Filtrage lexical en RAP en deux passes
Ce système se décompose en deux modules principaux :
- LE MODULE DE PRE-TRAITEMENT ACOUSTIQUE basé sur une méthode de segmentation statistique du signal développée par
R. Andre-Obrecht.
- LE MODULE DE RECONNAISSANCE EN DEUX PASSES qui repose sur la description de chaque entrée
du lexique en deux représentations :
- la représentation en classes majeures : elles sont utilisées pour modéliser le lexique en une réunion
de sous-dictionnaires.
La première passe du module de reconnaissance sélectionnera un seul sous-dictionnaire.
- la représentation en pseudo-diphones , unités plus fines que les classes majeures qui seront les unités de base d'un MMC temporaire
construit automatiquement, modélisant le sous-dictionnaire. La deuxième passe sélectionnera dans ce MMC le meilleur chemin qui référera
le meilleur mot candidat.
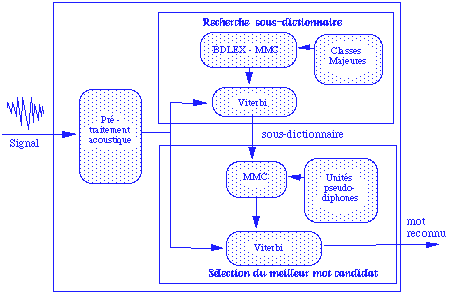
Schéma général du système de reconnaissance
PRESENTATION DU SYSTEME DE RECONNAISSANCE :
- Modélisation du vocabulaire :
- Un Modele de Markov Caché principal, dont les unites de base sont les Classes Majeures, est defini a partir des mots
du lexique. La création de ce MMC ne s'effectue qu'une seule fois à l'initialisation du système. Ses mises à jours doivent s'effectuer en
parallèle avec celles du lexique BDLEX.
- Reconnaissance d'un mot inconnu :
- En procedant a l'alignement des observations par l'algorithme de Viterbi sur le MMC principal, on obtient
un meilleur chemin désignant un sous-dictionnaire.
- Les mots de ce sous-dictionnaire sont modelises en un MMC temporaire , dont les unités de base sont des
pseudo-diphones.
Un nouvel alignement des observations sur ce MMC donne le meilleur chemin correspondant au mot reconnu.
Pour plus de détails, on peut se référer au Chapitre III_A du document de thèse
Avril 1996.