SQL12. A quoi ça sert ?
A en croire certains intégristes (de MySQL pour
ne pas le citer) certains des éléments des bases de données
s'avéreraient parfaitement inutile. Préambule 1. A quoi servent les transactions ? 1.1. Transaction ou code client ? 1.2. Pourquoi pas des verrous ? 1.3. Comment piloter une transaction ? 1.4. Anomalies du fait de processus concurrents 1.5. Niveau d'isolation des transactions et anomalies transactionnelles 1.6. Conclusion 1.7. Où placer les transactions ? Sur le serveur ou sur le client ? 1.8. Qu'est ce que le "verrou mortel" ? 1.9. Mais alors ? Les transactions peuvent induire un blocage ??? 2. A quoi sert L'intégrité référentielle ? 2.1. Le mécanisme 2.2. L'intégrité référentielle, fondement des SGBDR... 2.3. Peut on se passer de l'intégrité référentielle ? 3. A quoi servent les déclencheurs (Triggers) ? 3.1. C'est quoi un trigger ? 3.2. Comment ça marche ? 3.3. A quoi ça sert ? 3.4. Peut-on s'en passer ? Faire autrement ? 4. A quoi servent les sous requêtes ? 4.1. C'est quoi une sous requête ? 4.2. Peut on s'en passer, faire autrement ? 5. A quoi servent les opérations ensemblistes ? 5.1. Ca ressemble à quoi ? 5.2. Est-il possible de s'en passer ? 6. A quoi servent les procédure stockées ? 7. A quoi servent les UDF ? 7.1. Quel intérêt ? 7.2. Un exemple ? 7.3. Peut-on s'en passer ? Faire autrement ?? 8. La journalisation 8.1. A quoi ça sert ? 8.2. Comment ça marche ? 9. Quelques remarques de... PréambuleUn gestionnaire de bases de données est un
logiciel capable de traiter des données structurées dans un contexte de
concurrence. C'est ainsi que plusieurs utilisateurs doivent pouvoir
accéder aux données et les modifier sans qu'il en résulte de dégâts
causés par des manipulations qui s'enchevêtrent. C'est ce que l'on
appelle le respect de l'intégrité des données... Nous allons voir les techniques que propose la norme SQL afin de garantir la bonne marche d'une base de données relationnelle. 1. A quoi servent les transactions ?Les transactions sont la clef même de toute
problématique d'accès concurrent. Même lors de simples lectures, le
SGBDR doit pouvoir assurer le respect de la cohérence des données dans
le temps. Bien entendu, lors de modifications de données, les
transactions servent à garantir que tout soit mené à bien sans qu'il en
résulte la moindre anomalie, ou à l'inverse, si une anomalie se produit,
de revenir à l'état antérieur, c'est à dire l'état qu'avaient les
données avant le démarrage de la transaction. La norme à défini deux éléments pour piloter les transactions :
La transaction permet de définir l'atomicité du traitement considéré. Un traitement atomique est un traitement qui est considéré comme fonctionnant en tout ou rien : soit toutes les opérations relatives aux traitements sont exécutées, soit elles sont toutes annulées et les données reviennent dans l'état antérieur qui précédait juste la transaction. La notion d'"atomique" vient du grec. L'atome pour les grec était la plus petite partie insécable de la matière. Autrement dit on ne pouvait pas couper plus finement la matière. Un code atomique est donc un programme qui s'exécute sans jamais être interrompu par un processus concourrant. Il a donc l'exclusivité des ressources pendant tout le temps de son exécution. Pour mieux comprendre le problème, prenons un exemple simple. Soit les tables :
Un client dont la clef est 77, veut prendre 5 places sur le vol 2. Deux requêtes sont à exécuter. La première va décompter le nombre de place de la table T_VOL et la seconde va insérer une ligne dans la table T_CLIENT_VOL pour ce nouveau client. A priori les requêtes sont très simple d'expression :
Apparemment tout marche bien... Sauf que
nous n'avons pas pensé au contexte de concurrence. Et si un autre
utilisateur fait un traitement similaire au même moment ? Que se passe
t-il ? Bien entendu je vois d'avance des voix s'élevant en disant que
c'est quasiment impossible, parce que cela se joue à quelques millièmes
de seconde... Mais en informatique, surtout aujourd'hui 1/1000e de
seconde c'est 200 instructions machine !!! Donc, concurrence il peut y
avoir, et il y aura certainement un jour ou l'autre... Une première idée est de tester si réellement il y a bien au moins 5 places libres... D'où le code suivant :
Néanmoins, à tout moment juste après le begin ou l'update les données peuvent changer et conduire à la catastrophe... Étudions le cas ou deux processus concurrent effectue des requêtes similaires et ajoutons le client 88 qui va demander 3 places sur le vol 2...
