le segment à une étiquette unique. (Des résultats sous forme de matrices de confusion, sont donnés dans [Parlangeau 93]).
K M N L U O Z S Q %
K 53 13 17 8 1 57,6
M 14 1 93,4
N 1 51 6 1 86,4
L 9 14 11 11 8 2 20,1
U 5 6 7 9 4 1 21,9
O 1 15 1 88,2
Z 1 1 3 1 26 2 2 72,2
S 2 30 2 88,2
Q 2 3 3 1 4 4 2 2 92 81,4
% 82 28 61 31 32 48 72 88 95 66,2
Figure
3C . 3 : Matrice de confusion obtenue sur le critère du 1er plus proche
voisin
Taille du dictionnaire : 17
K 2 N 2 U 2 Z 2 Q 2 M 2 L 2 O 2 S 1Figure 3C . 4 : Nombre de représentants par étiquette
L'alignement phonétique du signal sur la transcription auditive de l'expert est fondé sur une modélisation Markovienne discrète. Les observations sont discrètes et correspondent aux étiquettes décrites ci dessus, résultats du DAP. L'unité de base doit être représentative à la fois d'un type de son et de sa représentation segmentale. Certains sons peuvent être regroupés : segmentalement, ils se décomposent de manière semblable, l'identification des segments correspondants donne les mêmes étiquettes phonétiques et conduit à des lois de probabilités d'observations identiques ; mais il nous faut en revanche introduire des unités infra-phonétiques, de type explosion d'une plosive, silence de plosives. Au total, nous avons défini quinze unités de base qui correspondent à quinze modèles de Markov cachés élémentaires ( Figure 3C . 3).
La procédure d'alignement est la suivante : pour chaque phrase, la description auditive en phonèmes fournie par l'expert phonéticien est transcrite à l'aide de ces unités de base. à partir des modèles de Markov élémentaires correspondants, un réseau global est obtenu et est modifié à l'aide de règles de coarticulation.
La suite d'étiquettes phonétiques composant la phrase de test est présentée à ce réseau modifié, l'alignement s'effectue à l'aide de l'algorithme de Viterbi. En sortie, sont données les positions des frontières des phonèmes attendus. Etant donné le pré-traitement segmental, une telle frontière correspond toujours à une frontière de segment.
Unités Groupes de sons Topologie des modèles
de base
A A,E,I,O,U,Y,e  voyelles
AN AN,IN,ON voyelles
voyelles
AN AN,IN,ON voyelles  nasales
B B,D,G plosives
nasales
B B,D,G plosives  voisées
Bb Bb,Db,Gb explosion
voisées
Bb Bb,Db,Gb explosion 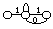 P P,T,K plosives
P P,T,K plosives 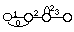 sourdes
Pb Pb,Tb,Kb explosion
sourdes
Pb Pb,Tb,Kb explosion 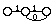 F F,S,CH fricatives
F F,S,CH fricatives 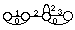 sourdes
Z Z,z fricatives
sourdes
Z Z,z fricatives 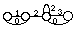 voisées
L M,N,L liquides
voisées
L M,N,L liquides 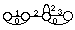 w w,y semi-voyelles
w w,y semi-voyelles 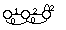 j j semi-voyelle
j j semi-voyelle 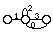 V V liquide voisée
V V liquide voisée 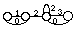 R R non voisé
R R non voisé  r R voisé
r R voisé 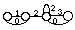 Q Silence
Q Silence 
Figure
3C . 5 : M.M.C des classes de sons
Pour mettre en oeuvre ces deux systèmes (DAP et alignement), deux types d'apprentissage sont requis, un premier pour construire le dictionnaire de références et un deuxième pour apprendre les lois discrètes des modèles de Markov élémentaires.
Dans ce but, à partir d'une segmentation automatique, un étiquetage manuel[2] des phrases avec les étiquettes phonétiques ( figure 3C. 2 ) est effectué afin de former l'ensemble d'apprentissage. Le dictionnaire de références est alors construit à partir des sous ensembles d'apprentissage ainsi obtenus.
Dans un deuxième temps, l'étiquetage manuel en phonèmes est projeté sur les segments. La mise en correspondance entre cet étiquetage et les étiquettes phonétiques obtenues automatiquement après application du dictionnaire sur chaque segment, et considérées comme observations des MMC élémentaires (figure 3C . 4), donne les ensembles d'apprentissage pour chaque MMC élémentaire.
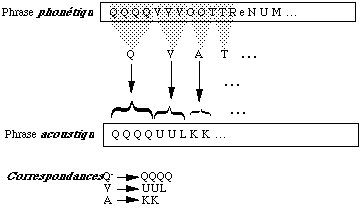
Figure 3C . 6 : Création des ensembles d'apprentissages
En phase d'alignement, d'un point de vue informatique, le compilateur traduit la phrase en un modèle MMC à partir d'un fichier texte contenant la suite de phonèmes représentant la phrase. Ce modèle est de type gauche-droite et ses unités de base sont des phonèmes.
Sont ensuite prises en compte les coarticulations par la rubrique "COART_LOCALES" ; ces règles sont liées à :
-- des phénomènes d'assimilation ( rl -> l),
-- des phénomènes de coarticulation forte (f s -> f ou s)
-- des problèmes d'omissions dues à la segmentation comme l'omission de l'explosion d'une plosive sonore (figure 3C . 7).
T R = T j O N = ON T S = T y I = I T K = K F R = F T T = T F S = F T D = D R L = L W A = A L N = N j O = O Z I = IFigure 3C . 7 : Exemple de coarticulations
A l'aide de la rubrique "CORRESPONDANCES" et des quinze modèles acoustiques élémentaires appris séparément, un réseau acoustique global est compilé (figure 3C . 8).
A partir des observations obtenues en sortie du DAP, l'algorithme de Viterbi cherche le meilleur chemin dans le réseau global. La trace du chemin donne, en utilisant les liens de parenté de chaque état et les transitions générant une loi d'observation, l'alignement de la phrase recherché.
Cet alignement pourra alors être comparé à la phrase manuellement étiquetée en phase d'évaluation.
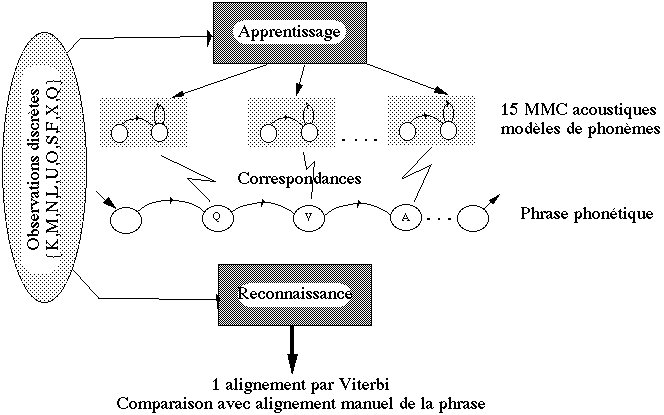
Figure 3C . 8 : Synopsis de la validation des alignements
Les expériences effectuées sont monolocuteur, le mode d'élocution est celui d'une personne demandant des renseignements par téléphone à une opératrice ( donc parole naturelle avec une syntaxe libre dans un domaine ouvert ). Le corpus d'apprentissage est constitué des dix premières phrases de la base EUROM0, sur les 23 phrases prononcées par un même locuteur. Cette base est étiquetée phonétiquement, nous avons repris exactement cet étiquetage manuel, à l'exception des plosives, compte tenu de la décomposition que nous proposons.
Les expériences ont montré l'importance du modèle de silence, aussi plusieurs évaluations sont réalisées selon le traitement effectué relatif aux pauses :
* le système Divergence1 est obtenu sans aucun traitement silence/parole des segments ; nous donnons deux types de résultats selon l'utilisation d'une projection des pauses ou non, permettant de simuler une détection exacte des débuts et fins de parole.
* dans le système Divergence 2, est effectué un traitement intermédiaire entre le module de DAP et le module d'alignement. Il consiste à confirmer les débuts et fins de parole identifiés essentiellement par l'étiquette Q et éventuellement les étiquettes U, S, X, à l'aide d'un test classique de décision utilisant comme paramètres l'énergie, le taux de passage à zéro... L'alignement est réalisé sur la seule partie du signal identifié comme de la parole ; les résultats sont donnés évidemment sans projection des pauses.
Dans les deux cas, l'ensemble test est constitué des treizes dernières phrases prononcées par le même locuteur qu'en apprentissage.
Pour analyser les résultats, il faut garder en mémoire que, sur ce type de données :
-- le taux de sursegmentation sur ce corpus est de 2,2 : 2,2 segments sont observés en moyenne par phonème,
-- et le coefficient de qualité, à savoir le pourcentage de frontières phonétiques étiquetées manuellement placées à moins de 20 ms d'une frontière détectée automatiquement est de 93 % .
Corrects Erreurs Omissions
+/-20 +/-20
ms (%) ms (%)
Divergence1 ss 71 27 2
post-trait ss
pauses
Divergence1 avec 73 24 2
pauses
Divergence2 74 23 2
post-trait ss
pauses
Figure
3C . 9 : Résultats obtenus avec les différentes versions du
système Divergence.
Les rares omissions sont dues à des erreurs de segmentation. Et les erreurs qui sont synonymes d'un décalage important entre l'étiquetage manuel et l'étiquetage automatique peuvent s'expliquer de deux manières différentes :
* dans le module d'alignement, sont prévues des coarticulations telles que /w a/ = /a/, ou des clusters tels que /t r/ = /tr/ où /tr/ apparaît comme une unité. Si une telle coarticulation est prise en compte, la frontière entre les deux sons initiaux ne peut être trouvée. Se pose alors le problème de savoir s'il faut à tout prix trouver cette frontière dans un but de reconnaissance automatique ou de synthèse : la réponse est certainement négative.
* l'étiquetage en classes majeures est certainement trop rudimentaire pour arriver à une étiquetage phonétique fin. Dans le cas de deux voyelles adjacentes, les étiquettes issues du DAP sont de type K, M ou N, et le modèle markovien est identique pour les deux sons. Il en résulte que le positionnement de la frontière médiane est aléatoire si aucune autre information n'est fournie (la durée des sons par exemple).
Il faut de plus rappeler que le corpus d'apprentissage est limité et monolocuteur. Cette expérience ne peut être considérée que comme une expérience préliminaire de faisabilité. Nous envisageons plusieurs prolongements de cette étude (cf Chapitre IV page 155 ) au niveau du Décodage Acoustico-Phonétique et au niveau de l'alignement automatique.
(Cette application a été développée avec Philippe Depambour dans le cadre de son stage de DEA).
L'objectif de cette étude est de proposer un post-traitement des N-meilleures solutions trouvées par un système de reconnaissance automatique de parole, mettant en oeuvre une approche markovienne standard et une analyse centiseconde de type cepstral. Le but est d'améliorer les performances de ce système. En effet, si la solution correcte n'est pas forcément celle de probabilité maximale, choisie par le système, elle correspond néanmoins à un chemin de probabilité élevée. Il s'ensuit que si l'on peut extraire au cours d'une première phase de reconnaissance les chemins syntaxiquement différents et de probabilité élevée, un traitement complémentaire doit permettre d'atteindre de manière plus satisfaisante la solution correcte. Cette idée a été exploitée par le CNET [Lockbani, 93], [Boiteau, 93] ; nous proposons d'étudier la complémentarité d'un traitement segmental effectué a priori.
Le principe repose sur l'existence de deux systèmes de reconnaissance automatique de parole utilisant une approche markovienne qui diffèrent de par leur pré-traitement : l'analyse est centiseconde pour le système PHIL90 du CNET, l'autre est segmentale. La comparaison de ces deux systèmes [André-Obrecht, 93] montrent que les performances sont comparables dans le cas d'une application de type mots connectés, petit vocabulaire, indépendant du locuteur. Les erreurs ne sont pas identiques et une combinaison adéquate des deux approches doit permettre de réduire le taux d'erreurs.
La procédure de reconnaissance envisagée est la suivante :
1) Le signal fait l'objet d'une première analyse centiseconde ; les observations sont placées en entrée du système PHIL90.
