Partie 1
Création et manipulation des schémas - CREATE, ALTER, DROP
Préambule
1. Règles de nommage
2. Au début était le néant...
2.1. La connexion
2.2. La session
2.3. Catalogues et shémas
3. Créer une nouvelle base de données
4. Une question de caractères...
4.1. Jeu de caractères
4.2. Collation et "translation"
4.3. Résumons...
5. Types de données et domaines
5.1. Les types SQL 2
5.1.1. Détails des différents types de données...
5.1.2. Typage rapide avec des préfixes
5.2. Les nouveaux types SQL 3
5.3. Types communs présent dans certains SGBDR des différents éditeurs
5.4. Définir des domaines et les utiliser
Préambule
NOTA : La structure de la base de données exemple, ainsi qu'une version des principales bases utilisées sont disponibles dans la page "La base de données exemple"
Sans doute allez-vous immédiatement vous intéresser à la syntace du CREATE TABLE. C'est pour cela, sans doute, que vous êtes tombé sur cette page... Je vous plains car vous allez tout droit créer des bases de données boiteuses et rapidement impossible à maintenir. Si j'avais un conseil à vous donner ce serait le suivant : lisez les paragraphes 2 à 4 avant même de vous plonger, tête baissée dans la création des tables. Il y a tant de choses qui vous faciliteront la vie que je gage que vous m'en serez éternellement reconnaissant...
1. Règles de nommage
La norme SQL 2 impose un certain nombre de règles concernant les noms des objets d'une base de données.
Un nom d'objet (table, colonne, contrainte, vue...) doit avoir les caractéristiques suivantes :
- ne pas dépasser 128 caractères
- commencer par une lettre
- comprendre uniquement les caractères suivants [ 'A' .. 'Z'] U ['a' .. 'z'] U [ '0' .. '1'] U [ '_' ]
- un nom d'objet ne peut pas être un mot réservé de SQL sauf à être utilisé avec des guillemets
- être insensible à la casse
Voici quelques identifiants normatifs et non...
Exemple 1
| VALABLE |
INTERDIT |
T_CLIENT
xyz
SELECTION
"SELECT"
CLI_NUM
NUM_CLI
|
01_INFORMATIQUE
_XyZ_
SELECT
MOTDEPLUSDE128CARACTERES...
CLI#
#CLI
|
ATTENTION : un nom d'objet doit être unique au sein de l'objet qui le contient. Par exemple un nom de table ou de vue doit être unique au sein de la base, un nom de colonne doit être unique au sein de la table ou la vue, etc...
2. Au début était le néant...
C'est toujours la même histoire... Comment créer une base de données ? En se connectant au serveur de bases de données ! Mais comment se connecter au serveur de base de données ? En créant une base de données dotée au moins d'une connexion et d'un utilisateur avec les privilèges adéquats... Bref, nous entrons de plein front dans le célèbre problème de l'oeuf et de la poule...
Heureusement la plupart du temps, les fournisseurs de SGBDR pourvoient leur engin avec un utilisateur, son mot de passe et un certain nombre de bases de données précréés afin de nous faciliter la vie.
Par exemple sur InterBase le nom d'utilisateur et son mot de passe sont "SYSDBA/masterkey". Sur MS SQL Server, le nom d'utilisateur est "sa" sans mot de passe (et je vous conseille vivement d'en mettre un immédiatement). Sur Oracle, c'est "System/manager" ou bien "Sys/change_on_install". Sur DB2 c'est "db2admin". Sur Informix un compte "informix" est créé dans le goupe "informix-admin". Sous mySQL c'est "mysqladm" qu'il faut utiliser... Ingres est plus restrictif puisqu'il impose à l'utilisateur de donner expressément un nom lors de l'installation. Pour Sybase et ses deux bases, des différences : ASE veut "sa" sans mot de passe, tandis que ASA impose "DBA/SQL" !
En fait tout ces "comptes" sont des connexions au serveur et la plupart du temps correspondent à la fois à la notion de connexion et d'utilisateur. Mais la norme SQL fait une différence entre le concept de connexion et celui d'utilisateur.
2.1. La connexion
Pour SQL 2, la connexion à un SGBDR prend la syntaxe suivante :
CONNECT TO {DEFAULT | nom_serveur [AS surnom_serveur ]
[USER nom_utilisateur] }
Par exemple l'ordre :
Exemple 2
CONNECT TO DEFAULT
Se connecte au serveur de base de données défini par défaut. La plupart du temps un serveur de bases de données est installé sur une machine dédiée, ce qui fait qu'il n'y a pas d'ambiguïté. En revanche, si plusieurs serveurs sont installés sur la même machine, il faut nommer le serveur.
Exemple 3
CONNECT TO MON_SERVEUR
Se connecte au serveur identifié "MON_SERVEUR".
Il est même possible de renommer ce serveur :
Exemple 4
CONNECT TO MON_SERVEUR AS SRV1
Qui se connecte à "MON_SERVEUR", mais le surnomme SRV1. Dès lors ce nouveau nom pourra être utilisé dans divers ordres SQL en lieu et place du nom authentique du serveur.
Enfin, il est possible de préciser le nom de l'utilisateur (qui doit exister dans le SGBDR) qui sera associé à la connexion. Sans cette précision, le SGBDR emprunte le nom par défaut implanté par le constructeur.
Exemple 5
CONNECT TO MON_SERVEUR USER FRED_BROUARD
Se connecte au serveur "MON_SERVEUR" en empruntant l'identité FRED_BROUARD comme utilisateur.
Vous l'aurez compris, à une connexion est toujours associée un nom d'utilisateur. Petite précision, un utilisateur SQL est un objet du serveur (ou de la base de données dans certains cas) et se définit aussi par un ordre SQL...
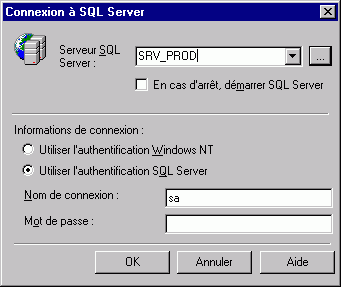
NOTA : la plupart du temps, ce mécanisme est masqué par une interface graphique, oue encore par l'imbrication du serveur de bases de données et de son OS. Par exemple pour SQL Server de Microsoft, cet ordre de connexion s'effectue derrière la boîte de dialogue suivante :
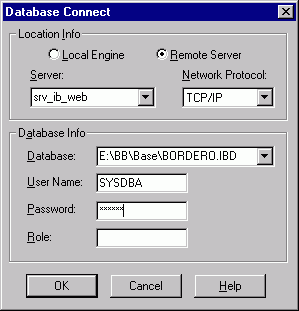
Pour InterBase, c'est la boîte de dialogue suivante qui fait office :
Mais si vous désirez passer des ordre SQL InterBase en vous connectant à une base spécifique et ceci depuis une commande du shell, vous pouvez lancer l'ordre suivant :
Exemple 6 (Interbase)
CONNECT "chemin_vers_fichier_base"
USER "nom_utilisateur" PASSWORD "mot_de_passe"
La norme SQL propose en outre la possibilité de basculer d'une connexion à l'autre (à condition que l'autre existe et soit dormante à l'aide de l'ordre :
SET CONNECTION { DEFAULT | nom_session }
Où nom_session représente une connexion déjà établie et dormante (c'est à dire une connexion ouverte mais qui n'est pas activée par le passage d'ordre SQL...).
Bien entendu il est possible de fermer une connexion en utilisant l'ordre SQL DISCONNECT :
DISCONNECT { DEFAULT | CURRENT | ALL | nom_session}
La lecture de cette syntaxe laisse bien peu d'interprétation et je laisse donc à votre sagacité le soin de comprendre à quoi peuvent bien faire penser de tels mots clefs !
2.2. La session
Là nous entrons déjà dans une notion plus complète et donc, forcément plus complexe...
Une session au sens de la norme SQL est une connexion activé et possède certains attributs particuliers. Les attributs d'une session sont :
- un identifiant d'autorisation (AUTHORIZATION)
- un nom de catalogue (CATALOG)
- un nom de schéma (SCHEMA)
- un fuseau horaire (TIME ZONE)
- un jeu de caractères (CHARACTER SET)
L'identifiant d'autorisation doit impérativement être choisit parmi les mots clefs suivants USER, CURRENT_USER, SESSION_USER et SYSTEM_USER ou bien en donnant un nom d'utilisateur spécifique.