Voici le contenu des tables pour les temps T1 à T6 pour le vol 2 et les clients 77 et 88 :
Nous avons généré des places négatives et surbooké l'avion. 1.1. Transaction ou code client ?Est t-il possible de contourner le
problème par un code plutôt que par une transaction ? Hélas non, car à
chaque fois que nous testerons nous pouvons avoir un autre ordre SQL qui
s'intercale. Par exemple l'idée de renverser la vapeur si nous avons
généré des places négatives est bien tentante...
Hélas executée dans un contexte de concurence elle devient tout aussi inacceptable ! Voici le contenu des tables pour les temps T1 à T10 pour le vol 2 et les clients 77 et 88 :
Nous n'avons toujours pas résolu notre
problème. Car aucun client n'a été servit ! C'est encore pire, vous
allez entraîner la faillite de votre compagnie en continuant comme ça ! En fait, seul une transaction peut permettre de nous sauver de l'embarras. 1.2. Pourquoi pas des verrous ?Alors certains dirons, "mais il suffit de poser un verrou sur la table ... ou la ligne... ". D'accord, sauf que cela n'existe pas en SQL et que les verrous sont des mécanismes internes en principe inaccessibles. Le verrou est en fait l'un des moyens d'assurer la concurrence entre les utilisateurs mais ses effets, dans le cadre d'une utilisation directe peuvent être plus pervers que l'utilisation des transactions. En effet qui n'a jamais entendu parlé du "verrou mortel, "dealock" en anglais, aussi apellé étreinte fatale. L'utilisation de verrous, même si elle est
permise par le SGBDR est à proscrire totalement sans une maîtrise
parfaite des phénomènes de concurrence qui suppose d'avoir fait un
diagramne du parallélisme des tâches afin de débusquer les points de
concurrence sujet à blocage. Cela c'était l'informatique de grand papa à
l'aide de fichiers que l'on ouvrait en mode exclusif pour effectuer ses
modifications en COBOL... Encore faut-il savoir quels types de verrous sont disponibles sur le SGBDR : optimistes, pessimistes, exclusifs, partagés, de table, de page, de ligne de colonne ?????????? En revanche, voici comment ce problème est résolu par une gestion de transaction :
Étudions les effets de ce code en concurrence :
Comme nous allons le voir, tout à bien fonctionné :
T6 n'est pas exécuté comme T12,
l'utilisateur 1 voit sa transaction validée et le 2 la voit annulée.
C'est à dire que le contenu des tables revient aux même données qu'il y
avait au début de la transaction T2. 1.3. Comment piloter une transaction ?Nous venons de voir comment démarrer une
transaction et comment la valider ou l'annuler. Il faut toujours qu'une
transaction possède une ordre COMMIT ou ROLLBACK, sans quoi elle perdure jusqu'à plus soif... en principe jusqu'à ce que l'utilisateur se déconnecte. ATTENTION : la norme prévoit que
toute connexion à un SGBDR entame une transaction. C'est vrai sur
certains serveurs, faux sur d'autres comme SQL Server qui travaillent en
AUTOCOMMIT, c'est à dire que chaque ordre SQL constitue une transaction
en soi, immédiatement auto validée ou auto annulée. Dans ce cas il faut
obligatoirement commencer une transaction par l'ordre SQL BEGIN
TRANSACTION.