2) L'algorithme de Viterbi couplé à un algorithme A* [Lokbani, 93] permet d'obtenir les N-meilleures solutions correspondant à cette analyse.
3) Un MMC segmental est construit à partir de MMC segmentaux élémentaires pré-appris, pour modéliser ces N meilleurs mots.
4) Le signal initial est segmenté et les observations sont placées en entrée du MMC segmental réduit.
La solution fournie par ce dernier MMC est la solution recherchée (figure 3D . 1).
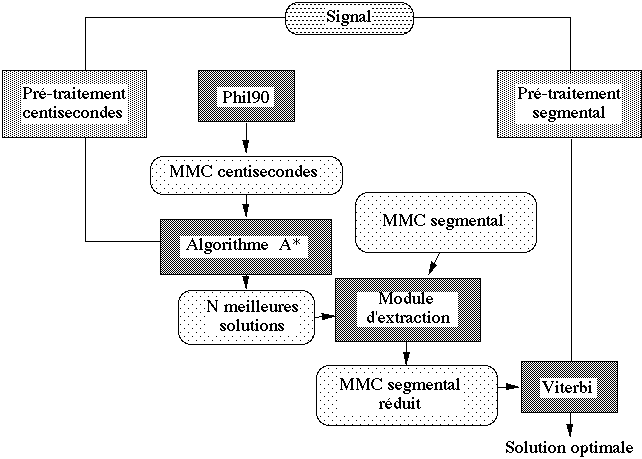
Figure 3D . 1 : Synopsis du post-traitement
Un MMC segmental global représentant l'application traitée, à savoir la reconnaissance des 500 mots les plus courants du français ( corpus CNET ) est construit et appris comme il a été indiqué au chapitre III A.5 ( page 103 ). Les unités phonétiques retenues sont les pseudo-diphones car ils produisent une bonne adéquation avec le pré-traitement segmental.
Pour accéder à la reconnaissance au travers du MMC segmental réduit, nous avons deux possibilités :
-- utiliser le MMC global segmental et un algorithme de reconnaissance dans le sous réseau correspondant à une liste de mots, à savoir celle des N meilleures solutions, ( nous appelons cette reconnaissance, dont on réduit l'espace de recherche, une reconnaissance forcée )
-- extraire après apprentissage du réseau global segmental et avant toute phase de reconnaissance, les sous réseaux correspondants à des unités intermédiaires, construire de manière dynamique pour tout nouveau N-uplet de solutions le réseau segmental et appliquer l'algorithme de Viterbi standard.
Nous avons mis en oeuvre les deux possibilités afin d'enrichir l'outil informatique. La première option est directement réalisable avec le logiciel présenté. Dans le deuxième cas, nous avons construit un module d'extraction de sous réseaux à partir d'un réseau global. Cette tâche est rendue aisée étant donné la structure des réseaux et les liens de parenté qui existent entre chaque état et sous réseau. A partir d'une liste d'états, ce module sélectionne chaque sous-réseau correspondant à partir de la sauvegarde du réseau global [Depambour, 94]. Il est indépendant de l'application développée et du type d'unités recherchées : il permet d'accéder aussi bien au modèle d'un mot complet ( comme dans le cas de l'application présente, où les états listés correspondent au niveau lexical et aux N meilleurs mots), qu'au modèle d'une unité de base (pseudo-diphone ...). Cet outil nous permet de constituer une bibliothèque d'unités de base à partir d'un réseau de Markov global déjà appris.
Le compilateur de réseaux peut reprendre les modules de cette bibliothèque de la même manière que précédemment (chapitre 3C) en utilisant la rubrique "Correspondances" et les insérer dans un réseau de Markov dont le niveau acoustique n'aura ainsi ni à être décrit, ni à être appris.
Nous avons travaillé sur le sous-corpus de 50 mots tirés parmi les 500 mots les plus courants du français (description chapitre III_A page 103). Rappelons que les ensembles d'apprentissage et de test sont multi locuteurs (10 locuteurs) : 2 répétitions de chaque mot par locuteur forment l'ensemble d'apprentissage et une troisième prononciation compose l'ensemble de test. Les mots ont été enregistrés à travers le réseau téléphonique avec les conditions sévères que nous avons déjà indiquées : échantillonnage à 8 kHz, bande passante de 3,3 kHz.
Pour étudier la faisabilité de notre approche, nous limitons l'application à la reconnaissance d'un vocabulaire de 50 mots. Nous apprenons quatre modèles segmentaux globaux en utilisant pour chaque segment, 4 familles de coefficients :
-- 8 MFCC + T (durée du segment)
-- 8 MFCC + T + E
-- 8 MFCC + 4 Δ MFCC + T
-- 8 MFCC + 4 Δ MFCC + T + E + Δ E.
Les résultats de la première phase de reconnaissance nous sont fournis par le CNET :
-- le système global centiseconde qui permet de reconnaître le vocabulaire des 500 mots est construit et appris à l'aide de PHIL90, en utilisant un modèle par mot et une analyse cepstrale complète sur chaque trame de signal (8MFCC, E, 8 Δ MFCC, Δ E, 8 Δ Δ MFCC, ΔΔ E),
-- pour chaque mot de l'ensemble de test, les 50-meilleures solutions du CNET obtenues au travers du modèle global centiseconde sont extraites.
Parmi ces 50 meilleurs mots, nous ne retenons que les mots appartenant à notre lexique de 50 mots, nous construisons le modèle segmental réduit correspondant et effectuons segmentation, paramétrisation segmentale, et reconnaissance.
Il est difficile de comparer nos résultats au taux de reconnaissance du CNET qui se rapporte au modèle global centiseconde des 500 mots. Nous donnons donc pour chaque type de paramétrisations (figure 3D . 2), le taux d'erreurs obtenu par le modèle segmental global sans sélection des N meilleures solutions sur l'ensemble d'apprentissage (colonne Apprentissage) et sur l'ensemble test (colonne Test) ainsi que le taux d'erreurs obtenu après post-traitement réalisé comme il a été décrit précédemment.
Apprentissage Test Post-traitemen
t
8 MFCC + T 2.97 % 6.54 % 4.9 %
8 MFCC + T + E 2.87 % 7.7 % 4.9 %
8 MFCC + 4 Δ MFCC + T 2.87 % 6.13 % 5.11 %
8 MFCC + 4 Δ MFCC + T + E + 3.38 % 8.18 % 5.52 %
Δ E
Figure
3D . 2 : Taux d'erreurs obtenus à partir des modèles segmentaux
globaux et réduits.
Ces premiers résultats sont encourageants, une réduction du taux d'erreurs de plus de 15 % est observée, mais il convient d'être prudent : nous n'avons utilisé qu'un sous vocabulaire de 50 mots. Pour être convaincant, il nous faut traiter les 500 mots et comparer les résultats avec les taux de reconnaissance du CNET. Ce projet doit être complété, l'expérimentation est longue et se heurte actuellement à l'écriture fastidieuse et longue du modèle segmental global représentant les 500 mots.
Le monde des chercheurs est un monde de spécialistes, et lorsque le thème de recherche est pluridisciplinaire, la tâche de chacun se complexifie : compte tenu du niveau de connaissances acquises dans les différents domaines, il est impossible qu'un spécialiste en traitement du signal soit aussi spécialiste en informatique, comme il est ridicule de vouloir qu'un spécialiste en informatique soit un probabiliste parfait. Lorsqu'il s'agit d'un sujet pluridisciplinaire, le chercheur doit avoir acquis quantité de connaissances dans chacun des domaines concernés, mais doit rester un spécialiste de son propre domaine. Néanmoins, si l'on prend le cas particulier de la reconnaissance automatique de la parole, la personne traitant le signal, le probabiliste, le phonéticien ne pourront avancer aucune idée nouvelle, ni faire preuve d'aucune audace... sans un outil puissant en informatique ; il leur faut non seulement des logiciels qui permettent d'utiliser les modèles traditionnels, mais il leur faut aussi un outil suffisamment ouvert pour qu'avec simplement un niveau d'initié en informatique, ils puissent eux mêmes créer leurs modèles et les évaluer correctement.
La revue des différents systèmes de reconnaissance de parole montre que l'approche markovienne est actuellement largement privilégiée, mais les MMC que l'on emploi traditionnellement sont des modèles trop rigides. La fusion de données, la modélisation d'informations suprasegmentales et segmentales, articulatoires et acoustiques... font appel à des modèles dérivés des MMC classiques, mais les logiciels tels que PHIL90, HTK version 1.4, sont trop rigides pour les réaliser.
C'est pourquoi nous nous sommes intéressés au développement d'un logiciel permettant de créer des réseaux probabilisés, de les gérer et de les exploiter en apprentissage et en reconnaissance. Nous avons montré comment la structuration des réseaux et en particulier les liens entre les réseaux permettaient d'accéder à différentes applications.
Nous avons ensuite traité plusieurs applications pour valider notre logiciel tout en étudiant des problèmes plus fondamentaux en reconnaissance automatique de parole :
-- au cours d'une application de type "reconnaissance de mots isolés, multi-locuteur", nous avons eu recours à un pré-traitement segmental et la notion de classes majeures afin de réaliser un filtrage lexical et un système de reconnaissance en deux phases.
-- nous avons traité le problème de l'alignement temporel automatique du signal acoustique sur une chaîne symbolique et le problème de post-traitement en reconnaissance automatique. Ces expérimentations nous ont permis d'apprécier la flexibilité du logiciel et de le compléter.
-- dans l'application réalisée dans le cadre du projet AMIBE, nous avons montré d'un point de vue logiciel comment étendre la définition des réseaux, adapter les programmes de reconnaissance et d'apprentissage à des modélisations plus complexes. Du point de vue recherche en reconnaissance, nous avons abordé le problème de fusion de données en synchronisant données acoustiques et données labiales.
Les résultats obtenus dans le cas de chaque étude sont très encourageants, mais ils restent encore insuffisants : dans les délais impartis d'une thèse (3 ans), il est impossible de fournir un tel outil logiciel correct et des expériences scientifiques concluantes. Les perspectives sont donc nombreuses comme nous allons essayer de le préciser.
Les perspectives qui font directement suite à l'ensemble de ce travail sont celles d'un groupe de recherche : elles sont de deux natures, l'une d'ordre logiciel, et l'autre d'ordre scientifique au niveau de la reconnaissance automatique de la parole.
Du point de vue scientifique, notre équipe s'oriente actuellement vers deux axes principaux de recherche, le décodage acoustico-phonétique intégrant des informations suprasegmentales et segmentales, et la fusion de données issues de plusieurs capteurs (suite du projet ACCOR) ou de traitements multiples (formants, cepstre). Les modèles statistiques que nous sommes donc amenés à développer, sont des modèles parallèles corrélés ou synchronisés. Ces modèles peuvent être multi-niveaux : soit leur réalisation est issue d'assemblages de réseaux élémentaires ( ce que nous appelons réseaux multi-niveaux compilés, cf IV.2.2 page 157 ), soit elle consiste en un ensemble de liens entre des réseaux indépendants ( ce que nous appelons réseaux multi-niveaux non compilés cf IV.2.3 page 158 ).
L'activité logicielle sera menée en parallèle avec les expérimentations de reconnaissance.
Au cours de cette thèse, nous avons étudié le modèle maître-esclave et proposé un modèle équivalent d'après [Brugnara, 92]. Il nous faut reprendre cette étude afin de gérer réellement la dépendance entre deux modèles de type MMC. Il faut étudier quel type de fusion nous voulons créer entre de tels réseaux :
-- une fusion de type produit de mesures probabilistes [Gales 94],
-- une liaison de type maître-esclave entre états ,
-- une liaison de type temporelle en proposant une fonction de désynchronisation.
-- ...
Selon le type de fusion envisagé, nous adapterons les procédures ; le champ d'expérimentation demeure le traitement des signaux articulatoires et acoustiques.
Dans les applications que nous avons développées, nous construisons des réseaux à plusieurs niveaux et une compilation de ces niveaux. A l'issue de cette opération, un niveau est défini comme actif, le niveau acoustique, il est le seul parcouru par les algorithmes d'alignement et de reconnaissance.