Un catalogue (CATALOG est le mot clef SQL) est une collection de bases de données et peut soit prendre la forme d'un serveur, d'un groupe de serveurs ou bien de "répertoires" de bases de données.
Un schéma n'est autre qu'une base de données, c'est à dire son nom. La norme SQL les apellent SCHEMA parce qu'une base de données doit être décrite pour être utilisée, et son architecture (tables, colonnes, vues...) correspond à un modèle de données physique.
Un fuseau horaire (TIME ZONE) n'est autre que l'indication du décalage de l'heure locale par rapport au temps universel (ou UTC Unified Time Coordination). C'est ainsi qu'il permet de gérer les décalages horaires de toutes les zones locales de la planète ce qui est bien pratique lorsque l'on veut développer une application internationale, notamment pour les sites web !
Enfin, le jeu de caractère (CHARACTER SET) permet de définir quel sous ensemble de symboles est utilisé pour les 256 combinaisons de deux octets qui correspondent à la frappe des caractères. N'oublions pas que même en europe les jeux de caractères ne sont pas les mêmes d'une nation à l'autre. Par exemple l'alphabet finois ou le tchèque sont dotés de curieux petits accents en forme de cercle ou de croissant, tandis que dans le cyrillique c'est la forme même des lettres qui change... et tout de même, ces gens là doivent pouvoir s'exprimer ! (notons que le français possède un certains nombre de caractères particulier comme le "c" avec ça cédille ou l'"e" dans l'"o", présent par exemple dans le mot coeur).
2.3. Catalogues et shémas
Comme nous venons de le définir, le terme CATALOG permet de définir une collection de bases de données. Il est très différemment implémenté dans les divers SGBDR que proposent les éditeurs. Pour SQL Server la notion de CATALOG se confond avec celle de base de données, tandis que la notion de schéma se confond avec celle de propriétaire. Par exemple en demandant à la machine de nous fournir la liste des bases de données avec la requête suivante, voici ce que le serveur nous propose :
Exemple 7 (SQL Server)
SELECT *
FROM
INFORMATION_SCHEMA.SCHEMATA
|
CATALOG SCHEMA SCHEMA DEFAULT_CHARAC DEFAULT_CHARAC DEFAULT_CHARA
_NAME _NAME _OWNER TER_SET_CATALOG TER_SET_SCHEMA CTER_SET_NAME
--------- ------ ------ --------------- -------------- -------------
master dbo dbo master dbo iso_1
tempdb dbo dbo master dbo iso_1
model dbo dbo master dbo iso_1
msdb dbo dbo master dbo iso_1
pubs dbo dbo master dbo iso_1
Northwind dbo dbo master dbo iso_1
|
3. Créer une nouvelle base de données
Évidemment ce qui vous intéresse le plus c'est d'abord de créer une base de données. C'est à dire un SCHEMA !
La norme SQL propose l'ordre de création d'une base de données (pardon, d'un schéma) suivant :
CREATE SCHEMA [ nom_schema ]
[ AUTHORIZATION utilisateur ]
[ DEFAULT CHARACTER SET jeu_de_caractères ]
[ liste_des_objets_du_schéma ]
La liste des objets du schéma n'étant autre que la création des éléments de la base.
Je ne m'étendrais pas sur cette syntaxe ni sur l'ordre SQL 2 de suppression des schémas :
DROP SCHEMA [ nom_schema ] { RESTRICT | CASCADE }
car ces ordres sont très rarement implémentés tels quels dans les SGBDR. En revanche on trouve la plupart du temps un pseudo ordre SQL "CREATE DATABASE" fort pratique, mais qui n'existe nulle part dans la norme !
Mais si j'ai tenu à vous montrer ceci, c'est que, par défaut, une connexion ou un serveur possède des attributs. Les méconnaitre et notamment en méconnaitre le paramétrage peut vous causer les pires ennuis. C'est pourquoi je vous propose de réfléchir sur trois questions fondamentales :
- Quel est l'ordre de tri de mes données littérales ?
- Comment s'effectue la comparaison entre colonnes contenant des chaînes de caractères notamment si ces dernières sont de type différent (VARCHAR et CHAR en particulier) ?
- Quelle est à tout moment l'heure et la date procurée par le SGBDR et cette heure est-elle modifiée en fonction des saisons ???
Si vous n'avez pas réfléchis à ces problèmes fondamentaux, vous risquez quelques problèmes difficilement surmontables...
Par exemple :
- Comment faire correspondre l'ordre de mes données entre un tableau trié par une routine en C++, Java ou Delphi et le serveur de base de données ?
- Comment faire en sorte de distinguer les deux références suivantes "GFY-12-aj" et "gfy-12-AJ" dans un SELECT si le serveur a été paramétré pour être rendu insensible à la casse ??
- Comment compter exactement la durée d'une intervention technique en heure si entre la déclaration de la panne et la résolution du problème est intervenu un changement d'horaire du fait de l'heure d'éte ???
Je ne m'étendrais donc pas plus sur le sujet car il est assez spécifique aux différents SGBDR de chaque éditeur. Pensez simplement que l'installation par défaut du serveur prôné avec un gadget qui le rend insensible à la casse est une aberration. En effet, autant il est facile de formater des données pour que la comparaison et même la saisie se fasse au bon format, autant lorsque cette insensibilité est activée, le coût de retour en arrière est exorbitant !
Faîtes donc le test suivant. Créez dans votre base de données la table et les données suivantes :
Exemple 8
CREATE TABLE TEST
(MOT VARCHAR(16))
INSERT INTO TEST VALUES ('Électricité')
INSERT INTO TEST VALUES ('électricité')
INSERT INTO TEST VALUES ('ELECTRICITE')
INSERT INTO TEST VALUES ('electricite')
INSERT INTO TEST VALUES ('electron')
INSERT INTO TEST VALUES ('electeur')
INSERT INTO TEST VALUES ('électeur')
Executez donc les requêtes de test suivantes :
Exemple 9
SELECT MOT
FROM TEST
WHERE MOT = 'electricite'
En principe vous devriez n'avoir qu'une seule occurence...
Exemple 10
SELECT MOT
FROM TEST
ORDER BY MOT
Là, le folklore est en place !
Puis créez dans votre langage favori un tableau de chaîne de caractères et avec une routine de tri de votre cru, triez le et comparez les résultats...
Vous êtes horrifié ? Bien fait !... Vous auriez dû me lire avant de vous lançer dans la conception des bases de données relationnelles !!!
Voici ce test effectué sous différentes bases de données :
| |
SELECT MOT
FROM TEST
WHERE MOT
= 'electricite'
|
SELECT MOT
FROM TEST
ORDER BY MOT
|
| Sous MS SQL Server 7, paramétrage par défaut |
MOT
-----------
ELECTRICITE
electricite
|
MOT
-----------
electeur
électeur
ELECTRICITE
Électricité
électricité
electricite
electron
|
| Sous PostGreSQL 7.1.2, paramétrage par défaut |
mot
-----------
electricite
|
mot
-------------
electeur
électeur
electricite
ELECTRICITE
électricité
Électricité
electron
|
| Sous InterBase 5.5, paramétrage par défaut |
MOT
===========
electricite
|
MOT
===========
electricite
|
| Sous paradox 9, paramétrage par défaut |
MOT
***********
electricite
|
MOT
***********
electricite
|
| MySQL 3.23.37, paramétrage par défaut |
+-------------+
| MOT |
+-------------+
| Électricité |
| électricité |
| ELECTRICITE |
| electricite |
+-------------+
|
+-------------+
| MOT |
+-------------+
| electeur |
| électeur |
| Électricité |
| électricité |
| ELECTRICITE |
| electricite |
| electron |
+-------------+
|
4. Une question de caractères...
4.1. Jeu de caractères
Je vais encore vous embêter avec un concept qui, la plupart du temps est ignoré ou passé sous silence, mais qui permet de se sauver de situation inextricables portant sur la comparaison des littéraux. La norme SQL a prévu, outre le jeu de caractère, l'utilisation de séquences de collation. Même si elle ne sont pas encore parfaitement implantées telle que la norme SQL 2 l'a prévue, il est rare qu'un mécanisme similaire ne soit pas fournit dans votre SGBDR.
Le jeu de caractères consiste en une correspondance des 256 ou 65536 caractères par rapport aux symboles graphiques représentés.
256 correspond au type CHAR et VARCHAR et 65536 aux types NATIONAL CHAR ou NATIONAL VARCHAR. La plupart du temps nous utilisons sans le savoir un jeu de caractères basique établis par défaut dans la version locale de l'OS.