Parlons maintenant du niveau d'isolation,
la fameuse "perméabilité" dont je vous ais parlé au début. C'est un
concept un peu difficile à retenir car il doit s'apprécier uniquement en
pensant à deux transactions s'exécutant en concurrence. N'oublions pas
que le SGBDR compte tenu des volumes de données à traiter doit pouvoir
servir tout un chacun avec la même chance d'accès au serveur et donc les
processus sont parallélisés. Nous pourrions comparer l'isolation d'une transaction à la perméabilité d'un tuyau. Par exemple deux robinets (l'un de vin rouge, l'autre de blanc) situés côte à côte peuvent être dotés en sortie :
Le pilotage du niveau d'isolation est assuré par l'ordre SQL :
1.4. Anomalies du fait de processus concurrentsOu les anomalies "transactionnelles"... Pour comprendre l'utilité de ces
différents niveaux, nous allons nous intéresser aux trois types
d'anomalies possibles qui peuvent survenir lors de l'exécution
concurrente d'ordres SQL.
Voici un exemple de lecture impropre :
l'utilisateur 1 ajoute 10 places et annule sa transaction, tandis que
l'utilisateur 2 veut 7 places si elles sont disponibles...
Et les données qui sont manipulées :
Le temp d'un update avorté, la transaction
2 a lu des informations qu'elle n'aurait jamais dû voir et en a tiré la
conclusion qu'elle pouvait servir les places... Conclusion surbooking ! Voici maintenant un exemple de lecture non répétable : nous allons considérer le cas ou notre opérateur désire toutes les places d'un vol si il y en à plus de 4...
Et les données qui sont manipulées :
Notre utilisateur 2 voulait au moins 4 places et en à reçu 2... Conclusion, vous avez perdu un client ! Dernier cas, la lecture fantôme :
notre utilisateur 2, désire n'importe quel vol pas cher pour emmener son
équipe de foot (soit 11 personnes) à une destination quelconque.
Et les données qui sont manipulées :
11 places ont été volatilisé du vol AF 111
et c'est comme cela qu'un certain été, des avions d'Air France volaient
à vide avec toutes les places réservées !!! [1] 1.5. Niveau d'isolation des transactions et anomalies transactionnellesC'est pour se préserver de telles anomalies que la norme SQL 2 à mis en place le niveau d'isolation des transactions. Le tableau ci dessous résume les
différents niveaux d'isolation praticables et les anomalies qu'elle
doivent impérativement éviter :
En principe, la norme fixe le niveau d'isolation par défaut du SGBDR à SERIALIZABLE ! En pratique, c'est rarement le cas... Par
exemple SQL Server de Microsoft fonctionne par défaut, au niveau
d'isolation 1 (READ COMMITED) ce qui explique sa relative grande
rapidité mais de possibles anomalies transactionnelles si l'on y prend
pas garde. Mais me direz, vous... Pourquoi accepter de descendre en dessous du niveau SERIALIZABLE ? Simplement parce que ce niveau - le plus contraignant - entraîne une pénalisation certaine du serveur en terme de performance ! Or, nous n'avons pas toujours besoin de ce niveau d'extrême isolation... La norme SQL laisse le choix de piloter les transactions comme le développeur le veut, à condition qu'il ait ce choix et qu'il en mesure toutes les conséquences... En cette matière hélas, nombre de développeurs laissent faire le server sans se poser les bonnes questions.... Il est conseillé de se situer au moins au niveau correspondant aux utilisations suivantes :
1.6. ConclusionVous avez compris que dès que des mises à
jour interviennent en concurrence il peut survenir des anomalies
transactionnelles, ce qui, dans ce cas, fait perdre à la base
l'intégrité de ses données... Il est donc impossible de se passer de la logique transactionnelle, sauf à définir un seul utilisateur à même d'effectuer toutes les mises à jour (INSERT, UPDATE, DELETE) ce qui cantonne les bases de données qui en sont dépourvues à des utilisations du genre "base de données documentaires" ou l'essentiel de l'activité du serveur constitue de la lecture de données. 1.7. Où placer les transactions ? Sur le serveur ou sur le client ?OUI, mais... on peut gérer des
transactions soit dans des procédures stockées au sein du serveur, soit
dans du code client... Qu'est ce qui est préférable ? L'idée de manipuler des transactions
depuis un code client (VB, Delphi, Java, C++...) est séduisante mais
"casse gueule" et peut entraîner le pire du pire : un blocage total du
serveur. En effet dès que l'on entame une transaction, le SGBDR pose les
verrous adéquats sur les ressources visées par la procédure. Si le
client perd la main sur son code et ne provoque jamais de COMMIT ou