Dans les niveaux intermédiaires, peuvent être introduits des contraintes.
Il peut s'agir :
-- de contraintes symboliques telles que les contraintes phonologiques au niveau phonétique,
-- de contraintes probabilistes en émettant des observations de nature suprasegmentale, telle que la durée des sons (figure 4 . 1).
Actuellement seule la prise en compte de contraintes symboliques est réalisée.
Pour prendre en compte les contraintes probabilistes, nous envisageons de modifier les algorithmes d'apprentissage et de reconnaissance en spécifiant les observations, leur échelle de temps et leur niveau. Une interaction entre les différents niveaux est facilitée en utilisant les liens de parenté entre les états de différentes générations dans un modèle.
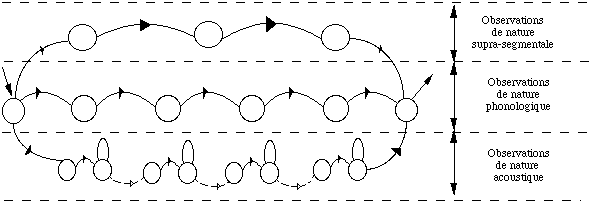
Figure 4 . 1 : Schéma d'un réseau d'observations multi-niveaux
Nous pouvons citer comme exemple le TLHMM ( décrit § I.5.2 page 39 ) de Nelly Suaudeau [Suaudeau, 94a] à deux niveaux : le niveau phonétique pilote directement le paramètre de la durée des sons. Notre première application concernera l'introduction de paramètres supra segmentaux en décodage acoustico phonétique.
Dans les applications de reconnaissance de type grands vocabulaires, parole continue, il n'est pas possible d'utiliser un réseau global de l'application (temps calcul, place mémoire). Pour de telles applications, les réseaux sont partiellement compilés pour donner des réseaux élémentaires reliés entre eux à l'aide de la rubrique "Correspondances".
Il faut pour accéder à ce type d'application exploiter la fonction de liens entre les réseaux au sein des algorithmes de Viterbi ou de Baum-Welch ( classiques et multi-niveaux ) dans les phases de reconnaissance ou d'apprentissage.
Figure 4 . 2 : Schéma d'un réseau multi-niveaux non compilé
L'intérêt secondaire de cette démarche sera d'accéder à des MMC élémentaires représentant des unités de base pouvant être extraites de l'apprentissage de réseaux modélisant des applications différentes. Ces unités pourraient ainsi acquérir un caractère plus général.
Par exemple, le modèle d'un /a/ pourra être utilisé pour l'apprentissage d'une application de lettres épelées et pour l'apprentissage d'un système de mots isolés. Cette unité bénéficiera de deux apprentisages complémentaires et sera moins dépendante d'une application.
Lors de ces nombreux développements, il sera indispensable de maintenir une grande cohérence et une grande rigueur au niveau des structures. Nous pensons que celles proposées jusqu'ici sont suffisamment simples et générales pour maintenir, au cours des extensions proposées, l'unité du logiciel et sa simplicité d'emploi vis à vis de l'utilisateur.
Les limites que nous rencontrerons seront certainement le reflet du manque de cohérence entre la structure des modèles, les outils qui lui sont associés et l'utilisation qui leur est destinée. Nous espérons que cette préoccupation sera toujours présente lors de nouveaux développements dans les équipes présentes et à venir.
[André-Obrecht, 88] R. André-Obrecht : A new statistical approach for the automatic segmentation of continuous speech signals, IEEE Trans. on Acoustics, Speech, Signal Processing, Vol. 36, ndeg.1, janvier 1988.
[André-Obrecht, 90] R. André-Obrecht : Reconnaissance automatique de la parole à partir de segments acoustiques et de modèles de Markov cachés, XVIIIièmes JEP, Montréal, Mai 1990.
[André-Obrecht, 93] R. André-Obrecht : Segmentation et parole ? , Documents d'habilitation, Université de Rennes I , Juin 1993
[André-Obrecht, 94] R. André-Obrecht : Les sons de la parole : description, paramétrisation et reconnaissance, Université d'Eté de Physique, Le Mans, Juillet 1994
[Anglade, 92] Y. Anglade, D. Fohr, J-C. Junqua : A robust discrimination method based on slectively trained neural networks , Proc. ESCA tutorial and research workshop on speech in adverse conditions, Cannes-Mandelieu, Novembre 1992, Crin 92-R-191.
[Austin, 92] S. Austin, G. Zavaliagkos, J. Makhoul, R. Schwartz : Speech recognition using segmental neural nets , IEEE 1992.
[Bamberg, 91] P Bamberg, A. Demedts, J. Elder, C. Huang, C. Ingold, M. Mandel, L. Manganaro, S. van Even : Phoneme-based training for large vocabulary recognition in six european languages, proc. 2deg. European Conference on Speech Communication an Technology, pp 175-181, Genova, Italy, 1991.
[Baker, 74] J. M. Baker : The DRAGON system : an overview, Proc. IEEE Trans. Acoust., Speech and Signal Proc., Vol 23, pp 24-29.
[Baker, 89] J. M. Baker : Dragon Dictate TM-30K : natural language speech recognition with 30000 words, Eurospeech, 1989.
[Baker, 92] J.M Baker : Large voacbulary recognition of Wall Street Journal sentences at Dragon system, Proc. DARPA Speech and Natural Language Workshop, Harriman, NY, pp. 387-392, 1992.
[Baker, 93] J.M Baker : Using speech recognition for dictation and other large vocabulary applications, Joint ESCA-NATO/RSG.10 Tutorial and Research Workshop on Applications of Speech Technology, Lautrach, 16-17 September 1993
[Baum, 72] L. E. Baum : An inequality and associated maximizations technique in statistical estimation for probabilistic functions of a Markov process, In-equalities,3,1-8
[Basseville, 83] M. Basseville, A. Benveniste : Design and comparative study of some sequential jump detection algorithms for digital signals, IEE Trans. on ASSP, Vol. ASSP 31, ndeg. 3, pp 521-535, June 1983
[Béchet, 94] F. Béchet : Système de traitement des connaissances phonétiques et lexicales : application à la reconnaissance de mots isolés sur de grands vocabulaires et à la recherche de mots cibles dans un discours continu , Thèse de 3deg. cycle, Université d'Avignon et des Pays du Vaucluse, 1994
[Bellman, 57] R. Bellman : Dynamic programming , Princeton University Press, 1957
[Boiteau, 93] D. Boiteau : Application de méthodes statistiques et connexionnistes au post-traitement segmental des N-meilleures solutions , L'interface des mondes réels et virtuels, pp 325-334, Mars 1993
[Bonneau, 86] A. Bonneau, G. Mercier, M. Gérard, M. Rossi : Le décodage acoustico-phonétique à l'aide du sytème expert SERAC-IROISE, XVèmes JEP, Aix-en-Provence 1986.
[Bourlard, 92] H. Bourlard : Reconnaissance automatique de la parole : modèles stockastiques et/ou modèles connexionistes ? , XIX JEP, Bruxelles , pp 499-506, Mai 1992
[Brugnara, 92] F. Brugnara, R. De Mori, D. Guiliani, M. Omologo : A family of Parallele Hidden Markov Models, ICASSP 92, San Francisco, 1992.
[Brown, 92] FP.F. Brown, V.J. Della Pietra, P.V. De Souza, J.C. Lai : Class-Based n-gram models of natural language, Comp. Ling, Vol.18,ndeg.4, p 467, 1992.
[Caelen, 86] J. Caelen , N. Vigouroux : Producing and organizing phonetic knowledge from acoustic facts in multi-level data-information, ICASSP 86, Vol. 2, pp 1209-1212, 1986
[Caelen, 88a] J. Caelen, H. Tattegrin : Le décodeur acoustico-phonétique dans le projet DIRA, XVIIèmes JEP, pp 115-121, Nancy 1988
[Caelen, 88b] J. Caelen : Meta-stratégie en reconnaissance dans le projet DIRA, XVIIèmes JEP, pp 173-179, Nancy 1988
[Calliope, 89] CALLIOPE : La parole et son traitement automatique, édition Masson , 1989
[Carré, 91] R. Carré, J.F. Dégremont, M. Gross, J.M. Pierrel, G. Sabah : Langage humain et machine, Presse du CNRS, 1991
[Cerf-Danon, 91] H. Cerf-Danon, S. De Gennaro, M. Ferretti, J. Gonzalez, E. Keppel : Tangora - A large vocabulary speech recognition system for live languages , proc. 2deg. European Conference on Speech Communication and Technology, pp 183-192, Genova, Italy, 1991
[Celeux, 92] G Celeux , J. Clairambault, Estimation de chaînes de Markov cachées : méthodes et problèmes, Journées thématiques CNRS sur les approches markoviennes en signal et images, Septembre 1992
[Cheng, 92] Y. Cheng, D. O'Shanghenessy, V. Gupta, P. Kenny, M. Lenning, P. Mermelstein, S. Parthasarathy : Hybrid segmental-LVQ/HMM for large vocabulary speech recognition, proc. IEEE ICASSP, Vol 1, pp 593-596, San Francisco, CA, USA.
[Cohen, 74] P. S. Cohen et R. L. Mercer, The phonologic component of an ASR systtem , Proc IEEE Symposium Speech Recognition, pp 177-188.
[Depambour, 94] Ph. Depambour: Post-traitement segmental dans un système de reconnaissance automatique de la parole, Rapport de D.E.A., Université Paul Sabatier, Toulouse III, 1994
[Deng, 90a] L. Deng, V. Gupta, M. Lennig, P. Kenny et P. Mermelstein : Acoustic recognition component of an 86,000-word speech recognizer, Proc. Internat. Conf. Acoust. Speech Signal Process., Albuquerque, NM, pp 741-744, 1990.
[Deng, 90b] L. Deng, D.Braam : Context-dependent Markov model structured by locus equations : Applications to phonologic classification, JASA, pp 2008-2025, Octobre 1994
[Derouault, 84] A.M. Derouault, B.Mérialdo : Langage modeling at the syntactic level, 7th International Conference on Pattern Recognition, pp 1373-1375, Montreal, Août 1984
[Fant, 60] G. Fant : Acoustic theory of speech production with calculations based on X-ray studies of Russian articulations, Edition Mouton & Co, 1960
[Farhat, 93] A. Farhat : Segmentation en événements phonétiques et modèles HMM pour l'étiquetage phonotypique, Thèse Informatique de 3deg. cycle, Université Paul Sabatier Toulouse III, 1993
[Ferrané, 91] I. Ferrané : Base de données et de connaissances lexicales morphosyntaxiques, ,Thèse de l'Université Paul Sabatier de Toulouse, Septembre 1991
[Fissore, 89 ] F. Fissore, P. Laface, G. Micca et R. Pieraccini : Lexical access to very large vocabulary, IEEE Trans. Acoust. Speech Signal Process, Vol. ASSP-37, ndeg. 8, PP. 1197-1213, 1989.
[Flandrin, 93 ] P. Flandrin : Temps-Fréquences ,Editions Hermès, 1993
[Fohr, 86] D. Fohr : APHODEX : Un système expert en décodage acoustico-phonétique de la parole continue, Thèse de doctorat, Université de Nancy I, 1986
[Fornay, 73] D.R. Forney, The Viterbi Algorithm, Proc IEEE, Vol 61, ndeg. 3, Mai 1973
[Gauvain, 82] J.L. Gauvain : Reconnaissance de mots enchaînés et détection de mots dans la parole continue, Thèse de 3deg. cycle, Orsay, Juin 1982
[Gagnoulet, 82] C. Gagnoulet, M. Couvrat : SERAPHINE : A connected word recognition system, Proc IEEE ICASSP-82 Paris, pp 887-890, 1982
[Gales, 94] M.F.J. Gales, S.J. Young : Parallel model combinaison on a noise corrupted resources management task, pp 255-258, ICSLP-94, Yokohama, Japon, Septembre 1994
[Gauvain, 94] C-H Lee, J.L. Gauvain, R. Pieraccini an d L.R. Rabiner : Large Vocabulary speech recognition using subword units, Speech Communication 13 ( 1993 ) pp 263-279, Reconnaissance de la Parole, Présentation de travaux en vue d'obtenir l'Habilitation à diriger des Recherches,CNRS Orsay , Janvier 1994
[Gillet, 84] Gillet, Gilloux, Hautin, Mercier, Simon, Tarridec, Vailly : SERAC : un système expert en reconnaissance acoustico phonétique. 4ième congrès RFIA AFCET, janvier 1984, tome 2, pp 99-112.