Voici par exemple les jeux de caractères disponible dans les créations de tables de Paradox :
Exemple 11
| ANSI 1250 |
chèque, hongrois polonais, slovène |
| ANSI 1251 |
cyrillique et bulgare |
| ANSI 1252 |
nordique, espagnol, suédois, finlandais |
| ANSI 1253 |
greque |
| ANSI 1254 |
turque |
| ANSI 1255 |
binaire |
| DOS 437 |
europe de l'ouest, suèdois, finlandais, espagnol |
| DOS 737 |
greque |
| DOS 850 |
brésilien, portugais, canadien, français |
| DOS 852 |
chèque, hongrois polonais, slovène |
| DOS 857 |
turque |
| DOS 861 |
islandais |
| DOS 862 |
binaire |
| DOS 865 |
norvégien, danois |
| DOS 866 |
cyrillique |
| DOS 867 |
tchèque |
| DOS 868 |
bulgare |
| DOS 874 |
thaïlandais |
| DOS 932 |
japonais |
| DOS 936 |
chinois |
| DOS 949 |
coréen |
| DOS 950 |
tawainais |
Notez qu'ils sont décomposés en deux familles, celle du DOS (la table des caractères de base n'étant pas normalisé mais propre à l'inventeur du système d'exploitation DOS...) et celle de l'ANSI (relatif à Windows qui se base sur la norme ANSI - American National Standard Institute).
On parle souvent de table ASCII. L'ASCII a été créé par BEMMER en 1965 , produit par le groupe de travail X3.4 de l'ANSI, certifié en 1977 et adopté par l'ISO en 1968 sous le n° 646 [f2s]. Ce ne sont en fait que les 128 premiers caractères du fait du codage à l'origine sur 7 bits. Lorsque le codage des caractères à été étendu par nécessité à 8 bits, des déclinaisons de cette table ont été possible pour régler le problème des caractères diacritiques (accents, cédilles, caractères spéciaux tel que le double ss allemand).
Rassurez vous l'ISO (International Standard Organisation) s'en est mêlé et propose des jeux de caractères plus cohérent. Voici par exemple la table iso8859-1, actuellement la plus répandue et la plus utilisée notamment sur le net :
Exemple 12
iso8859-1 character table and corresponding HTML code
Description Code Charactèr name
=================================== ============ ==============
guillemet " --> " " --> "
et commercial & --> & & --> &
signe plus petit que < --> < < --> <
greater-than sign > --> > > --> >
Description Char Code Entity name
=================================== ==== ============ ==============
espace non sécable   --> -->
exclamation inverse ¡ ¡ --> ¡ ¡ --> ¡
centimes ¢ ¢ --> ¢ ¢ --> ¢
livre sterling £ £ --> £ £ --> £
symbole monétère général ¤ ¤ --> ¤ ¤ --> ¤
symbole du yen ¥ ¥ --> ¥ ¥ --> ¥
barre verticale brisée ¦ ¦ --> ¦ ¦ --> ¦
&brkbar; --> &brkbar;
paragraphe § § --> § § --> §
umlaut (dieresis) ¨ ¨ --> ¨ ¨ --> ¨
¨ --> ¨
copyright © © --> © © --> ©
feminine ordinal ª ª --> ª ª --> ª
guillement gauche « « --> « « --> «
not sign ¬ ¬ --> ¬ ¬ --> ¬
soft hyphen ­ --> ­ -->
registered trademark ® ® --> ® ® --> ®
macron accent ¯ ¯ --> ¯ ¯ --> ¯
&hibar; --> &hibar;
signe des degrés ° ° --> ° ° --> °
plus ou moins ± ± --> ± ± --> ±
puissance carrée ² ² --> ² ² --> ²
puissance cubique ³ ³ --> ³ ³ --> ³
accent aigu ´ ´ --> ´ ´ --> ´
symbole micro µ µ --> µ µ --> µ
symbole de paragraphe ¶ ¶ --> ¶ ¶ --> ¶
point central · · --> · · --> ·
cédille ¸ ¸ --> ¸ ¸ --> ¸
exposant un ¹ ¹ --> ¹ ¹ --> ¹
masculine ordinal º º --> º º --> º
guillement droit » » --> » » --> »
un quart (fraction) ¼ ¼ --> ¼ ¼ --> ¼
un demi (fraction) ½ ½ --> ½ ½ --> ½
trois quart (fraction) ¾ ¾ --> ¾ ¾ --> ¾
point d'interrogation inversé ¿ ¿ --> ¿ ¿ --> ¿
A accent grave (majuscule) À À --> À À --> À
A accent aigu (majuscule) Á Á --> Á Á --> Á
A accent circonflexe (majuscule) Â Â --> Â Â --> Â
A tilde (majuscule) Ã Ã --> Ã Ã --> Ã
capital A, dieresis or umlaut mark Ä Ä --> Ä Ä --> Ä
capital A, ring Å Å --> Å Å --> Å
capital AE diphthong (ligature) Æ Æ --> Æ Æ --> Æ
capital C, cedilla Ç Ç --> Ç Ç --> Ç
capital E, grave accent È È --> È È --> È
capital E, acute accent É É --> É É --> É
capital E, circumflex accent Ê Ê --> Ê Ê --> Ê
capital E, dieresis or umlaut mark Ë Ë --> Ë Ë --> Ë
capital I, grave accent Ì Ì --> Ì Ì --> Ì
capital I, acute accent Í Í --> Í Í --> Í
capital I, circumflex accent Î Î --> Î Î --> Î
capital I, dieresis or umlaut mark Ï Ï --> Ï Ï --> Ï
capital Eth, Icelandic Ð Ð --> Ð Ð --> Ð
Đ --> Đ
capital N, tilde Ñ Ñ --> Ñ Ñ --> Ñ
capital O, grave accent Ò Ò --> Ò Ò --> Ò
capital O, acute accent Ó Ó --> Ó Ó --> Ó
capital O, circumflex accent Ô Ô --> Ô Ô --> Ô
capital O, tilde Õ Õ --> Õ Õ --> Õ
capital O, dieresis or umlaut mark Ö Ö --> Ö Ö --> Ö
multiply sign × × --> × × --> ×
capital O, slash Ø Ø --> Ø Ø --> Ø
capital U, grave accent Ù Ù --> Ù Ù --> Ù
capital U, acute accent Ú Ú --> Ú Ú --> Ú
capital U, circumflex accent Û Û --> Û Û --> Û
capital U, dieresis or umlaut mark Ü Ü --> Ü Ü --> Ü
capital Y, acute accent Ý Ý --> Ý Ý --> Ý
capital THORN, Icelandic Þ Þ --> Þ Þ --> Þ
small sharp s, German (sz ligature) ß ß --> ß ß --> ß
small a, grave accent à à --> à à --> à
small a, acute accent á á --> á á --> á
small a, circumflex accent â â --> â â --> â
small a, tilde ã ã --> ã ã --> ã
small a, dieresis or umlaut mark ä ä --> ä ä --> ä
small a, ring å å --> å å --> å
small ae diphthong (ligature) æ æ --> æ æ --> æ
small c, cedilla ç ç --> ç ç --> ç
small e, grave accent è è --> è è --> è
small e, acute accent é é --> é é --> é
small e, circumflex accent ê ê --> ê ê --> ê
small e, dieresis or umlaut mark ë ë --> ë ë --> ë
small i, grave accent ì ì --> ì ì --> ì
small i, acute accent í í --> í í --> í
small i, circumflex accent î î --> î î --> î
small i, dieresis or umlaut mark ï ï --> ï ï --> ï
small eth, Icelandic ð ð --> ð ð --> ð
small n, tilde ñ ñ --> ñ ñ --> ñ
small o, grave accent ò ò --> ò ò --> ò
small o, acute accent ó ó --> ó ó --> ó
small o, circumflex accent ô ô --> ô ô --> ô
small o, tilde õ õ --> õ õ --> õ
small o, dieresis or umlaut mark ö ö --> ö ö --> ö
division sign ÷ ÷ --> ÷ ÷ --> ÷
small o, slash ø ø --> ø ø --> ø
small u, grave accent ù ù --> ù ù --> ù
small u, acute accent ú ú --> ú ú --> ú
small u, circumflex accent û û --> û û --> û
small u, dieresis or umlaut mark ü ü --> ü ü --> ü
small y, acute accent ý ý --> ý ý --> ý
small thorn, Icelandic þ þ --> þ þ --> þ
small y, dieresis or umlaut mark ÿ ÿ --> ÿ ÿ --> ÿ
Autrement dit, le jeux de caractères restreint à 256 symboles ASCII les possibilités de combiner les lettres, signes de ponctuation et autres caractères particulier imprimables.