ROLLBACK, les ressources ne sont pas libérées et entraînent
l'impossibilité pour les autres utilisateurs d'accèder aux données
vérouillées. C'est pourquoi une logique transactionnelle doit toujours
être exécutée au plus près du serveur et non sur le poste client, à
moins que vous ayez prévue l'artillerie lourde : poste sur onduleur on
line ou réseau électrique sur alimentation secourue, OS hyper stable,
anti virus, etc... De plus, il convient que la procédure ne soit jamais en attente d'une manipulation de l'utilisateur (comme une demande de saisie ou de confirmation) car toute attente bloque les ressources un certain temps et met en attente d'autres utilisateurs. C'est alors le château de carte, chaque utilisateur attend qu'un autre libère les ressources et cela peut entraîner le blocage total du SGBDR, par exemple un verrou mortel... C'est pourquoi on veillera à placer les
transactions, soit dans une procédure stockée (l'idéal en terme de
sécurité et d'intégrité) soit dans des objets métiers appelés par une
serveur d'application ou d'objet aussi bien sécurisé que le serveur
SGBDR et dans un réseau connectiquement proche. 1.8. Qu'est ce que le "verrou mortel" ?Ce phénomène se produit lorsque deux (ou
plus) utilisateurs veulent accèder aux mêmes ressources mais dans une
séquence de temps inverse. Nous avons dit que le SGBDR posait des
verrous adéquats sur les ressources par rapport aux objets concernés par
les transactions. Le type de verrou dépend d'ailleurs de l'ordre SQL
exécuté et du niveau d'isolation demandé. Certains traitements nécessite
la pose simultané de plusieurs verrous sur des tables différentes. Le
verrou mortel s'appelle dans la littérature informatique "dead lock" en
anglais, et encore étreinte fatale ou interblocage en français. Regardons ce qui se passe dans deux transactions sujettes à un tel verrou mortel... L'utilisateur 1 veut prendre 3 places
d'avion sur le vol AF 714, tandis que l'utilisateur 2, qui vient d'être
hospitalisé veut restituer 5 places sur ce même vol...
Voyons ce qui se passe dans le détail, en matière de verrous, lors du déroulement concurrent de ces deux transactions :
A ce stade les deux transactions sont en
attente de libération de ressources. Aucune ne va se terminer car
chacune d'elle attend que l'autre libère la ressource dont elle à
besoin. C'est l'interblocage, l'étreinte fatale, le verrrou mortel ou
deadlock. 1.9. Mais alors ? Les transactions peuvent induire un blocage ???Oui et non. Cela dépend du SGBDR et du
niveau d'isolation. Certains SGBDR comme Oracle ou InterBase sont dotés
d'un algorithme qui empêche tout interblocage. Cet algorithme peut être
un "time out", qui tue momentanément un processus au hasard lorsque
plusieurs processus sont bloqués. Bien entendu, le niveau d'isolation
joue aussi beaucoup sur ce phénomène. Un niveau sérializable indique au
serveur de placer les transactions en série (ou de faire comme ci). Cela
peut garantir qu'il n'y ait pas d'interblocage, mais pénalise le
serveur puisqu'il devient impossible de paralléliser les processus. Une
autre astuce est de toujours manipuler les tables, dans vos procédures
stockées, comme dans votre code client, dans le même ordre (par exemple
l'ordre alphabétique du nom de table)... Notez que certains GSBDR, comme MS SQL Server sont assez sujet à l'interblocage et le seul remède est en général de "tuer" un utilisateur (enfin, sa connexion !). 2. A quoi sert L'intégrité référentielle ?L'intégrité référentielle sert à empêcher
qu'une ligne d'une table qui référence une ligne d'une autre table voit
le lien logique entre les deux lignes brisée. Que serait une facture si
le client venait à être effacé de la table des clients ? 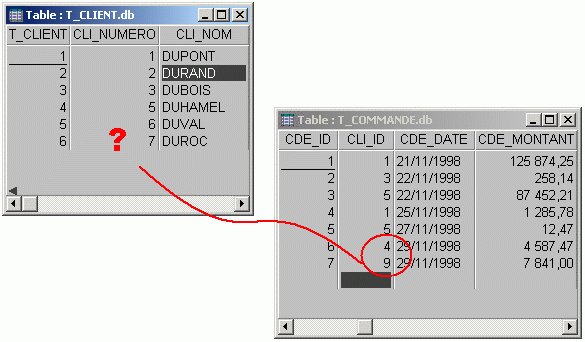 Ici, les commandes 6 et 7 font références aux client 4 et 9 qui n'existent pas dans la table T_CLIENT... 2.1. Le mécanismeLe mécanisme d'intégrité référentielle doit permettre d'assurer :
La norme SQL 2 à prévu les modes de gestion des intégrités référentielles suivants :
Qui signifie que :
Bien entendu on peut parfaitement supprimer
un client qui ne possède pas de commande ou modifier la valeur de sa
clef même lorsque le mode NO ACTION est actif. Dans tous les cas, le mode NO ACTION est à
préférer. En effet le mode CASCADE peut entraîner une avalanche de
suppressions ou de mise à jour du plus mauvais effet sur les
performances du SGBDR ! Ce mécanisme simple et robuste est complété
par d'autres possibilités qu'offre la norme SQL et qui sont : SET
DEFAULT et SET NULL.