[Gilloux, 84] M. Gilloux, G. Mercier, C. Tarride , Un système expert pour la reconnaissance de parole, Colloque international d'intelligence artificielle de Marseille
[de Ginestel-Mailland, 93a] : A. de Ginestel-Mailland, G. Pérennou, M. de Calmès : Une approche de la phonologie en reconnaissance de la parole, 2ièmes Journées Internationales "L'interface des mondes réels et virtuels", Montpellier, 22-26 mars 1993, pp 345-354.
[de Ginestel-Mailland, 93b] : A. de Ginestel-Mailland, M. de Calmès, G. Pérennou : Multi-level transcription of speech corpora from ortographic form, Proceedings of Eurospeech 93, Berlin, Septembre 1993.
[de Ginestel-Mailland, 94] : A. de Ginestel-Mailland, G. Pérennou, M. de Calmès : Apprentissage d'une composante phonologique à partir d'un corpus transcrit , Actes du Séminaire Reconnaissance, Nancy , Mars 94.
[El-Bèze, 87] : M. El-Bèze : Un pré-filtre syllabique, Actes du 6ième Congrès RFIA AFCET, ANTIBES , 16-20 Novembre 1987, pp 391-399.
[Haton, 91] : J-P Haton , J-M Pierrel, G Pérennou , J Caelen , J-L Gauvain , Reconnaissance Automatique de la Parole, AFCET, édition DUNOD Informatique, 1991
[Huang, 93] : X.D. Huang : The SPHINX-II recognition speech system : an overwiev, Comput. Speech Language, Vol. 7, Ndeg. 2, pp. 137-148, 1993.
[Jacob, 94 a] : B. Jacob , R. André-Obrecht : Sub-dictionary statistical modeling for isolated word recognition, ICSLP 94, Vol. 2, pp 863-866, Yokohama, 1994
[Jacob, 94 b] : B. Jacob , R. André-Obrecht : Reconnaissance de la parole dans le cadre de très grands vocabulaires, 3deg. Congrès Français d'Acoustique de la SFA, Vol. 1, pp 489-492, Toulouse, 2-6 mai 1994
[Jacob, 95 a] : B. Jacob , C. Sénac, R. André-Obrecht , F. Pellegrino : Improving speech recognition with multimodal articulatory acoustic HMMs, 13th ICPhS, Stockholm, 13-19 août 1995
[Jacob, 95 b] : B. Jacob , N. Parlangeau, R. André-Obrecht : Fusion de données acoustiques et articulatoires en reconnaissance de la parole, 15deg. Colloque GRETSI sur le traitement du signal et de l'image, Tome 1, pp 365-368, Juan-les-Pins,18-22 septembre 1995
[Jacob, 96 ] : B. Jacob, R. André-Obrecht : Des mots sur les lèvres, RFIA 96 : 10 ième Congrès Reconnnaissance des Formes et Intelligence Artificielle, Rennes, 16-18 Janvier 1996
[Jardino, 94] M. Jardino & G. Adda : Language modelling for CSR of large corpus using automatic classification of words, ICASSP 93, pp 1191-1194, Vol. 1, 1994
[Jelinek, 75] F. Jelinek : A fast sequential algorithm using a stack , IBM Research Development, Vol 13, pp 675-685.
[Jelinek, 85] F. Jelinek : The development of an experimental discrete dictation recognizer, Proc. IEEE, Vol. 73, pp. 1616-1624,1985.
[Jouvet, 86] D. Jouvet, J. Monné, D. Dubois : A new network based speaker independent connected word recognition system., ICASSP, Tokyo 1986.
[Jouvet, 88] D. Jouvet, Reconnaissance de mots connectés indépendamment du locuteur par des méthodes statistiques, Thèse de 3deg. cycle, Juin 1988
[Jouvet, 91] D. Jouvet, K. Bartkova, J. Monné : On the modelization of allophones in an HMM based speech recognition sytem, Proceedings of Eurospeech 91, Genova, Septembre 1991, pp 923-926.
[Jouvet, 94] D. Jouvet, M. Dautremont, A. Gossart : Comparaison des Multi-Modèles et des Densités Multi-Gaussiennes pour la Reconnaissance de la Parole par Modèle de Markov, 20ième JEP, Trégastel, France, pp159-164, 1-3 Juin 1994.
[Jourlin, 94] P.Jourlin : Apport des mouvements labiaux en reconnaissance de la parole Mémoire de DEA Informatique et Mathématique, Université d'Avignon et des Pays du Vaucluse.
[Kabré, 91] H. Kabré : Décodage acoustico-phonétique multilingue : système à base de connaaissances et étiquetage automatique de corpus de parole, Thèse Informatique de 3deg. cycle, Université Paul Sabatier Toulouse III, 1991
[Kenny, 93] P. Kenny, P. Labute, Z. Li, R. Hollan, M Lennig, D. Oshaughnessy : A new fast match for very large vocabulary continuous speech recognition, Proceedings ICASSP 93.
[Kunt,91] M. Kunt,: Techniques modernes de traitement numérique des signaux, Presses polytechniques et universitaires Romandes, 1991
[Lacouture, 93] R. Lacouture, Y. Normandin : Efficient lexical access strategies, Proc. Eurospeech, pp 1537-1540, Berlin 1993
[Lamel, 92] L.F. Lamel et J.L. Gauvain : Speaker independent phone recognition using BREF, Proc. DARPA,Speech and Natural Language Workshop, Harriman, New-York, 23-26 February 1992
[Lamel & Gauvain, 92] L.F. Lamel et J.L. Gauvain : Coninuous Speech recognition at LIMSI, Proc. DARPA Continuous Speech Recognition Workshop, Stanford, pp. 77-82, 1992.
[Lee, 88] C.H. Lee, F.K. Soong, B.H. Juang : A segment model based approach to speech recognition, ICASSP, 1988
[Lee, 88a] K.F. Lee, H-W Hon, Large vocabulary speaker independent continuous speech recognition using HMM. IEEE transactions on Acoustics,Speech and Signal Processing, NewYork, april 88, pp123-128.
[Lee, 88b] K.F. Lee, H-W Hon, Speaker independent Phoneme Recognition Using HMM. Tech. report, CMU, January 1988.
[Lee, 89] K.-F. Lee : Automatic Speech Recognition - The development of the SPHINX-System ( Kluwer Academic Publishers, Boston ).
[Lee, 90a] K. F. Lee, H. W. Hon, R. Reddy : An overview of the SPHINX speech recognition system, IEEE transactions on Acoustics,Speech and Signal Processing, January, 1990
[Lee, 90b] K. F. Lee, L.R. Rabiner, R. Pieraccini et J.G. Wilpon : Acoustic modeling for large vocabulary speech recognition, Comput. Speech Language, Vol. 4, Ndeg.2, pp. 127-165, 1990.
[Lee & Soong, 88] K. F. Lee : The conversational computer : an Apple perspective, 3rd Eurospeech, Berlin, pp 1377-1384, 1993.
[Levinson, 85] S. Levinson : Structural methods in automatic speech recognition , proc. IEEE, Vol. 73, ndeg.11, 1985
[Liporace, 82] L.A. Liporace : Maximum likelihood estimation for multi-variate observations of Markov sources, proc. IEEE trans IT, Vol. 28, ndeg.5, pp 729-734, 1982
[Ljolje, 92] A. Ljolje, M. D. Riley: Optimal speech recognition using phone recognition and lexical access, Proceedings ICSLP 92,Banff, Canada, pp.313-316, 1992.
[Lockwood, 94] P. Lockwood, P. Alexandre, Root adaptative homomorphic deconvolution schemes for speech recognition in noise, ICASSP 94, Adelaïde, Avril 1994
[Lokbani, 93] M.N. Lokbani: Recherche des N-meilleures solutions et post-traitements en reconnaissance de la parole, Thèse de doctorat 3deg.cycle, Paris XI Orsay, Septembre 1993.
[Malbos, 95] F. Malbos : Détection et identification des occlusives à l'aide de la transformée en ondelettes , Thèse de doctorat 3deg.cycle, Paris XI Orsay, Janvier 1995.
[Mariani, 89] J. Mariani : Recent advances in speech processing , IEEE Magazine 1989, CH2673-2/89/0000-0429
[Markel, 76] J.D. Markel, A.H. Gray : Linear prediction in speech, Editions Springer-Verley, Berlin, Heidelberg, New-York
[Markov, 13] A. A . Markov : Essai d'une recherche statistique sur le texte du roman "Eugène Onyegin" la liaison des épreuves en chaînes, Bull Acad. Sci., St Petersbourg, Vol 7, pp 153-162, 1913
[Mérialdo, 87] B. Mérialdo, A. M. Derouault, M. El-Bèze, S. Soudoplatoff : Reconnaissance de parole avec un très grand vocabulaire, XVIèmes JEP-SFA, Hammanet 1987
[Mérialdo, 88] B. Mérialdo : Multi-level decoding for very-large-size-dictionary speech recognition, IBM journal of research and development, Vol 32, ndeg.2, March 1988.
[Mercier, 84] G. Mercier, M. Gilloux, C. Tarridec, J. Vaissière : From KEAL to SERAC : a new rule-based expert system for speech recognition, NATO/ASI, Bonas 1984.
[Minami, 93] Y. Minami, K. Shikano, T. Yamada, T. Matsuoka : Large vocabulary continuous speech recognition algorithm for telephone directory assistance, Eurospeech, Berlin 1993, pp 2129-2132
[Mokbel, 92] Mokbel : Reconnaissance automatique de la parole dans le bruit , Thèse de doctorat-ingénieur, Telecom Paris, 1992
[Morimoto, 90] T Morimoto, H. Iida, A. Kurematsu, K. Shikano et T. Aizawa : Spoken language : Towards realizing an automatic telephone interpretation, Proc. INFO Japan 90, pp 553-559, 1990.
[Murveit, 89] H. Murveit : SRI's DECIPHER system, Proc. DARPA Speech and Natural Language Workshop, Philadelphia, PA, pp 238-242, 1989.
[Ney & Paeseler, 88] H. Ney et A. Paeseler : Phoneme-based continuous speech recognition results for different language models in a 1000-word SPICOS system, Speech Communication, Vol. 7, ndeg.4, pp 367-374, 1988.
[Nguyen, 93] R. Nguyen, K. Smaili, J. P. Haton, G. Pérennou : Integration of phonological knowledge in a continuous speech recognition system , Proceedings 3rd European Conference on Speech Communication and technology, pp 2191-2194.
[Nocera, 92] P. Nocera : Utilisation conjointe de réseaux neuronaux et de connaissances explicites pour le décodage acoustico-phonétique, Thèse de l'Université d'Avignon et des Pays du Vaucluse, 1992.
[Paul, 89] D.B. Paul : The Lincoln robust continuous speech recognizer, Proc. Internat. Conf. Acoust. Speech signal Process., Glasgow, pp 449-452, 1989.
[Parlangeau, 93] N. Parlangeau : Etude de l'apport d'une segmentation statistique du signal de parole dans un système de décodage acoustico-phonétique basé sur des connaissances, rapport de DEA Toulouse III, 1993.
[Pérennou, 86] G. Pérennou, M. de Calmès : B.D.L.E.X : une base de données et de connaissances du français parlé, Actes du Séminaire "Lexique et traitement des langages", Université Paul Sabatier, Toulouse, 16-17 Janvier 1986, pp 243-258.
[Pérennou, 88] G. Pérennou : Le projet BDLEX de données et de connaissances lexicales et phonologiques, 1ères Journées du GRECO-PRC Communication Homme-Machine, EC2 Editeur, Paris 1988, pp 81-111.