4.2. Collation et "translation"
La séquence de collation est un complément indispensable du jeu de caractères et permet de définir non seulement la position ordinale de chaque caractère mais leur éventuelle "confusion" ! Hé oui, comment pensez vous que la machine puisse devenir insensible à la casse et aux accents sans un tel mécanisme ?
C'est ainsi que différentes séquence de collation sont possible sur un même jeu de caractères.
Voici par exemple les séquences de collation des différents jeux de caractères de Paradox :
Exemple 12
| Jeu de caractère |
Classement des caractères |
| 1250 (ANSI) |
Compatible avec Paradox "czech" (niveau 2)
Compatible avec Paradox "hung" (niveau 2)
Paradox Czech (niveau 2)
Compatible avec Paradox "polish" (niveau 2)
Compatible avec Paradox "slovene" (niveau 2) |
| 1251 (ANSI) |
Compatible avec Paradox "cyrr" (2-level)
Bulgarian (2-level) |
| 1252 (ANSI) |
Compatible avec Paradox "intl" (niveau 3)
Compatible avec Paradox "nordan40" (niveau 2)
Compatible avec Paradox "SPANISH" (niveau 3)
Compatible avec Paradox "swedfin" (niveau 3) |
| 1253 (ANSI) |
Compatible avec Paradox "greek" (niveau 2) |
| 1254 (ANSI) |
Compatible avec Paradox "turk" (niveau 2) |
| 1255 (ANSI) |
Binaire |
| DOS CODE PAGE 437 |
Binaire
Multilingual Western Europe
Swedish/Finnish
Spanish (niveau 3) |
| DOS CODE PAGE 737 |
Greek (niveau 2) |
| DOS CODE PAGE 850 |
Brazilian Portuguese, French Canadian
Compatible avec Paradox "intl850" (niveau 3) |
| DOS CODE PAGE 852 |
Czech852 (niveau 2)
Hungarian (niveau 2)
Polish (niveau 2)
Slovene (niveau 2) |
| DOS CODE PAGE 857 |
Turkish (niveau 2) |
| DOS CODE PAGE 861 |
Icelandic (niveau 2) |
| DOS CODE PAGE 862 |
Binaire |
| DOS CODE PAGE 865 |
Norwegian/Danish (Paradox 3.5)
Norwegian/Danish (Paradox 4.0, 5.0, 5.5, 7.0) |
| DOS CODE PAGE 866 |
Cyrillic |
| DOS CODE PAGE 867 |
Czech867 (niveau 2) |
| DOS CODE PAGE 868 |
Bulgaria (niveau 2) |
| DOS CODE PAGE 874 |
Thai (niveau 3) |
| DOS CODE PAGE 932 |
Japanese |
| DOS CODE PAGE 936 |
China (niveau 1) |
| DOS CODE PAGE 949 |
Korea (niveau 1) |
| DOS CODE PAGE 950 |
Taiwan (niveau 1) |
Par exemple dans la séquence de collation ISO 1252 spanish, le "ñ" ("n" avec tilde) sera confondu avec le caractère "n" lors des comparaisons partielles...
Pour InterBase par exemple, les jeux de caractères disponibles sont les suivants :
Exemple 14
SELECT RDB$CHARACTER_SET_NAME,
RDB$CHARACTER_SET_ID,
RDB$DEFAULT_COLLATE_NAME
FROM RDB$CHARACTER_SETS
|
RDB$CHARACTER_SET_NAME RDB$CHARACTER_SET_ID RDB$DEFAULT_COLLATE_NAME
====================== ==================== ========================
NONE 0 NONE
OCTETS 1 OCTETS
ASCII 2 ASCII
UNICODE_FSS 3 UNICODE_FSS
SJIS_0208 5 SJIS_0208
EUCJ_0208 6 EUCJ_0208
DOS437 10 DOS437
DOS850 11 DOS850
DOS865 12 DOS865
ISO8859_1 21 ISO8859_1
DOS852 45 DOS852
DOS857 46 DOS857
DOS860 13 DOS860
DOS861 47 DOS861
DOS863 14 DOS863
CYRL 50 CYRL
WIN1250 51 WIN1250
WIN1251 52 WIN1251
WIN1252 53 WIN1252
WIN1253 54 WIN1253
WIN1254 55 WIN1254
NEXT 19 NEXT
KSC_5601 44 KSC_5601
BIG_5 56 BIG_5
GB_2312 57 GB_2312
|
Auxquels sont associés les séquences de collations suivantes :
Exemple 15
SELECT RDB$COLLATION_NAME,
RDB$COLLATION_ID,
RDB$CHARACTER_SET_ID
FROM RDB$COLLATIONS C
JOIN RDB$CHARACTER_SETS S
ON C.RDB$CHARACTER_SET_ID =
S.RDB$CHARACTER_SET_ID
|
RDB$COLLATION_NAME RDB$COLLATION_ID RDB$CHARACTER_SET_ID
==================== ================ ====================
NONE 0 0
OCTETS 0 1
ASCII 0 2
UNICODE_FSS 0 3
SJIS_0208 0 5
EUCJ_0208 0 6
DOS437 0 10
PDOX_ASCII 1 10
PDOX_INTL 2 10
PDOX_SWEDFIN 3 10
DB_DEU437 4 10
DB_ESP437 5 10
DB_FIN437 6 10
DB_FRA437 7 10
DB_ITA437 8 10
DB_NLD437 9 10
DB_SVE437 10 10
DB_UK437 11 10
DB_US437 12 10
DOS850 0 11
DB_FRC850 1 11
DB_DEU850 2 11
DB_ESP850 3 11
DB_FRA850 4 11
DB_ITA850 5 11
DB_NLD850 6 11
DB_PTB850 7 11
DB_SVE850 8 11
DB_UK850 9 11
DB_US850 10 11
DOS865 0 12
PDOX_NORDAN4 1 12
DB_DAN865 2 12
DB_NOR865 3 12
ISO8859_1 0 21
DA_DA 1 21
DU_NL 2 21
FI_FI 3 21
FR_FR 4 21
FR_CA 5 21
DE_DE 6 21
IS_IS 7 21
IT_IT 8 21
NO_NO 9 21
ES_ES 10 21
SV_SV 11 21
EN_UK 12 21
EN_US 14 21
PT_PT 15 21
DOS852 0 45
DB_CSY 1 45
DB_PLK 2 45
DB_SLO 4 45
PDOX_CSY 5 45
PDOX_PLK 6 45
PDOX_HUN 7 45
PDOX_SLO 8 45
DOS857 0 46
DB_TRK 1 46
DOS860 0 13
DB_PTG860 1 13
DOS861 0 47
PDOX_ISL 1 47
DOS863 0 14
DB_FRC863 1 14
CYRL 0 50
DB_RUS 1 50
PDOX_CYRL 2 50
WIN1250 0 51
PXW_CSY 1 51
PXW_HUNDC 2 51
PXW_PLK 3 51
PXW_SLOV 4 51
WIN1251 0 52
PXW_CYRL 1 52
WIN1252 0 53
PXW_INTL 1 53
PXW_INTL850 2 53
PXW_NORDAN4 3 53
PXW_SPAN 4 53
PXW_SWEDFIN 5 53
WIN1253 0 54
PXW_GREEK 1 54
WIN1254 0 55
PXW_TURK 1 55
NEXT 0 19
NXT_US 1 19
NXT_DEU 2 19
NXT_FRA 3 19
NXT_ITA 4 19
NXT_ESP 5 19
KSC_5601 0 44
KSC_DICTIONARY 1 44
BIG_5 0 56
GB_2312 0 57
|
Comment cela se passe à l'intérieur et à quoi cela correspond-t-il ? Jetons un coup d'oeil à la procédure stockée sp_helpsort de MS SQL Server et tout va devenir plus lumineux...
Exemple 15
sp_helpsort
|
Unicode data sorting
----------------------
Locale ID = 1033
case insensitive, kana type insensitive, width insensitive
Sort Order Description
------------------------------------------------------------------
Character Set = 1, iso_1
ISO 8859-1 (Latin-1) - Western European 8-bit character set.
Sort Order = 52, nocase_iso
Case-insensitive dictionary sort order for use with several
Western-European languages including English, French, and German.
Uses the ISO 8859-1 character set.