Ces deux nouvelles règles proposent une alternative afin de gérer de manière intelligente une pseudo cascade... Quel intérêt me direz vous d'avoir des
commandes dont la référence du client est NULL ou bien 0 (un client
générique dont l'existence physique est fausse, par exemple moi même...)
? L'intérêt est simple : pouvoir faire le ménage dans les tables de manière ultérieure... Par exemple on pourra prévoir de supprimer toutes les commandes dont la référence client est NULL ou 0 la nuit, lorsque le traffic du serveur est très faible dans un batch planifié déclenché automatiquement. Bien entendu, dans ce cas il faut faire attention à ne pas comptabiliser dans les requêtes les lignes dont la référence du client est NULL ou 0. Ainsi un cumul du montant des commandes pour connaître le chiffre d'affaire généré mensuellement ne doit pas prendre en compte les lignes avec une référence de client 0 ou NULL... Tous les SGBDR ne sont pas aussi performant
que la norme l'impose en matière de gestion de l'intégrité
référentielle. En effet, certains comme ORACLE ou InterBase on
implémenté la plupart de ces règles de gestion. D'autres comme MS SQL
Server ne proposent que le NO ACTION. Dans ce dernier cas, l'utilisation
de triggers permet de simuler les autres règles. 2.2. L'intégrité référentielle, fondement des SGBDR...La gestion de l'intégrité référentielle
est de loin le point le plus important pour décider si un SGBD est
relationnel ou non. Dépourvu de ce mécanisme il agit comme au bon vieux
temps des fichiers COBOL. Muni de ce mécanisme il agit en responsable de
l'intégrité des données. Autrement dit un SGBD qui n'est pas doté
d'une mécanisme de gestion des intégrités référentielles ne mérite tout
simplement pas le nom de système de gestion de bases de données
"relationnelles". C'est malheureusement le cas de MySQL, qui représente une régression certaine par rapport à des systèmes de fichiers plats comme Paradox qui la possède ! 2.3. Peut on se passer de l'intégrité référentielle ?Dans la réalité c'est impossible !
La tentation de ne pas utiliser l'intégrité référentielle (ou d'avoir un
SGBD qui ne le supporte pas) et faire cela dans du code client est
séduisante... Mais casse gueule : l'idée phalacieuse qui consiste à
dire, je supprime d'abord les factures ensuite les clients, est
inacceptable si elle n'est pas conduite dans une transaction. En effet
rien n'empêche le code client de s'arrêter (panne disque, coupure de
courant, réseau HS, pause café...) entre les deux requêtes ce qui
supprime les commandes sans avoir pu supprimer le client... Mais, lisez la suite, car on peut
effectivement se passer de l'intégrité référentielle à condition que la
base de données supporte les triggers...