[Pérennou, 92] G. Pérennou : Introduction aux groupes à prononciations multiples - suivi d'un sous-ensemble phonologique du français, Rapport Interne IRIT94-07R.
[Rabiner, 86] L.R. Rabiner, B.H. Juang : An introduction to hidden Markov models , IEEE ASSP Magazine, pp 4-16, Janvier 1986.
[Robert-Ribes, 95] J. Robert-Ribes : Modèles d'intégration audiovisuelle de signaux linguistiques : de la perception humaine à la reconnaissance automatique des voyelles ,Thèse de 3deg. cycle de l'Institut National Polytechnique de Grenoble, Février 1995.
[Rosenblatt, 58] F. Rosenblatt : The perceptron : a probabilistic model for information and organization in the brain , Psychological review, ndeg. 65, pp 386-408, 1958.
[Sagayama, 92] Sagayama : ATREUS : Continuous speech recognition systems at ATR interpreting telephony research laboratories, Proc Australian Speech Science & Technology Conf. SST-92, Brisbane, Australia, pp. 324-329.
[Sakoë, 78] H. Sakoë, S. Chiba : Dynamic programming optimisation for spoken word recognition, Proc. IEE Trans. on ASSP, Vol. ASSP-26, p. 43, Février 1978.
[Schwartz, 89] R. Schwartz : The BBN BYBLOS continuous speech recognition system, Proc. DARPA Speech an d Natural LanguageWorkshop, Philadelphia, pp. 94-99, 1989.
[Simon, 85] J.C. Simon : Invariance en reconnaissance des formes, Colloque COGNITIVA 85, pp 119-130.
[Smaïli, 91] K. Smaïli : Conception et réalisation d'une machine à dicter à entrée vocale destinée aux grands vocabulaires : Le système MAUD. Thèse de l'Université de Nancy I , septembre 1991.
[Smaili, 92] K. Smaili, F. Charpillet, J. M. Pierrel, J. P. Haton : La composante lexicale de la machine à dicter MAUD, Actes du séminaire lexique, GDR-PRC Communication Homme-Machine, IRIT-UPS, Toulouse, 21-22 Janvier 1992.
[Steinbiss, 93] V. Steinbiss, H. Ney, R. Haeb-Umbach, B. H. Tran, U. Essen, R. Kneser, M. Oerder, H. G. Meier, X. Aubert, C. Dugast, D. Geller : The Philips Research System for large vocabulary continuous speech recognition, 3rd Eurospeech, Berlin, pp 2125-2128, 1993.
[Su, 87] H.Y. Su : "Reconnaissance acoustico-phonétique en parole continue par quantification vectorielle ; adaptation du dictionnaire au locuteur, Thèse de l'Université de Rennes I, Novembre 1987.
[Su, 90] H.Y. Su, R. André-Obrecht : "Adaptation en cours de reconnaissance d'un dictionnaire de références ponétiques à un nouveau locuteur, 17ième J.E.P. 1990.
[Suaudeau, 94a] N. Suaudeau , Un modèle probabiliste pour intégrer la dimension temporelle dans un système de reconnaissance de parole, Thèse de doctorat de 3deg. cycle, Université de Rennes I, Mars 1994.
[Suaudeau, 94b] N.Suaudeau, R. André-Obrecht, An efficient combinaison, of acoustic and supra-segmental informations in a specch recognition system, ICASSP 94, Adélaïde, Australie, Avril 1994.
[Svendson, 94] T. Svendson : Segmental Quantization of speech spectral information , ICASSP 94, pp517-520, Adélaïde, 1994.
[Tokkola, 94] K. Tokkola: New ways to use LVQ-codebooks together with hidden Markov models , Proc. IEEE ICASSP, Adélaïde, Australie.
[Waibel, 89] A. Weibel, T. Hanazawa, G. Hints, K. Shikana, K. Y. Lang : Phoneme recognition using time delay neural networks, IEEE Trans. Acoustic Speech and Signal Processing, ndeg.37, Vol 3, pp 328-339, 1989.
[Woodland & Young, 92] P.C. Woodland et S.J. Young : Benchmark DARPA RM results with the HTK portable HMM Toolkit, Proc. DARPA Continuous Speech Recognition Workshop, Stanford, pp. 47-52, 1992.
[Wu, 90] Z. L. Wu : Peut-on "entendre" des évènements articulatoires ? Traitement temporel de la parole dans un modèle du système auditif, Thèse de l'Institut National Polytechnique de Grenoble, Juillet 1990.
[Young, 92] S.J. Young : "HTK Hidden Markov Model Toolkit" Rapport Cambridge University Engineering Department -- Speech Group -- September 92 .
[Zue, 89] V. Zue, J. Glass, M. Philips et S. Seneff : The MIT summit speech recognition system : A progress report, Proc. DARPA Speech and Natural Language Workshop, Philadelphia, PA, pp. 179-189, 1989.
[Zurcher, 80] Zurcher : Le vocodeur à canaux : une nouvelle jeunesse ?, Recherche/Acoustique CNET, 1980, Vol 5, pp21-40.
*=============================================================*<> * Extrait de 50 mots du *
* Reseau des 500 mots du CNET *
* en modélisation pseudo-diphones *
* destiné à des observations issues *
* d'un pré-traitement segmental *
*=============================================================*<>
* Les commentaires sont en italique et les mots clés en gras
*==============================================================*p> * NIVEAU ORTHOGRAPHIQUE *
*==============================================================*p>
RESEAU mots_tel
INITIAL init.tel
FINAL fin.tel
TYPE 2
TRANSITIONS
init.tel #_silence.tel 1
#_silence.tel ma.tel 0.02
ma.tel $_silence.tel 1
#_silence.tel c'est-a-dire.tel 0.02
c'est-a-dire.tel $_silence.tel 1
#_silence.tel vacances.tel 0.02
vacances.tel $_silence.tel 1
#_silence.tel trouver.tel 0.02
trouver.tel $_silence.tel 1
#_silence.tel alors.tel 0.02
alors.tel $_silence.tel 1
#_silence.tel boire.tel 0.02
boire.tel $_silence.tel 1
#_silence.tel chanter.tel 0.02
chanter.tel $_silence.tel 1
#_silence.tel dur.tel 0.02
dur.tel $_silence.tel 1
#_silence.tel seul.tel 0.02
seul.tel $_silence.tel 1
#_silence.tel garder.tel 0.02
garder.tel $_silence.tel 1
#_silence.tel foutre.tel 0.02
foutre.tel $_silence.tel 1
#_silence.tel chose.tel 0.02
chose.tel $_silence.tel 1
#_silence.tel matin.tel 0.02
matin.tel $_silence.tel 1
#_silence.tel gentil.tel 0.02
gentil.tel $_silence.tel 1
#_silence.tel oeil.tel 0.02
oeil.tel $_silence.tel 1
#_silence.tel chef.tel 0.02
chef.tel $_silence.tel 1
#_silence.tel compte.tel 0.02
compte.tel $_silence.tel 1
#_silence.tel quatorze.tel 0.02
quatorze.tel $_silence.tel 1
#_silence.tel puisque.tel 0.02
puisque.tel $_silence.tel 1
#_silence.tel bureau.tel 0.02
bureau.tel $_silence.tel 1
#_silence.tel entrer.tel 0.02
entrer.tel $_silence.tel 1
#_silence.tel on.tel 0.02
on.tel $_silence.tel 1
#_silence.tel plutot.tel 0.02
plutot.tel $_silence.tel 1
#_silence.tel metier.tel 0.02
metier.tel $_silence.tel 1
#_silence.tel aucun.tel 0.02
aucun.tel $_silence.tel 1
#_silence.tel une.tel 0.02
une.tel $_silence.tel 1
#_silence.tel n'est-ce_pas.tel 0.02
n'est-ce_pas.tel $_silence.tel 1
#_silence.tel dimanche.tel 0.02
dimanche.tel $_silence.tel 1
#_silence.tel pourquoi.tel 0.02
pourquoi.tel $_silence.tel 1
#_silence.tel plein.tel 0.02
plein.tel $_silence.tel 1
#_silence.tel quelque.tel 0.02
quelque.tel $_silence.tel 1
#_silence.tel campagne.tel 0.02
campagne.tel $_silence.tel 1
#_silence.tel servir.tel 0.02
servir.tel $_silence.tel 1
#_silence.tel grand.tel 0.02
grand.tel $_silence.tel 1
#_silence.tel gagner.tel 0.02
gagner.tel $_silence.tel 1
#_silence.tel jamais.tel 0.02
jamais.tel $_silence.tel 1
#_silence.tel deux.tel 0.02
deux.tel $_silence.tel 1
#_silence.tel nuit.tel 0.02
nuit.tel $_silence.tel 1
#_silence.tel evidemment.tel 0.02
evidemment.tel $_silence.tel 1
#_silence.tel dehors.tel 0.02
dehors.tel $_silence.tel 1
#_silence.tel venir.tel 0.02
venir.tel $_silence.tel 1
#_silence.tel theatre.tel 0.02
theatre.tel $_silence.tel 1
#_silence.tel longtemps.tel 0.02
longtemps.tel $_silence.tel 1
#_silence.tel fatiguer.tel 0.02
fatiguer.tel $_silence.tel 1
#_silence.tel occuper.tel 0.02
occuper.tel $_silence.tel 1
#_silence.tel pays.tel 0.02
pays.tel $_silence.tel 1
#_silence.tel oui.tel 0.02
oui.tel $_silence.tel 1
#_silence.tel un.tel 0.02
un.tel $_silence.tel 1
#_silence.tel huit.tel 0.02
huit.tel $_silence.tel 1
#_silence.tel age.tel 0.02
age.tel $_silence.tel 1
$_silence.tel fin.tel 1
*==============================================================*p> * NIVEAU PHONETIQUE *
*==============================================================*p>
RESEAU on
INITIAL init.on
FINAL fin.on
TYPE 1
TRANSITIONS
init.on %.on
%.on %$.on
%$.on fin.on
LIENS
on
RESEAU ma
INITIAL init.ma
FINAL fin.ma
TYPE 1
TRANSITIONS
init.ma N.ma
N.ma A.ma
A.ma fin.ma
LIENS
ma
RESEAU c'est-a-dire
INITIAL init.c'est-
FINAL fin.c'est-
TYPE 2
TRANSITIONS
init.c'est- S.c'est- 1
S.c'est- E.c'est- 1
E.c'est- T#.c'est- 1
T#.c'est- T.c'est- 1
T.c'est- A.c'est- 1
A.c'est- D.c'est- 1
D.c'est- I.c'est- 1
I.c'est- R$.c'est- 0.5
R$.c'est- fin.c'est- 1
I.c'est- R.c'est- 0.5
R.c'est- efin.c'est- 1
efin.c'est- fin.c'est- 1
LIENS
c'est-a-dire RESEAU vacances
INITIAL init.vacanc
FINAL fin.vacanc
TYPE 1
TRANSITIONS