Characters, in Order
-------------------------------------------------------------------
! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ ` { | }
~ ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾
¿ × ÷ 0 1 2 3 4 5 6 7 8 9 A=a À=à Á=á Â=â Ã=ã Ä=ä Å=å Æ=æ B=b C
=c Ç=ç D=d E=e È=è É=é Ê=ê Ë=ë F=f G=g H=h I=i Ì=ì Í=í Î=î Ï=ï J
=j K=k L=l M=m N=n Ñ=ñ O=o Ò=ò Ó=ó Ô=ô Õ=õ Ö=ö Ø=ø P=p Q=q R=r S
=s ß T=t U=u Ù=ù Ú=ú Û=û Ü=ü V=v W=w X=x Y=y Ý=ý ÿ Z=z Ð=ð Þ=þ
|
Comme on le voit, l'ordre de chacun des caractères est établi par la séquence, mais comme cette séquence de collation est rendue insensible à la casse, il y a confusion entre les majuscules et les minuscules...
Autrement dit, l'ordre de tri, comme la correspondance des recherches que l'on effectuera dans des requêtes SQL sera prédéfini par la séquence de collation. La méconnaître et méconnaître les possibilités de paramétrage de son SGBDR a ce niveau, c'est laisser faire Microsoft, Oracle ou Borland, comme il l'entend et non comme vous voulez que ce soit et rejaillira tôt ou tard comme problématique dans la mise au point de vos applications...
Sachez qu'en général, une séquence de collation par défaut est proposée lors de l'installation de votre serveur, et que sur certains SGBDR on peut modifier la séquence de collation pour la table entière ou encore pour une colonne seulement.
Bien entendu la norme SQL 2 a codifié et penser cela depuis fort longtemps et propose même des mécanismes de traduction afin de faire correspondre des données venant de jeux et collations différentes, mais ces possibilités sont encore trop rares à être implémentées au sein des SGBDR des différents éditeurs. Ainsi SQL 2 a défini les CREATE CHARACTER SET et CREATE COLLATION afin de répondre à toutes les attentes. Malheureusement la plupart du temps il n'est possible d'utiliser que les jeux et collations prédéfinies par l'éditeur du SGBDR.
Par exemple Microsoft dans la version 7 de sa base de données SQL Server était très en retard sur le sujet. Un seul jeu de caractères et une seule séquence de collation pouvait être utilisé au sein du serveur ! Comme le serveur était mono instance, il fallait autant de serveur (machine) que d'application pour les différents pays d'exploitation de la base de données, ce qui rendait SQL Server difficile comme choix pour des applications Internet internationales, sauf à utiliser quelques "trucs" et "bouts de ficelles" à base d'UNICODE... En revanche, de ce côté, un modeste serveur comme InterBase était fort bien pensé !
Par exemple pour InterBase, lors de la création d'une base de données, on peut préciser le jeu de caractères :
Exemple 17
CREATE DATABASE 'production.gdb'
DEFAULT CHARACTER SET 'ISO8859_1'
On peut aussi le faire pour chaque colonne dans la création de table :
Exemple 18
CREATE TABLE TEST_CHAR_SET
(COL1 CHAR(32) CHARACTER SET ASCII,
COL2 CHAR(32) CHARACTER SET DOS437,
COL3 CHAR(32) CHARACTER SET DOS850)
Et préciser en outre la collation utilisée :
Exemple 19
CREATE TABLE TEST_COLLATION
(COL1 CHAR(32) CHARACTER SET ISO8859_1 COLLATE FR_FR,
COL2 CHAR(32) CHARACTER SET ISO8859_1 COLLATE ISO8859_1)
Mais attention, pas question de rentrer n'importe quoi dans la table, le serveur veille en général à la correspondances des jeux dans les entrées/sortie de flux d'information (requêtes et ensemble de résultats).
Ainsi en alimentant la table TEST_COLLATION avec les mêmes données pour les deux colonnes...
Exemple 20
INSERT INTO TEST_COLLATION VALUES ('Électricité', 'Électricité')
INSERT INTO TEST_COLLATION VALUES ('électricité', 'électricité')
INSERT INTO TEST_COLLATION VALUES ('ELECTRICITE', 'ELECTRICITE')
INSERT INTO TEST_COLLATION VALUES ('electricite', 'electricite')
INSERT INTO TEST_COLLATION VALUES ('electron', 'electron')
INSERT INTO TEST_COLLATION VALUES ('electeur', 'electeur')
INSERT INTO TEST_COLLATION VALUES ('électeur', 'électeur')
...nous n'obtiendrons pas le même ordre de tri :
Exemples 21 et 22
SELECT COL1
FROM TEST_COLLATION
ORDER BY COL1
|
COL1
===========
electeur
électeur
electricite
ELECTRICITE
électricité
Électricité
electron
|
SELECT COL2
FROM TEST_COLLATION
ORDER BY COL2
|
COL2
===========
ELECTRICITE
electeur
electricite
electron
Électricité
électeur
électricité
|
NOTA : pour pouvoir utiliser ce jeu d'essais dans votre interface de requêtage vous devez préalablement indiquer au serveur quen vous utilisez le jeu de caractères ISO8859_1 en utilisant la commande SET NAMES d'InterBase ou le paramétrage avancé.
Bien entendu, on peut forcer une séquence de collations dans un select à des fins de comparaison ou de tri. Pour cela il faut utiliser le mot clef COLLATE et donner le nom de la collation de travail :
Exemples 23 et 24
SELECT COL1
FROM TEST_COLLATION
WHERE COL1 COLLATE EN_US = 'électricité'
|
COL1
===========
électricité
|
SELECT COL1
FROM TEST_COLLATION
ORDER BY COL1 COLLATE EN_US
|
COL1
===========
electeur
electricite
ELECTRICITE
electron
Électricité
électeur
électricité
|
C'est pourquoi on ne le répétera jamais assez, ce paramètrage entre jeu de caractères et séquence de collation est délicat et obéi souvent à des mécanismes souvent peu normatifs.
Enfin, je ne saurait trop vous recommander, dans la mesure ou vous le pouvez, de paramétrer votre base de données de la manière suivante :
- Jeu de caractères ISO8859-1
- Sensible à la casse (donc différences entre majuscules et minuscules)
- Sensible aux accents et autres caractères diacritiques
En effet, on peut toujours jouer sur les séquences de collation pour redéfinir l'ordre de tri et utiliser des fonctions de conversion telles que UPPER ou LOWER pour insensibiliser la casse, ou encore des fonctions avancées telles que la fonction TRANSLATION proposée par ORACLE pour s'affranchir des accents et autres caractères diacritiques. N'oubliez pas qu'une séquence de collation complexe (par exemple assimilant les majuscules, minuscules et accents comme équivalents) est forcément couteuse en temps d'exécution et cela rejaillira sur les performances d'accès et de traitement de vos données...
La translation, rarement implémentée consiste à définir un ensemble de correspondances entre caractères. Elle permet de remplacer des caractères par d'autres. Par exemple si nous avons créer une translation nommée REMPLACE_PONCTUATION_ESPACE qui définie que les caractères . , ; : ! ? ' " sont remplacés par un caractères espace, alors l'application de la fonction TRANSLATE avec comme paramètre cet identifiant de translation nous obtiendrons une chaîne de caractères dans laquelle tous les signes de ponctuation mentionnés seront remplacés par des espaces.
Exemples 25
TRANSLATE ('A, B; C>D?' USING REMPLACE_PONCTUATION_ESPACE)
|
'A B C>D '
|
4.3. Résumons...
La norme prévoit la spécification d'un jeu de caractères à l'aide des ordres :
CREATE CHARACTER SET nom_jeu_caractère
[AS] GET nom_jeu_caractère_existant
[COLLATE nom_collation | COLLATION FROM ressource_collation]
DROP CHARACTER SET nom_jeu_caractère
La norme prévoit la spécification d'une collation à l'aide des ordres :
CREATE COLLATION nom_collation
FOR nom_jeu_caractère_existant
FROM ressource_collation
[ PAD SPACE | NO PAD ]
DROP COLLATION nom_collation
Dans les deux cas (CREATE CHARCATER SET et CREATE COLATION), une ressource de collation pouvant elle même être définie comme :
ressource_collation ::
EXTERNAL ( 'collation_externe' )
nom_collation
DESC (nom_collation)
DEFAULT
TRANSLATION nom_traduction [THEN COLLATION nom_colation]
La norme prévoit la spécification d'une translation à l'aide des ordres :
CREATE TRANSLATION nom_translation
FOR jeu_caractere_source
TO jeu_caractère_cible
FROM { EXTERNAL ( 'translation_externe' ) | IDENTITY | nom_translation }
DROP TRANSLATION nom_translation
Une collation peut être spécifiée, caractères par caractères à l'aides d'opérateurs de comparaison.