3. A quoi servent les déclencheurs (Triggers) ?S'il avait 2 choses à retenir pour
constituer un SGBDR au sens relationnel du terme, se serait les
transactions et les triggers. Avec ces deux outils, on peut aisément
créer tous les mécanismes d'intégrité référentielle que l'on souhaite et
assurer une parfaite intégrité des données. C'est d'ailleurs pour cela
que la norme SQL 3 a imposé l'utilisation des triggers. 3.1. C'est quoi un trigger ?Le terme français est "déclencheur". Un
trigger est donc un élément de code qui se déclenche sur un événement
précis, se rapportant à un objet de la base de données. C'est exactement
le même concept que la programmation événementielle dans le cadre
d'interfaces graphiques. Je ne serais d'ailleurs pas étonné que les
OnClick et autre OnMouseDown n'aient été inspirés par la notion de
triggers des SGBDR, car il ne faut pas oublier que les SGBDR existaient
bien avant les premiers langages faisant référence à des événements
graphiques. Mais ceci n'est pas le débat. Au sens de la norme SQL 3, un trigger se
définit uniquement sur les objets de type TABLE, concerne les événements
suivants : INSERT, UPDATE, DELETE et peut être déclenché BEFORE (c'est à
dire avant survenance de l'événement) ou AFTER (c'est à dire après
survenance de l'événement). La grande différence entre le code événementiel graphique des langages comme Delphi ou Visual Basic, c'est que l'on peut placer du code, avant ou après le survenance de l'événement, alors que dans les langages graphiques, ce paramètre n'existe pas (enfin, j'allais oublier l'extraordinaire langage ObjectPal de Paradox qui proposait non seulement le pilotage avant après dans le même code, mais encore le "bouillonnement" de l'évenement, c'est à dire sa remontée depuis le plus grand conteneur jusqu'à l'objet cible ! - au cas ou vous l'aurez oublié, celui qui a créé ObjectPal à ensuite créé Delphi puis C# maintenant chez Microsoft !!!). La syntaxe normative SQL 3 d'un trigger est la suivante :
Elle est plus conséquente dans son
étendue, mais seule cette partie nous intéresse car elle en synthétise
toutes les possibilités. La chose la plus attractive dans un
trigger, sont les pseudo tables OLD et NEW qui contiennent les données
en cours d'insertion, de mise à jour ou de suppression... 3.2. Comment ça marche ?Examinons ce qui se passe dans un cas concret. Soit les tables :
Notre utilisateur veut faire passer tout
les prospects dans la table T_CLIENT avec le statut 'P'. Oui, mais, au
passage il veut leur donner une clef comptatible avec le CLI_ID et
reformater le nom en majuscule... Or un simple ordre d'insertion basique du SQL va violer la contrainte d'unicité de la clef et rejetter en bloc l'insertion...
Mais nous pouvons pallier à ce problème,
sans rien toucher de notre ordre d'insertion en ajoutant un trigger qui
va rectifier les données en cours d'insertion AVANT qu'elle ne soient
réellement déposées dans la table :
Dès lors notre insertion va bien se passer :
Pour confirmation de ce qui s'est passé, nous pouvons relire la table client :
3.3. A quoi ça sert ?Mais, me direz vous, cela nous aurions pu
le faire directement dans l'ordre d'insertion... Par exemple avec la
requête suivante :
C'est tout à fait vrai, mais si vous aviez
des données provenant de toutes autres tables, alors il aurait fallut
adpater votre code et le modifier pour chaque cas, alors que dans le cas
d'un trigger, ce code est générique quelque soit l'insertion que vous
voulez faire et d'où qu'elle provienne ! Les cas d'utilisation des triggers sont assez large :
et plus généralement le traitements d'associations provenants de modèles complexes comme
Essayez donc de modéliser une relation
dans laquelle le lien entre table mère et table fille ne doit pas
dépasser un maximum de 3 occurrences... Par exemple le prêt de livres
dans une bibliothèque municipale ? Dans un tel cas, pour empêcher une
insertion surnuméraire, il suffit de compter les lignes déjà insérées,
et dès que le nombre de ligne dépasse 3, alors l'invocation d'un ordre
ROLLBACK empêche la pseudo table NEW d'attendre la table cible. Les
données surnuméraires ne sont alors pas insérées. Voici l'exemple d'un tel trigger :