init.vacanc D.vacanc
D.vacanc A.vacanc
A.vacanc T#.vacanc
T#.vacanc T.vacanc
T.vacanc %.vacanc
%.vacanc S.vacanc
S.vacanc fin.vacanc
LIENS
vacances
RESEAU trouver
INITIAL init.trouve
FINAL fin.trouve
TYPE 1
TRANSITIONS
init.trouve TR.trouve
TR.trouve U.trouve
U.trouve D.trouve
D.trouve E.trouve
E.trouve fin.trouve
LIENS
trouver
RESEAU alors
INITIAL init.alors
FINAL fin.alors
TYPE 2
TRANSITIONS
init.alors A.alors 1
A.alors L.alors 0.6
A.alors O.alors 0.4
L.alors O.alors 1
O.alors R$.alors 1
R$.alors fin.alors 1
LIENS
alors
RESEAU boire
INITIAL init.boire
FINAL fin.boire
TYPE 2
TRANSITIONS
init.boire D.boire 1
D.boire W.boire 1
W.boire A.boire 1
A.boire R$.boire 0.5
R$.boire fin.boire 1
A.boire R.boire 0.5
R.boire efin.boire 1
efin.boire fin.boire 1
LIENS
boire RESEAU chanter
INITIAL init.chante
FINAL fin.chante
TYPE 1
TRANSITIONS
init.chante S.chante
S.chante %.chante
%.chante T#.chante
T#.chante T.chante
T.chante E.chante
E.chante fin.chante
LIENS
chanter
RESEAU dur
INITIAL init.dur
FINAL fin.dur
TYPE 1
TRANSITIONS
init.dur D.dur 1
D.dur Y.dur 1
Y.dur R$.dur 0.5
R$.dur fin.dur 1
Y.dur R.dur 0.5
R.dur efin.dur 1
efin.dur fin.dur 1
LIENS
dur
RESEAU seul
INITIAL init.seul
FINAL fin.seul
TYPE 1
TRANSITIONS
init.seul S.seul
S.seul e.seul
e.seul L.seul
L.seul fin.seul
LIENS
seul
RESEAU garder
INITIAL init.garder
FINAL fin.garder
TYPE 2
TRANSITIONS
init.garder D.garder 1
D.garder A.garder 1
A.garder R.garder 0.6
A.garder D.garder1 0.4
R.garder D.garder1 1
D.garder1 E.garder 1
E.garder fin.garder 1
LIENS
garder RESEAU foutre
INITIAL init.foutre
FINAL fin.foutre
TYPE 2
TRANSITIONS
init.foutre S.foutre 1
S.foutre U.foutre 1
U.foutre T#.foutre 1
T#.foutre TR$.foutre 0.5
TR$.foutre fin.foutre 1
T#.foutre TR.foutre 0.5
TR.foutre efin.foutre 1
efin.foutre fin.foutre 1
LIENS
foutre
RESEAU chose
INITIAL init.chose
FINAL fin.chose
TYPE 2
TRANSITIONS
init.chose S.chose 1
S.chose O.chose 1
O.chose Z.chose 1
Z.chose fin.chose 0.5
Z.chose efin.chose 0.5
efin.chose fin.chose 1
LIENS
chose
RESEAU matin
INITIAL init.matin
FINAL fin.matin
TYPE 1
TRANSITIONS
init.matin N.matin
N.matin A.matin
A.matin T#.matin
T#.matin T.matin
T.matin IN.matin
IN.matin IN$.matin
IN$.matin fin.matin
LIENS
matin
RESEAU gentil
INITIAL init.gentil
FINAL fin.gentil
TYPE 1
TRANSITIONS
init.gentil Z.gentil
Z.gentil %.gentil
%.gentil T#.gentil
T#.gentil T.gentil
T.gentil I.gentil
I.gentil fin.gentil
LIENS
gentil RESEAU oeil
INITIAL init.oeil
FINAL fin.oeil
TYPE 2
TRANSITIONS
init.oeil e.oeil 1
e.oeil J.oeil 1
J.oeil fin.oeil 0.5
J.oeil efin.oeil 0.5
efin.oeil fin.oeil 1
LIENS
oeil
RESEAU chef
INITIAL init.chef
FINAL fin.chef
TYPE 1
TRANSITIONS
init.chef S.chef
S.chef E.chef
E.chef S.chef1
S.chef1 fin.chef
LIENS
chef
RESEAU compte
INITIAL init.compte
FINAL fin.compte
TYPE 2
TRANSITIONS
init.compte T.compte 1
T.compte %.compte 1
%.compte T#.compte1 1
T#.compte1 T.compte1 1
T.compte1 fin.compte 0.5
T.compte1 efin.compte 0.5
efin.compte fin.compte 1
LIENS
compte
RESEAU quatorze
INITIAL init.quator
FINAL fin.quator
TYPE 2
TRANSITIONS
init.quator T.quator 1
T.quator A.quator 1
A.quator T#.quator1 1
T#.quator1 T.quator1 1
T.quator1 O.quator 1
O.quator R.quator 0.5
O.quator Z.quator 0.5
R.quator Z.quator 1
Z.quator fin.quator 1
LIENS
quatorze RESEAU puisque
INITIAL init.puisqu
FINAL fin.puisqu
TYPE 2
TRANSITIONS
init.puisqu T.puisqu 1
T.puisqu y.puisqu 1
y.puisqu I.puisqu 1
I.puisqu S.puisqu 1
S.puisqu T#.puisqu1 1
T#.puisqu1 T.puisqu1 1
T.puisqu1 fin.puisqu 0.5
T.puisqu1 e.puisqu 0.5
e.puisqu fin.puisqu 1
LIENS
puisque
RESEAU bureau
INITIAL init.bureau
FINAL fin.bureau
TYPE 1
TRANSITIONS
init.bureau D.bureau
D.bureau Y.bureau
Y.bureau R.bureau
R.bureau O.bureau
O.bureau fin.bureau
LIENS
bureau
RESEAU entrer
INITIAL init.entrer
FINAL fin.entrer
TYPE 1
TRANSITIONS
init.entrer %.entrer
%.entrer T#.entrer
T#.entrer TR.entrer
TR.entrer E.entrer
E.entrer fin.entrer
LIENS
entrer
RESEAU plutot
INITIAL init.plutot
FINAL fin.plutot
TYPE 1
TRANSITIONS
init.plutot TL.plutot
TL.plutot Y.plutot
Y.plutot T#.plutot1
T#.plutot1 T.plutot1
T.plutot1 O.plutot
O.plutot fin.plutot
LIENS
plutot RESEAU metier
INITIAL init.metier
FINAL fin.metier
TYPE 1
TRANSITIONS
init.metier N.metier
N.metier E.metier
E.metier T#.metier
T#.metier T.metier
T.metier J.metier
J.metier E.metier1
E.metier1 fin.metier
LIENS
metier
RESEAU aucun
INITIAL init.aucun
FINAL fin.aucun
TYPE 1
TRANSITIONS
init.aucun O.aucun
O.aucun T#.aucun
T#.aucun T.aucun
T.aucun IN.aucun
IN.aucun IN$.aucun
IN$.aucun fin.aucun
LIENS
aucun
RESEAU une
INITIAL init.une
FINAL fin.une
TYPE 2
TRANSITIONS
init.une Y.une 1
Y.une N.une 1
N.une efin.une 0.5
N.une fin.une 0.5
efin.une fin.une 1
LIENS
une
RESEAU n'est-ce_pas
INITIAL init.n'est-
FINAL fin.n'est-
TYPE 2
TRANSITIONS
init.n'est- N.n'est- 1
N.n'est- E.n'est- 1
E.n'est- S.n'est- 1
S.n'est- e.n'est- 0.5
e.n'est- T#.n'est- 1
S.n'est- T#.n'est- 0.5
T#.n'est- T.n'est- 1
T.n'est- A.n'est- 1
A.n'est- fin.n'est- 1
LIENS
n'est-ce_pas RESEAU dimanche
INITIAL init.dimanc
FINAL fin.dimanc
TYPE 1
TRANSITIONS
init.dimanc D.dimanc
D.dimanc I.dimanc
I.dimanc N.dimanc
N.dimanc %.dimanc
%.dimanc S.dimanc
S.dimanc fin.dimanc
LIENS
dimanche
RESEAU pourquoi
INITIAL init.pourqu
FINAL fin.pourqu
TYPE 2
TRANSITIONS
init.pourqu T.pourqu 1
T.pourqu U.pourqu 1
U.pourqu R.pourqu 0.6
U.pourqu T#.pourqu 0.4
R.pourqu T#.pourqu 1
T#.pourqu T.pourqu1 1
T.pourqu1 W.pourqu 1
W.pourqu A.pourqu 1
A.pourqu fin.pourqu 1
LIENS
pourquoi
RESEAU plein
INITIAL init.plein
FINAL fin.plein
TYPE 1
TRANSITIONS
init.plein TL.plein
TL.plein IN.plein
IN.plein IN$.plein
IN$.plein fin.plein
LIENS
plein
RESEAU quelque
INITIAL init.quelqu
FINAL fin.quelqu
TYPE 2
TRANSITIONS
init.quelqu T.quelqu 1
T.quelqu E.quelqu 1
E.quelqu L.quelqu 1
L.quelqu T#.quelqu 1
T#.quelqu T.quelqu1 1
T.quelqu1 fin.quelqu 0.5
T.quelqu1 efin.quelqu 0.5
efin.quelqu fin.quelqu 1
LIENS
quelque RESEAU campagne
INITIAL init.campag
FINAL fin.campag
TYPE 2
TRANSITIONS
init.campag T.campag 1
T.campag %.campag 1
%.campag T#.campag1 1
T#.campag1 T.campag1 1
T.campag1 A.campag 1
A.campag N.campag 1
N.campag efin.campag 0.5
N.campag fin.campag 0.5
efin.campag fin.campag 1
LIENS
campagne
RESEAU servir
INITIAL init.servir
FINAL fin.servir
TYPE 2
TRANSITIONS
init.servir S.servir 1
S.servir E.servir 1
E.servir R.servir 0.5
E.servir D.servir 0.5
R.servir D.servir 1
D.servir I.servir 1
I.servir R$.servir 1
R$.servir fin.servir 1
LIENS
servir
RESEAU grand
INITIAL init.grand
FINAL fin.grand
TYPE 1
TRANSITIONS
init.grand DR.grand
DR.grand %.grand
%.grand %$.grand
%$.grand fin.grand
LIENS
grand
RESEAU gagner
INITIAL init.gagner
FINAL fin.gagner
TYPE 1
TRANSITIONS
init.gagner D.gagner
D.gagner A.gagner
A.gagner N.gagner
N.gagner E.gagner
E.gagner fin.gagner
LIENS
gagner
RESEAU jamais
INITIAL init.jamais
FINAL fin.jamais
TYPE 1
TRANSITIONS
init.jamais Z.jamais
Z.jamais A.jamais
A.jamais N.jamais
N.jamais E.jamais
E.jamais fin.jamais
LIENS
jamais
RESEAU deux
INITIAL init.deux
FINAL fin.deux
TYPE 1
TRANSITIONS
init.deux D.deux
D.deux e.deux
e.deux fin.deux
LIENS
deux
RESEAU nuit
INITIAL init.nuit
FINAL fin.nuit
TYPE 1
TRANSITIONS
init.nuit N.nuit
N.nuit y.nuit
y.nuit I.nuit
I.nuit fin.nuit
LIENS
nuit
RESEAU evidemment
INITIAL init.evidem
FINAL fin.evidem
TYPE 1
TRANSITIONS
init.evidem E.evidem
E.evidem D.evidem
D.evidem I.evidem
I.evidem D.evidem1
D.evidem1 A.evidem
A.evidem N.evidem
N.evidem %.evidem
%.evidem %$.evidem
%$.evidem fin.evidem
LIENS
evidemment
RESEAU dehors
INITIAL init.dehors
FINAL fin.dehors
TYPE 1
TRANSITIONS
init.dehors D.dehors
D.dehors e.dehors
e.dehors O.dehors
O.dehors R$.dehors
R$.dehors fin.dehors
LIENS
dehors
RESEAU venir
INITIAL init.venir
FINAL fin.venir
TYPE 2
TRANSITIONS
init.venir Z.venir 1
Z.venir e.venir 0.5
e.venir N.venir 1
Z.venir N.venir 0.5
N.venir I.venir 1
I.venir R$.venir 1
R$.venir fin.venir 1
LIENS
venir
RESEAU theatre
INITIAL init.theatr
FINAL fin.theatr
TYPE 2
TRANSITIONS
init.theatr T.theatr 1
T.theatr E.theatr 1
E.theatr A.theatr 1
A.theatr T#.theatr 1
T#.theatr TR$.theatr 0.5
TR$.theatr fin.theatr 1
T#.theatr TR.theatr 0.5
TR.theatr efin.theatr 1
efin.theatr fin.theatr 1
LIENS
theatre
RESEAU longtemps
INITIAL init.longte
FINAL fin.longte
TYPE 1
TRANSITIONS
init.longte L.longte
L.longte %.longte
%.longte T#.longte
T#.longte T.longte
T.longte %.longte1
%.longte1 %$.longte
%$.longte fin.longte
LIENS
longtemps RESEAU fatiguer
INITIAL init.fatigu
FINAL fin.fatigu
TYPE 1
TRANSITIONS