Exemple 26
a=A a=à a=â a=ä b=B c=C c=ç d=D e=E e=é e=è ...
Dans ce cas, les caractères a, A, à auront la position ordinale 1, b ou B la position ordinale 2, etc... et cette séquence de collation sera insensible à la casse et aux caractères diacritiques...
Le jeu de caractères peut se spécifier dans la création de la base de données :
CREATE SCHEMA nom_base
...
[DEFAULT CHARACTER SET nom_jeu_caractère]
Enfin, une collation peut être utilisée selon la norme SQL 2 dans une comparaison comme dans la clause de tri d'un ordre SELECT.
NOTA : l'implémentation de ces différents éléments varie fortement d'un éditeur de SGBDR à l'autre. C'est pourquoi je vous invite fortement à lire la documentation de votre SGBDR avant de définir votre base et vos tables.
5. Types de données et domaines
Nous avons déjà parlé de ces éléments si vous avez lu le tout premier papier consacré à SQL. Mais comme rien ne vaut un bon rappel, voici ce que sont les domaines et les données de SQL.
5.1. Les types SQL 2
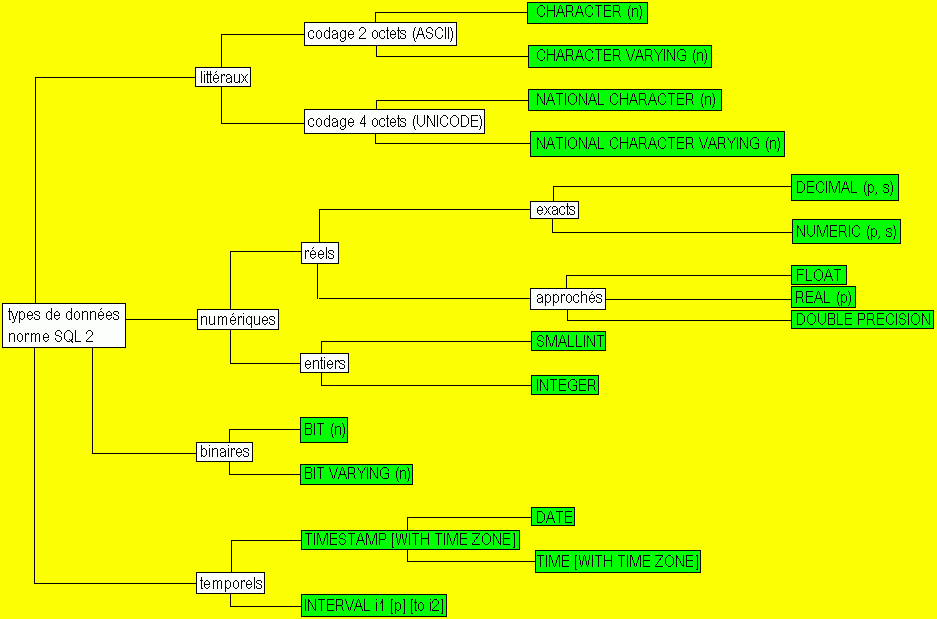
La norme SQL 2 propose 4 familles de types de données : les littéraux, les numériques, les binaires et les temporelles, elles mêmes parfois subdiviées.
Le tableau suivant résume les différents types de données. En vert figurent les types SQL 2 et en blanc les familles et sous familles :
n précise la longeur associé au type, p la précision (nombre de chiffres significatifs), s les décimales et i1 et i2 la précision de durée parmi YEAR, MONTH, DAY, HOUR, MINUTE, SECOND.
5.1.1. Détails des différents types de données...
CHARACTER (n) permet de préciser une données litérale (chaîne de caractères) dont les caractères sont codés sur un jeu de type ASCI, EBCDIC ou DOS (2 octets par caractères) de longueur fixe n. Si la donnée à insérer est de taille inférieure elle est complétée par des blancs significatifs.
Exemple 27
CHARACTER (4)
définit une colonne comportant exactement 4 caractères.
Le synonyme CHAR peut être utilisé.
CHARACTER VARYING (n) permet de préciser une donnée littérale (chaîne de caractères) dont les caractères sont codés sur un jeu de type ASCI, EBCDIC ou DOS de longueur maximale n. Si la donnée à insérer est de taille inférieure elle compactée et aucun caractère blancs significatifs ne la complète.
Exemple 28
CHARACTER VARYING (32)
définit une colonne comportant au maximum 32 caractères.
Le synonyme VARCHAR peut être utilisé
NATIONAL CHARACTER et NATIONALCHARACTERVARYING sont des déclinaisons des deux exemples précédents, mais codés sur le jeu UNICODE, ce qui suppose 4 octets par caractères.
Les synonymes NATIONAL CHAR, NCHAR, NATIONAL CHAR VARYING et NATIONAL VARCHAR peuvent être utilisés.
DECIMAL est un réel représentant un nombre en base 10 sans altération de la précision des chiffres situés après la virgule. La précision p peut aller au dela du maximum prévu pour le traitement des données numérique du processeur.
Exemple 29
DECIMAL (60, 16)
définit une colonne comportant un réel acceptant jusqu'à 60 chiffres significatifs avec 16 chiffres après la virgule. Aucune erreur d'arrondi ne doit apparaître dans le stockage ni les calculs décimaux.
NUMERIC est un réel représentant un nombre en base 10 sans altération de la précision des chiffres situés après la virgule. La précision p ne peut dépasser le maximum prévu pour le traitement des données numérique du processeur.
Exemple 30
DECIMAL (16, 2)
définit une colonne comportant un réel acceptant jusqu'à 16 chiffres significatifs avec 2 chiffres après la virgule. Aucune erreur d'arrondi ne doit apparaître dans la stockage ni les calculs décimaux.
FLOAT est un réel représentant un nombre en base 10 stocké en binaire. La précision p peut aller au dela du maximum prévu pour le traitement des données numérique du processeur.
Exemple 31
FLOAT (64, 16)
définit une colonne comportant un réel codé en binaire acceptant jusqu'à 64 chiffres significatifs avec 16 chiffres après la virgule. Des erreurs d'arrondi peuvent apparaître dans le stockage ou les calculs décimaux.
REAL est un réel représentant un nombre en base 10 stocké en binaire. La précision p ne peut dépasser le maximum prévu pour le traitement des données numérique du processeur sur un nombre de bits déterminé par le système.
Exemple 32
REAL (12, 4)
définit une colonne comportant un réel codé en binaire acceptant jusqu'à 12 chiffres significatifs avec 4 chiffres après la virgule. Des erreurs d'arrondi peuvent apparaître dans le stockage ou les calculs décimaux.
DOUBLE PRECISION est un réel représentant un nombre en base 10 stocké en binaire. La précision p ne peut dépasser le maximum prévu pour le traitement des données numérique du processeur sur un nombre de bits déterminé par le système et plus largement que le REAL.
Exemple 33
DOUBLE PRECISION (18, 6)
définit une colonne comportant un réel codé en binaire acceptant jusqu'à 18 chiffres significatifs avec 6 chiffres après la virgule. Des erreurs d'arrondi peuvent apparaître dans le stockage ou les calculs décimaux.
SMALLINT est un entier représentant un nombre en base 10 stocké en binaire. La précision est fixe et déterminée par le processeur pour un demi mot.
Exemple 34
SMALLINT
définit une colonne comportant un entier codé en binaire dont la plage de valeur est fixée dans l'étendue des capacité du demi mot du processeur. Les calculs et le stockage sont toujours exacts.
INTEGER est un entier représentant un nombre en base 10 stocké en binaire. La précision est fixe et derminée par le processeur pour un mot entier.
Exemple 35
INTEGER
définit une colonne comportant un entier codé en binaire dont la plage de valeur est fixée dans l'étendue des capacités du mot entier du processeur. Les calculs et le stockage sont toujours exacts.
BIT définit une chaîne de bits dont la longueur est fixe.
Exemple 36
BIT(2)
définit une colonne comportant deux bits pouvant avoir les valeurs 00 01 10 ou 11.
BIT VARYING définit une chaîne de bits dont la longueur est variable.
Exemple 37
BIT(8)
définit une colonne comportant au maximum 8 bits pouvant prendre la plage de valeur allant de 0 à 11111111.
TIMESTAMP combine date et heure avec une précision du millième de seconde. On peut préciser le fuseau horaire avec l'option TIME ZONE. La norme SQL 2 précise que l'étendue de ce type de données doit aller du premier janvier de l'an 1 à zéro heure jusqu'au 31 décembre de l'an 9999 à 23h59m59s999.
Exemple 38
TIMESTAMP
L'option TIME ZONE permet de définir le décalage horaire par rapport à l'heure universelle (UTC) :
Exemple 39
TIMESTAMP WITH TIME ZONE
Par exemple en été en France, ou le décalage horaire est de +2 heures par rapport au temps universel, nous pourrions stocker des données sous la forme :
Exemple 40
CAST('1999-11-20 16:28:33-02:00' AS TIMESTAMP WITH TIME ZONE)
DATE permet de stoker des dates dans l'étendue premier janvier de l'an 1 jusqu'au 31 décembre de l'an 9999.
Exemple 41
DATE
TIME permet de stocker des heures dans l'étendue de 00:00:00.000 h à 23:59:59.999 h. Comme dans le cas du TIMESTAMP, l'option TIME ZONE permet de définir le décalage horaire par rapport à l'heure universelle (UTC) :
Exemple 42
TIME WITH TIME ZONE
NOTA : pour les types DATE, TIME et TIMESTAMP, le format de saisie est calé sur la norme ISO qui précise que les données temporelles doivent être écrites de la manière suivante : AAAA-MM-JJ et les heures : HH:MM:ss.xxx
ATTENTION : d'après la norme, on peut préciser le nombre de chiffres significatifs après la seconde des types TIME et TIMESTAMP. Ainsi, la déclaration d'un TIMESTAMP(6) permettrait de stocker des informations horaires avec une précision du milliardième de seconde. Compte tenu de la difficulté d'implémentation, de stockage et de calculs de telles données, ce dispositif est rarement implémenté sur les SGBDR des différents éditeurs.
INTERVAL est un type de données permettant de stocker des durées. Le stockage peut se faire sur une unité de temps ou sur une étendue d'unité continuelle de temps à l'aide des mots clefs YEAR, MONTH, DAY, HOUR, MINUTE, SECOND.
La syntaxe de déclaration d'un tel type est la suivante :
INTERVAL debut [TO fin]
|
debut, fin :: YEAR, MONTH,DAY,HOUR,MINUTE,SECOND
|
Avec les règles suivantes :
1) fin doit être plus précis que debut
2) debut peut dépasser la capacité maximale ordinaire habituellement attribuée à la mesure temporelle
|
Exemple 43
INTERVAL MINUTE
INTERVAL YEAR TO DAY
INTERVAL HOUR TO SECOND
Si vous désirez mesurer des durées en heures, vous pouvez par exemple stocker 178 heures 23 minutes et 16 secondes sous la forme suivante :
Exemple 44
CAST('178:23:16' AS INTERVAL HOUR TO SECOND)
NOTA : Ce type INTERVAL est maheureusement rarement implémenté. La plupart du temps les éditeurs recommandent d'utilier un FLOAT pour stocker des durées en fraction de jours.
REMARQUE : on peut être étonné de l'absence de type "booléen" dans la norme. Il est facile d'y palier en utilisant un type BIT(1). En l'absence du type BIT, on peut utiliser un SMALLINT associé à une règle de validation ou bien un littéral de type CHAR(1) avec une plage de valeur.
ATTENTION : lorsqu'une ligne est ajoutée à une table, les colonnes non renseignées possèdent le marqueur NULL.
5.1.2. Typage rapide avec des préfixes
Comment préciser le type cible d'une chaîne de caractère ? Là encore la norme vient à notre rescousse. En principe une chaîne de caractères est par défaut du type CHAR ou VARCHAR. Pour la convertir en NATIONAL (CHAR ou VARCHAR) il suffit de la préfixer avec la lettre d'attribut N. De même pour une chaîne représentant une valeur binaire, il faut utiliser la lettre B et pour une chaîne de valeur hexadécimale la lettre X. Il n'y a pas de lettres préfixes pour les autres types. Ainsi pour les chaînes de caractères CHAR / VARCHAR il suffit d'utiliser l'apostrophe comme délimiteur de la chaîne en dédoublant toute apostrophe se trouvant au sein de la chaîne. Enfin pour les données temporelles on peut les préfixer du nom de type.
Exemple 45
| 'toto' |
chaîne CHAR ou VARCHAR |
| N'toto' |
chaîne NATIONAL CHAR ou NATIONAL VARCHAR |
| X'AF16' |
chaîne hexadécimale |
| B'010011' |
chaîne binaire |
| DATE '2002-11-18' |
date |
| TIME '11:16' |
heure |
| TIMESTAMP '2002-11-18 11:16:22 + 01:00' |
Combiné date/heure avec décalage de fuseau horaire |
| INTERVAL '11:16' HOUR TO MINUTE |
Intervalle de temps borné par heures et minutes |
5.2. Les nouveaux types SQL 3
La norme SQL 3 (1999) a rajouté 3 types fondamentaux : booléen, CLOB et BLOB.
BOOLEAN est un type de données valant vrai ou faux (ou possédant le marqueur NULL si non renseigné).
Exemple 46
BOOLEAN
NOTA : du fait de la présence du marqueur NULL, le type booléen obéit à une logique ternaire.
CHARACTER LARGE OBJECT [(n [m])] est un type litteral permettant de stocker des chaînes de caractères de grande dimension dans un jeu à deux octets par caractères (ASCII). Le paramètre n permet de préciser la longeur et le paramètre m la mesure de cette longueur parmi les lettres K, M ou G.
Exemple 47
CHARACTER LARGE OBJECT (64 K)
Est un type littéral acceptant 64 kilo binaire de caractères, soit 64 * 1024 = 65 536 caractères (donc 131 072 octets).
Le synonyme CLOB peut être utilisé.
NATIONAL CHARACTER LARGE OBJECT [(n [m])] est une déclinaison de CHARACTER LARGE OBJECT opérant sur un jeu à quatre octets par caractères (UNICODE).
Le synonyme NCLOB peut être utilisé.
BINARY LARGE OBJECT [(n [m])] définit une chaîne de bits de grande dimension dont la longueur est fixe. Le paramètre n permet de préciser la longeur et le paramètre m la mesure de cette longueur parmi les lettres K, M ou G.
Exemple 48
BINARY LARGE OBJECT (2 G)
Est un type chaîne de bits acceptant 2 giga octets de données, soit 2 097 152 octets.
Le synonyme BLOB peut être utilisé.
La norme SQL 3 a de plus défini les types structurés ARRAY, ROW, REF ainsi que des types utilisateurs appelés UDT.
Syntaxe :
type_sql ARRAY [ dimension1 [, dimension2 ... ] ]
|
ROW ( colonne1 [, colonne2 ... ] )
|
REF ( udt ) [SCOPE nom_table [mode_reference]]
mode_reference ::
REFERENCES ARE [NOT] CHECKED
[ON DELETE { CASCADE | SET NULL | SET DEFAULT | RESTRICT | NO ACTION }]
|
Exemple 49
MA_TABLEAU INTEGER ARRAY [12, 31]
MON_ADRESSE ROW (ADRESSE1 VARCHAR(32), ADRESSE2 VARCHAR(32), ADRESSE3 VARCHAR(32),
CODE_POSTAL CHAR(5), VILLE CHAR(32))
MON_CODE_POSTAL REF(UDT_CP) SCOPE TR_CODES_POSTAUX REFERENCES ARE CHECKED ON DELETE SET NULL
Ces trois exemples montrent :
- un tableau d'entiers à deux dimensions doté de 12 lignes et 31 colonnes
- une ligne dotée de 5 éléments permettant de stocker des adresses
- une donnée référentielle basée sur un type utilisateur permettant de restreindre les valeurs aux données situées dans une autre table
Bien entendu ces types peuvent être combinés :
Exemple 50
MON_ADRESSE ROW (VARCHAR(32) ARRAY [3],
CODE_POSTAL REF(UDT_CP) SCOPE TR_CODES_POSTAUX REFERENCES ARE CHECKED ON DELETE SET NULL,
VILLE CHAR(32))
REMARQUE : il n'entre pas dans ce papier d'expliquer les UDT dont l'intérêt et la complexité mérite un papier à part entière. Néanmoins les UDT permettent de définir de nouveaux types de données, par exemples pour stocker des coordonnées planaires ou spaciales (polaire, cartèsiennes...), des adresses IP, etc...