init.fatigu S.fatigu
S.fatigu A.fatigu
A.fatigu T#.fatigu
T#.fatigu T.fatigu
T.fatigu I.fatigu
I.fatigu D.fatigu
D.fatigu E.fatigu
E.fatigu fin.fatigu
LIENS
fatiguer
RESEAU occuper
INITIAL init.occupe
FINAL fin.occupe
TYPE 1
TRANSITIONS
init.occupe O.occupe
O.occupe T#.occupe
T#.occupe T.occupe
T.occupe Y.occupe
Y.occupe T#.occupe1
T#.occupe1 T.occupe1
T.occupe1 E.occupe
E.occupe fin.occupe
LIENS
occuper
RESEAU pays
INITIAL init.pays
FINAL fin.pays
TYPE 1
TRANSITIONS
init.pays T.pays
T.pays E.pays
E.pays I.pays
I.pays fin.pays
LIENS
pays
RESEAU oui
INITIAL U.oui W.oui
FINAL fin.oui
TYPE 2
TRANSITIONS
* init.oui U.oui 0.5
* U.oui W.oui 1
* init.oui W.oui 0.5
U.oui W.oui 1
W.oui I.oui 1
I.oui fin.oui 1
LIENS
oui
RESEAU un
INITIAL init.un
FINAL fin.un
TYPE 1
TRANSITIONS
init.un IN.un
IN.un IN$.un
IN$.un fin.un
LIENS
un
RESEAU huit
INITIAL init.huit
FINAL fin.huit
TYPE 1
TRANSITIONS
init.huit y.huit
y.huit I.huit
I.huit T#.huit
T#.huit T.huit
T.huit fin.huit
LIENS
huit
RESEAU age
INITIAL init.age
FINAL fin.age
TYPE 1
TRANSITIONS
init.age A.age
A.age Z.age
Z.age fin.age
LIENS
age
*__________ Niveau intermédiaire pour les silences ____________*
* *
RESEAU #_silence
INITIAL #.sil_d
FINAL #.sil_d
TYPE 1
TRANSITIONS
LIENS
#_silence
RESEAU $_silence
INITIAL $.sil_f
FINAL $.sil_f
TYPE 1
TRANSITIONS
LIENS
$_silence
*______________________________________________________________*
* *
COART_LOCALES
T # = #
T R = TR
W I = I
W A = A
y I = I
T J = J
Z J = Z
L J = L
N J = N
S J = S
R J = R
* J E = E
* e J = e
* J e = e
*==============================================================*p> * NIVEAU ACOUSTIQUE *
*==============================================================*p>
*-----------------------reseau des voyelles---------------------
RESEAU voyelles
INITIAL
init.v
FINAL
fin.v
TYPE 3
TRANSITIONS
init.v e1.v 0.5 1
init.v e1.v 0.5 0
e1.v e2.v 1.0 2
e2.v e2.v 0.3 2
e2.v fin.v 0.4 3
e2.v fin.v 0.3 0
LIENS
A I E e Y O U
*---------------------reseau du shwa final--------------------
RESEAU shwa
INITIAL
init.shwa
FINAL
fin.shwa
TYPE 3
TRANSITIONS
init.shwa e1.shwa 1.0 1
e1.shwa e2.shwa 1.0 2
e2.shwa e2.shwa 0.5 2
e2.shwa fin.shwa 0.5 0
LIENS
efin
*------------------reseau des voyelles nasales-----------------
RESEAU voy-nasales
INITIAL
init.vn
FINAL
fin.vn
TYPE 3
TRANSITIONS
init.vn e1.vn 0.5 1
init.vn e1.vn 0.5 0
e1.vn e2.vn 1.0 2
e2.vn e2.vn 0.3 2
e2.vn fin.vn 0.4 3
e2.vn fin.vn 0.3 0
fin.vn fin.vn 0.3 3
LIENS
% IN*-------reseau des fins de voyelle nasale en fin de prase------
RESEAU fin-voy-nasales
INITIAL
init.fvn
FINAL
fin.fvn
TYPE 3
TRANSITIONS
init.fvn fin.fvn 1.0 1
fin.fvn fin.fvn 0.5 1
LIENS
%$ IN$
*-----------------reseaux des plosives-------------------------
RESEAU plosives
INITIAL
init.plos
FINAL
fin.plos
TYPE 3
TRANSITIONS
init.plos fin.plos 0.8 1
init.plos fin.plos 0.2 0
fin.plos fin.plos 0.4 1
LIENS
T
*------
RESEAU silplos
INITIAL
init.silplos
FINAL
fin.silplos
TYPE 3
TRANSITIONS
init.silplos fin.silplos 1 1
fin.silplos fin.silplos 0.8 1
LIENS
T#
*-------------reseau des plosives + L + R ----------------------
* en debut de mot
RESEAU plos-l
INITIAL
init.pll
FINAL
fin.pll
TYPE 3
TRANSITIONS
init.pll e1.pll 1 1
e1.pll e1.pll 0.4 1
e1.pll fin.pll 0.6 2
fin.pll fin.pll 0.5 2
LIENS
TL TR
*-----------------------reseau du TR et R ---------------------
* en fin de mot
RESEAU tr
INITIAL
init.tr
FINAL
fin.tr
TYPE 3
TRANSITIONS
init.tr e1.tr 0.5 1
init.tr e1.tr 0.5 0
e1.tr e2.tr 0.5 2
e1.tr e2.tr 0.5 0
e2.tr e2.tr 0.5 2
e2.tr fin.tr 0.5 3
fin.tr fin.tr 0.5 3
LIENS
TR$ R$
*--------------------reseau des plosives voisees-------------
RESEAU plos-vois
INITIAL
init.plv
FINAL
fin.plv
TYPE 3
TRANSITIONS
init.plv e1.plv 1.0 1
e1.plv e1.plv 0.2 1
e1.plv fin.plv 0.4 2
e1.plv fin.plv 0.4 0
LIENS
D
*------------------reseau des plosives voisees + R -------------
* en debut de mot
RESEAU plos-voisl
INITIAL
init.plvl
FINAL
fin.plvl
TYPE 3
TRANSITIONS
init.plvl e1.plvl 1.0 1
e1.plvl e1.plvl 0.3 1
e1.plvl fin.plvl 0.4 2
e1.plvl fin.plvl 0.3 0
fin.plvl fin.plvl 0.5 2
LIENS
DR
*-------------------reseau des fricatives-----------------------
RESEAU fricative
INITIAL
init.fr
FINAL
fin.fr
TYPE 3
TRANSITIONS
init.fr e1.fr 0.5 1
init.fr e1.fr 0.5 0
e1.fr e2.fr 1.0 2
e2.fr e2.fr 0.3 2
e2.fr fin.fr 0.35 3
e2.fr fin.fr 0.35 0
LIENS
S Z
*----------------------reseau des nasales-----------------------
RESEAU nasale
INITIAL
init.nas
FINAL
fin.nas
TYPE 3
TRANSITIONS
init.nas fin.nas 1.0 1
fin.nas fin.nas 0.5 1
LIENS
N
*---------------------reseau des semivoyelles-------------------
RESEAU semi-voy
INITIAL
init.sv
FINAL
fin.sv
TYPE 3
TRANSITIONS
init.sv fin.sv 1.0 1
fin.sv fin.sv 0.5 1
LIENS
J W y*----------------------reseau des liquides----------------------
RESEAU liquide
INITIAL
init.l
FINAL
fin.l
TYPE 3
TRANSITIONS
init.l fin.l 1.0 1
fin.l fin.l 0.5 1
LIENS
L
*------------------------reseau de R ---------------------------
RESEAU R
INITIAL
init.r
FINAL
fin.r
TYPE 3
TRANSITIONS
init.r e1.r 0.5 1
init.r e1.r 0.5 0
e1.r e2.r 1.0 2
e2.r e2.r 0.3 2
e2.r fin.r 0.4 3
e2.r fin.r 0.3 0
LIENS
R
*--------------------reseau de l'aspiration---------------------
RESEAU haspire
INITIAL
init.h
FINAL
fin.h
TYPE 3
TRANSITIONS
init.h fin.h 0.5 1
init.h fin.h 0.5 0
LIENS
+
*--------------------- reseau silence debut --------------------
RESEAU silence_deb
INITIAL
init.silen_d
FINAL
fin.silen_d
TYPE 3
TRANSITIONS
init.silen_d fin.silen_d 0.5 1
fin.silen_d fin.silen_d 0.05 1
init.silen_d fin.silen_d 0.5 2
fin.silen_d fin.silen_d 0.05 2
LIENS
#
*--------------------- reseau silence fin ----------------------
RESEAU silence_fin
INITIAL
init.silen_f
FINAL
init.silen_f
TYPE 3
TRANSITIONS
init.silen_f init.silen_f 0.2 1
init.silen_f init.silen_f 0.2 2
LIENS
$
*-----* *-----*
* *
*============== INITIALISATIONS LOIS CONTINUES =================
* *
*-----* *-----*
LOIS
TYPE C
LONGUEUR 19
VALEURS
-11.194975 -2.279787 -1.855033 -0.947037 -3.541655
-0.648082 -1.505464 -1.404521 0.606014 0.572914
-0.241449 0.138056 -0.058964 -0.066718 0.023266
-0.063567 0.003032 0.092867 63.885113
12.815792 9.607375 5.024505 2.763865 2.223028
1.571116 1.567781 1.295840 0.319188 4.213277
3.449738 1.463214 0.784657 0.590610 0.461791
0.479455 0.389758 0.152485 3259.926270
RACINES
#
VALEURS
-8.215327 -2.513102 -1.936437 -1.066706 -3.896893
-0.980024 -1.864920 -1.784878 0.841747 -0.010760
-0.018023 0.198429 -0.102557 0.237097 0.004779
0.050631 0.154644 0.011518 78.492363
15.144787 10.948844 7.206038 3.458687 2.784812
1.819962 1.971016 1.553450 0.377767 3.341714
1.409322 1.382420 0.506941 0.492264 0.286679
0.253569 0.338921 0.112994 3129.207275
RACINES
$
VALEURS
5.092342 -8.826348 -0.249553 -1.533798 -3.355629
-0.007567 -2.536571 -0.287747 2.986702 -3.485804
2.352036 -0.592480 1.136669 0.055297 0.107609
0.520924 -0.363564 -0.673618 31.318226
21.749069 16.971985 23.552740 11.350619 6.292757
3.755079 5.774533 2.620298 0.565760 5.827200
5.652534 2.990509 2.274525 0.973716 0.767112
0.857655 0.757288 0.183363 131.199585
RACINES
A
VALEURS
2.947205 -6.959843 6.972766 -5.140348 -6.964584
0.657375 -4.034100 -1.942481 3.392354 -1.291612
0.963988 -0.705589 0.732382 0.280345 0.073107
0.255465 -0.139176 -0.309195 46.399265
22.926205 30.406137 10.729133 9.894951 4.955195
4.691149 4.633466 3.673389 0.759991 6.357939
4.137378 2.575442 1.701630 0.698257 0.563763
0.523651 0.413359 0.229027 731.974243
RACINES
E
VALEURS
-6.797455 -11.572338 9.181815 -6.561233 -5.878726
1.739300 -4.924997 -0.882732 3.802403 1.266348
0.467286 1.006400 0.228267 -0.513108 -0.060639
0.068926 -0.368728 0.101626 63.889763
33.981110 12.594401 15.789259 10.765685 5.357015
5.219373 4.567893 3.003939 0.623720 5.272627
2.204127 2.172611 1.148832 0.622443 0.531379
0.383343 0.455369 0.076996 1395.728149
RACINES
Y
VALEURS
0.410162 -8.296197 8.924315 -2.577746 -7.626139
-0.119382 -3.397084 -2.737935 3.518692 0.975738
0.520392 0.851092 -0.080941 -0.080267 -0.054877
-0.117708 -0.102404 0.104214 75.378906
28.339695 19.006079 9.750454 11.153674 2.766989
5.178120 5.168976 2.550623 0.481172 4.275819
1.691193 1.545309 1.087532 0.449096 0.518287
0.414394 0.322073 0.063557 2252.250977
RACINES
y
VALEURS
1.943620 -10.079087 -0.377372 -3.632970 -3.701397
-0.343270 -4.259594 -1.331688 2.992826 3.688358
1.674058 -0.012455 -0.129223 0.448771 -0.017671
-0.292392 -0.460087 0.177925 38.399330
36.679363 29.053110 27.922672 10.271542 3.313806
4.037253 8.139845 4.705761 0.921745 11.303666