5.3. Types communs présent dans certains SGBDR des différents éditeurs
On trouve couramment les types suivants dans certains SGBDR :
SMALLDATETIME
|
un format raccourcis pour des dates dans une plage de valeur restreintes (à éviter) |
MONEY, SMALLMONEY
|
un format spécifique aux valeurs monétaires (à éviter) |
TINYINT
|
un entier avec une plage de valeur très restreinte (par exemple 0 à 255) |
BIGINT
|
un entier avec une plage de valeur très étendue |
LONGTEXT, TEXT, NTEXT
|
autres noms des CLOB et NCLOB |
IMAGE
|
un BLOB spécialisé pour stocker des images |
LONGBLOB
|
autre nom d'un BLOB |
BFILE
|
fichier externe de BLOB (Oracle) |
RAW, LONG RAW
|
données "brutes" |
ROWVERSION, UNIQUEIDENTIFIER, ROWID
|
des identifiants spécifiques auto générés |
ENUM
|
des valeurs dans un ensemble prédéfini |
Ces types ne sont pas normatifs, il convient donc de les éviter pour des raisons de portabilité.
5.4. Définir des domaines et les utiliser
Un domaine au sens de la norme SQL est la définition d'un type associé à un certain nombre de règles de validité.
Imaginons que nous voulons modéliser le nombre de pages d'un livre. Il est à priori absurde d'accepter un nombre de pages négatif ou nul. Dans ce cas, il faudrait créer un nouveau type dont la plage des valeurs serait restreinte. D'ou l'idée de domaine qui rassemble à la fois le type et l'étendue des valeurs possible, c'est à dire le domaine des possibilités d'exploitation.
La défintion d'un domaine s'opére avec la syntaxe suivante :
CREATE DOMAIN nom_domaine
[AS] type_donnée
[DEFAULT valeur_défaut]
[contrainte_de_domaine1 [, contrainte_de_domaine2 ... ] ]
[COLLATE nom_collation]
|
contrainte_de_domaine ::
CONSTRAINT nom_contrainte CHECK (regle_validation)
|
NOTA : une règle de validation doit utiliser le mot clef VALUE pour faire référence à la donnée.
Exemple 51
CREATE DOMAIN NOMBRE_DE_PAGE
AS INTEGER
CONSTRAINT CTR_SUP_ZERO CHECK (VALUE > 0)
La clause DEFAULT d'un ordre de création de domaine peut contenir une valeur explicite, ou bien l'une des valeurs retournées par les fonctions suivantes :
CURRENT_DATE
|
date courante |
CURRENT_TIME[(p)]
|
heure courante |
CURRENT_TIMESTAMP[(p)]
|
date et heure courante |
LOCALTIME[(p)]
|
heure courante sans fuseau |
LOCALTIMESTAMP[(p)]
|
heure et date courante sans fuseau |
USER
|
utilisateur par défaut |
CURRENT_USER
|
utilisateur courant |
SESSION_USER
|
utilisateur de la session |
SYSTEM_USER
|
utilisateur système |
NULL
|
non renseigné |
Exemple 52
CREATE DOMAIN OUI_NON
AS NCHAR(3)
DEFAULT 'NON'
CONSTRAINT CTR_LISTE_VALEUR CHECK (UPPER(VALUE) IN ('OUI', 'NON'))
COLLATE UNICODE
Cet exemple créé un domaine de type 3 caractères UNICODE sur la séquence de collation UNICODE (4 octets par caractères, ordre binaire) avec la valeur par défaut 'NON' et accepte toutes les combinaisons de valeurs suivantes :
'oui', Oui', 'OUi', 'OUI', 'oUI', 'OuI', 'oUi', 'ouI', 'non', 'Non', 'nOn', 'noN', 'NOn', 'nON', 'NoN', 'NON'
Exemple 53
CREATE DOMAIN IMMATRICULATION
AS CHAR(10)
CONSTRAINT CTR_CARACTERE_1 CHECK (SUBSTRING(VALUE, 1, 1) BETWEEN '0' AND '9')
CONSTRAINT CTR_CARACTERE_2 CHECK (SUBSTRING(VALUE, 2, 1) BETWEEN '0' AND '9')
CONSTRAINT CTR_CARACTERE_3 CHECK (SUBSTRING(VALUE, 3, 1) BETWEEN '0' AND '9')
CONSTRAINT CTR_CARACTERE_4 CHECK (SUBSTRING(VALUE, 4, 1) = ' ')
CONSTRAINT CTR_CARACTERE_5 CHECK (SUBSTRING(VALUE, 5, 1) BETWEEN 'A' AND 'Z')
CONSTRAINT CTR_CARACTERE_5_BIS CHECK (SUBSTRING(VALUE, 5, 1) NOT IN ('I', 'O'))
CONSTRAINT CTR_CARACTERE_6 CHECK (SUBSTRING(VALUE, 6, 1) BETWEEN 'A' AND 'Z')
CONSTRAINT CTR_CARACTERE_6_BIS CHECK (SUBSTRING(VALUE, 6, 1) NOT IN ('I', 'O'))
CONSTRAINT CTR_CARACTERE_7 CHECK (SUBSTRING(VALUE, 7, 1) BETWEEN 'A' AND 'Z')
CONSTRAINT CTR_CARACTERE_7_BIS CHECK (SUBSTRING(VALUE, 7, 1) NOT IN ('I', 'O'))
CONSTRAINT CTR_CARACTERE_8 CHECK (SUBSTRING(VALUE, 8, 1) = ' ')
CONSTRAINT CTR_CARACTERE_9 CHECK ((SUBSTRING(VALUE, 9, 2) BETWEEN '01' AND '95' OR SUBSTRING(VALUE, 9, 2)
IN ('2A', '2B')) AND NOT (SUBSTRING(VALUE, 9, 2) = '20' ))
Cet exemple permet de modéliser des immatriculations au format : "NNN AAA MM" ou NNN sont des chiffres de 0 à 9, AAA des lettres majuscules de 'A' à 'Z' excepté 'I' et 'O', et un code minéralogique correspondant au numéro des départements de 01 à 95 excepté 20, mais acceptant 2A et 2B pour la Corse !
Bien entendu la norme SQL 2 prévoir la modification d'un domaine en permettant de rajouter ou retirer une clause défaut ou une contrainte :
ALTER DOMAIN nom_domaine
{ SET DEFAULT valeur_défaut
| DROP DEFAULT
| ADD contrainte_de_domaine
| DROP CONSTRAINT nom_contrainte }
Exemple 54
ALTER DOMAIN IMMATRICULATION
DROP CONSTRAINT CTR_CARACTERE_1
ALTER DOMAIN IMMATRICULATION
DROP CONSTRAINT CTR_CARACTERE_2
ALTER DOMAIN IMMATRICULATION
DROP CONSTRAINT CTR_CARACTERE_3
ALTER DOMAIN
ADD CONSTRAINT CTR_CARACTERE_1_A_3 CHECK (CAST(SUBSTRING(VALUE, 1, 3) AS INTEGER) BETWEEN 1 AND 999)
NOTA : il n'est pas possible de changer le type de données de la définition d'un domaine.
La suppression d'un domaine s'effectue avec un ordre SQL DROP :
DROP DOMAIN nom_domaine [ CASCADE | RESTRICT ]
Lorsque l'on précise CASCADE, le domaine pourra être supprimé sans que les colonnes afférentes à ce domaine en soit affectées. Dans ce cas, le type du domaine comme les contraintes y afférent sont transférés à toutes les colonnes utilisant ce domaine. Si la clause RESTRICT est utilisée alors une erreur sera levée si des colonnes de table dans la base utilise le domaine à supprimer. Sinon, la suppression sera effective.
REMARQUE : certains SGBDR n'utilise pas des domaines mais proposent des mécanismes similaires.
En particulier c'est le cas de MS SQL Server qui utilise une combinaison de règles et de type utilisateur.
Exemple 55
CREATE RULE RLE_POURCENT
AS
@VALUE BETWEEN 0.0 AND 100.0
sp_addtype TYP_POURCENT, 'FLOAT', 'NOT NULL'
sp_bindrule 'RLE_POURCENT', 'TYP_POURCENT'
Création de l'équivalent d'un domaine dans MS SQL Server pour représenter un pourcentage.
NOTA : un domaine est bien entendu utilisable à la place d'un type SQL pour définir une colonne de table.
|