5.816615 3.707725 2.490552 0.796472 0.868240
0.736259 0.801705 0.218384 252.467957
RACINES
U
VALEURS
11.709984 -7.820369 -2.357234 -7.761777 -3.491726
-0.321795 -4.344401 -1.726042 4.002091 1.139196
-0.766158 -0.307939 -0.542288 0.329512 0.062954
-0.206506 0.101653 0.233789 54.212677
14.854281 26.128574 6.732841 12.734736 3.816544
2.966075 4.760318 3.410350 0.549028 5.079051
4.662486 1.038474 1.390716 0.534285 0.452358
0.523691 0.460715 0.100401 803.655396
RACINES
WVALEURS
4.572040 -7.415212 -2.376897 -5.502210 -3.604822
-0.287755 -4.531629 -1.675495 2.958545 4.485838
-0.007331 0.573592 -1.342178 0.077527 -0.046478
-0.666781 -0.171994 0.595421 41.754349
44.683361 27.004242 9.708679 14.033895 3.587604
4.148224 5.871233 4.011573 1.110865 13.644711
4.797254 2.576678 2.151553 0.753294 0.636571
0.931984 0.528433 0.319642 617.720032
RACINES
O
VALEURS
0.599789 -5.630777 11.481437 -7.615499 -5.344646
0.521802 -6.705157 -1.817884 3.891575 0.154793
0.594217 0.501320 -0.279682 0.204197 0.071405
-0.189068 0.024495 0.037566 88.773796
12.043825 13.990869 8.715448 7.680430 3.706319
2.248717 4.113941 3.077833 0.497911 1.950697
1.087834 1.417578 0.630126 0.360267 0.213660
0.253507 0.186860 0.050428 1756.991333
RACINES
I
VALEURS
1.565570 -6.215750 8.789154 -6.000699 -5.690454
0.262631 -5.178016 -1.401535 3.546897 0.415274
0.037931 -0.067793 0.083801 -0.033411 -0.057928
0.045661 -0.003580 -0.000566 64.568336
28.644873 22.988590 14.023424 12.057301 5.638298
2.995365 5.604027 2.698777 0.707127 3.457708
2.891531 1.930611 1.032762 0.646708 0.378739
0.363929 0.330118 0.078083 1091.610718
RACINES
J
VALEURS
6.401272 -13.631271 6.560085 -5.480706 -7.516600
-2.793945 -4.988482 -0.599057 4.388039 1.066728
-0.400318 -0.072977 0.022224 -0.101792 -0.296860
0.002915 0.154911 0.109293 113.322754
16.130672 16.592997 12.093598 8.337749 3.976775
4.945919 6.147013 4.017203 0.527491 5.086082
1.774657 1.258480 0.542077 0.231890 0.335097
0.380895 0.248192 0.124126 3497.099854
RACINES
e
VALEURS
0.819078 -7.392932 -0.464428 -0.481224 -3.749614
-0.641994 -2.343972 -0.751716 2.328029 -1.672177
0.834351 -0.242103 0.501234 0.062524 -0.054038
0.297805 -0.212339 -0.299864 43.130257
25.985382 13.515530 13.091963 9.070146 4.997973
3.218325 5.646064 2.914491 0.349434 3.884653
1.882041 1.081167 0.783160 0.500423 0.387857
0.342212 0.315025 0.061511 205.562515
RACINES
efinVALEURS
9.613970 -13.441538 -2.591636 -7.391391 -1.997261
-0.225201 -5.364728 -0.333806 4.241254 1.438919
0.197731 -0.656684 -0.585429 0.444472 0.413986
0.164195 -0.027699 0.159873 79.047623
18.645424 17.673576 11.867736 14.255221 4.350317
4.316527 5.019799 4.032289 0.655598 6.521624
2.116696 1.465253 1.038374 0.734723 0.415074
0.537356 0.349860 0.164716 1518.703003
RACINES
%
VALEURS
8.210763 -17.491026 2.210784 -5.602551 -4.435107
-1.193522 -4.017267 1.051356 4.605700 0.386438
-0.371670 -0.184945 0.339405 0.371787 -0.121555
0.070399 0.268857 0.044173 94.015152
7.230308 13.694737 13.395204 8.068956 6.622358
4.379448 5.728302 3.504687 0.325041 2.426072
1.316496 0.933186 0.520021 0.443936 0.322847
0.275115 0.356980 0.068235 1282.934937
RACINES
IN
VALEURS
-4.589103 -4.493798 -0.518563 -2.111606 -5.085472
-0.852089 -2.297719 -1.654460 1.610853 -0.608098
-0.978682 0.048207 -0.304988 -0.082004 0.041369
-0.136683 0.140669 0.074530 50.600605
24.810541 25.016697 14.844378 7.524255 4.764273
3.603493 4.178757 2.444979 0.934810 5.848177
7.916655 3.095517 1.321297 0.691044 0.618515
0.724210 0.495591 0.310831 719.645203
RACINES
T#
VALEURS
1.805587 -10.775344 -1.842977 -2.895651 -2.802390
0.030655 -3.807981 -0.049228 2.875188 -1.889909
0.359145 -0.574350 0.528496 0.386860 -0.081706
-0.015339 -0.087001 -0.267730 57.155098
32.064289 14.918139 12.313289 13.955009 5.644543
3.852287 6.149175 2.877159 0.454473 4.426313
3.062628 1.034927 1.070426 0.793940 0.480917
0.405051 0.494490 0.106408 1339.402100
RACINES
R$
VALEURS
-6.989902 -12.133834 -2.135913 -1.482019 -2.795244
-1.521064 -4.012742 0.873669 2.208582 0.414029
0.565165 -0.002739 0.192306 0.551060 0.056675
0.067223 0.019050 -0.051380 69.828949
2.576884 15.703335 7.001309 6.397797 2.392357
1.515285 3.298957 1.562343 0.302755 3.121919
1.032212 2.055373 0.996116 0.513270 0.225435
0.309513 0.246686 0.072254 1119.694214
RACINES
TR$VALEURS
-3.381803 -11.233390 2.981930 -4.657920 -5.313733
0.198852 -4.005537 -0.470703 3.032085 3.591871
-0.091846 1.088954 -0.576477 -0.179964 -0.257500
-0.384281 0.116574 0.449264 33.431564
28.326366 20.777344 16.330978 12.372613 4.995975
3.769362 5.468379 2.961231 0.713651 17.197384
9.362720 4.042596 2.372959 1.372760 1.093120
0.969300 0.868207 0.446878 209.793060
RACINES
T
VALEURS
-2.600010 -13.730933 0.551810 -3.606277 -3.585319
-0.712513 -4.258876 0.572601 3.059284 0.918413
-0.250981 -0.553853 0.050284 0.584472 -0.159705
-0.219468 0.281260 0.084602 42.017315
18.356249 22.572554 14.887431 13.033922 4.756278
3.607467 5.809801 2.794401 0.644170 6.066195
5.673765 2.978284 1.808090 1.282552 0.763449
0.809208 0.690553 0.186097 531.248291
RACINES
TR
VALEURS
-3.023769 -10.602246 2.861677 -1.854255 -5.770789
-0.668779 -3.189072 -0.822433 2.722497 2.000036
-0.860035 1.375987 -0.159388 -0.344111 -0.168288
-0.403430 0.084374 0.426886 38.370911
30.821886 32.346523 13.747982 11.579929 4.593641
3.422646 4.074271 2.067102 1.199859 8.866362
9.013830 2.767117 1.803446 1.109443 0.948802
0.840840 0.537799 0.246960 382.473206
RACINES
TL
VALEURS
4.019181 -10.521892 -1.280053 -3.890137 -3.366863
-0.438954 -3.849604 -0.449382 3.184952 0.032092
0.400003 0.179478 0.155600 -0.227987 -0.082893
0.136105 -0.144215 -0.049358 50.334995
47.687798 22.414038 14.969602 15.003461 4.683353
3.551108 5.937010 3.467863 0.773453 6.355105
4.250106 2.078689 1.307877 0.670333 0.486736
0.568014 0.486386 0.200237 651.659729
RACINES
+
VALEURS
6.486814 -11.712622 -1.577962 -4.155385 -1.599103
0.072082 -4.826434 -0.870467 3.598459 1.209062
-0.083784 -0.423746 -0.790162 0.170282 0.202983
-0.036766 0.020075 0.151317 47.489796
32.392521 16.870884 9.637771 19.048445 4.589353
4.470041 5.799420 4.602784 0.626633 6.958017
5.933212 1.044989 1.237787 0.843316 0.746059
0.779504 0.454864 0.185161 534.127441
RACINES
DRVALEURS
1.842694 0.022039 2.490427 -0.469067 -4.066020
-0.686557 -2.783155 -2.380870 2.029308 -0.098556
-0.990988 0.378327 -0.285205 -0.026864 0.100890
-0.158477 0.238566 0.137120 61.067513
18.053286 27.203348 9.129222 7.988634 4.267704
3.437365 4.734683 3.885847 0.647824 4.734795
8.200347 1.741678 1.661141 0.606967 0.562842
0.558186 0.531054 0.174665 1010.611206
RACINES
D
VALEURS
-9.324683 -12.673350 5.067431 -5.719676 -4.700213
0.952154 -4.185024 -0.007397 3.159489 0.380342
-0.252248 0.260364 -0.187877 -0.005543 0.010979
-0.071717 0.093180 0.109870 90.686211
22.508522 15.497398 20.186876 10.142919 3.712178
3.454406 3.628269 2.526241 0.921098 5.150386
1.557797 1.590263 0.633896 0.375412 0.345384
0.258534 0.267689 0.098636 2633.084961
RACINES
S
VALEURS
-1.303266 -4.481367 3.365643 -0.134486 -5.566608
-0.635870 -2.524708 -2.098888 2.149901 1.655430
-0.552660 1.546645 -0.184812 -0.305521 0.253158
-0.365878 0.019639 0.360681 44.071098
37.719501 16.672577 11.466999 6.414383 4.813932
3.532117 4.417855 2.195362 0.475649 11.946013
2.939065 3.710791 0.845353 0.865547 0.547038
0.633349 0.357372 0.266270 417.967041
RACINES
Z
VALEURS
4.538598 -9.351197 -1.217308 -3.988724 -3.235708
-0.259377 -3.819042 -0.342484 3.086256 0.605102
0.441687 -0.596386 -0.189032 0.330207 0.156376
-0.122168 -0.085523 -0.004493 41.369713
45.726593 19.927839 14.363628 14.783288 5.514952
3.137538 6.328985 3.774246 0.892100 12.752202
4.492339 2.491915 1.825337 0.846875 0.574221
0.613480 0.533523 0.270680 333.821075
RACINES
R
VALEURS
3.979233 -8.079080 3.657681 -1.846821 -5.978613
-1.813322 -3.478997 -1.141179 3.115731 -0.028213
0.087367 -0.084967 0.010614 0.078732 -0.001356
0.019529 -0.011918 -0.018580 60.439739
24.957556 18.499794 15.749404 11.198505 4.912478
5.151436 7.534158 2.805631 0.856319 6.065367
2.660521 1.934833 1.103032 0.614756 0.508670
0.463511 0.360524 0.165298 1179.184814
RACINES
LVALEURS
5.253662 -4.420400 4.226243 -1.198308 -5.098031
-1.128692 -4.021589 -2.751035 2.924256 0.946949
-0.586797 0.258728 -0.248454 0.007799 0.067128
-0.109583 0.104920 0.186028 70.645607
12.286335 17.723284 8.312519 8.627771 4.007602
3.555074 5.358634 4.031959 0.443834 5.906265
2.753604 1.522341 1.004834 0.411547 0.330440
0.308768 0.478342 0.137196 1443.064331
RACINES
N