Que fait-on dans ce code ? D'abord notez
l'expression FOR EACH ROW, qui signifie que le déclencheur va s'activer
autant de fois qu'il y a de ligne dans la table NEW, en substituant la
table NEW et ses n lignes en n déclenchements d'une table NEW ne
contenant qu'une seule ligne. Ensuite notez que l'on lie la table NEW à la table des prets sur l'identifiant de l'emprunteur. Puis on compte le nombre de lignes de cette jointure et on invoque un ROLLBACK si ce comptage est égal à tois, afin de ne pas rajouter de nouvelles lignes d'emprunts. Simple non ? Et tellement élégant ! 3.4. Peut-on s'en passer ? Faire autrement ?Si l'on n'utilise pas de modéles complexes
et que l'intégrité référentielle est en place, alors il est
parfaitement possible de se passer des triggers. Mais vu leur souplesse,
la sécurité qu'ils apportent, et la concision du code qu'ils offrent,
il serait folie de s'en priver ! 4. A quoi servent les sous requêtes ?Certains commentaires d'utilisateurs
indiquent régulièrement dans leurs mails qu'il suffit de faire des
jointures pour remplacer toute sous requête. Il est bien évident que le
commité de normalisation du SQL composé de membres éminents comme Chris
DATE, ne se serait pas évertué à les faire exister au sein de la norme
si elles servait à rien ! 4.1. C'est quoi une sous requête ?Une sous requête est une requête situé à
l'intérieur d'une autre requête. La plupart du temps il s'agit d'ordres
SELECT imbriqués. Pour un cours sur le sujet, voir : les sous requêtes 4.2. Peut on s'en passer, faire autrement ?Un simple exemple, donné par Peter GULUTZAN montre qu'il est impossible de s'en passer : Soit la table :
Tentez donc de reproduire la requête si dessous et son résultat sans sous requête...
Bien entendu dans 80% des requêtes que je
voit passer devant mes yeux, il est possible de transformer la sous
requête en jointure à l'aide de contorsions assez délicates. Mais pour
20% d'entre elles il n'y a pas de solution. Tel est pas exemple le cas
des prédicats MATCH et UNIQUE. tel est aussi le cas de la plupart des
sous requêtes implantées dans la clause from et contenant un opérateur
d'agrégat statistique. Les sous requêtes facilitent la vie du
développeur, s'écrivent plus facilement que des jointures dans bien des
cas. Elles ont un revers, elle sont souvent moins performantes que des
jointures... L'idée phallacieuse qui consiste à dire
que l'on peut s'en passer si l'on dispose de tables temporaires est
fausse. En effet, entre l'instanciation d'une table temporaire et la
requête suivante, les données peuvent changer et fausser le résultat. Il
en résulterait des erreurs, à moins d'effectuer son code dans une
transaction ! En effet il ne faut pas oublier qu'une requête est une transaction implicite... C'est aussi assez difficile de traduire en
code des sous requêtes corrélées, car dans ce cas, l'exécution de la
sous requête est renouvelée pour chaque ligne de la requête
principale... Le travail devient vite complexe et le temps d'exécution
sur le poste client devient incommensurablement long ! 5. A quoi servent les opérations ensemblistes ?Les opérations ensemblistes du SQL sont les suivantes :
5.1. Ca ressemble à quoi ?Si vous vous souvenez des patates ou diagrammes de Venn, alors vous pouvez les matérialiser facilement. Dans le cas contraire, vous pouvez lire à ce sujet : Les opérateurs ensemblistes 5.2. Est-il possible de s'en passer ?Je vais vous surprendre... La réponse est indubitablement OUI ! L'intersection, comme la différence peuvent être réalisés par des constructions équivalentes à base de jointures ou de sous requêtes.
Mais qu'en est-il pour l'union ? Il est possible de la réaliser à deux conditions :
C'est assez rare qu'il y ait ces deux
éléments sans l'opérateur UNION. De plus, le coût de calcul de cet
équivalent est assez élevé du fait de la présence des fonctions de
transformation. Voici une correspondance entre une union classique de deux tables (les données sont celles du jeu suivant : Ensembles_exemples ) :
Sans ces éléments, point de salut pour faire l'union... 6. A quoi servent les procédure stockées ?Une procédure stockée, n'est ni plus ni
moins qu'un bout de code qui s'exécute directement sur le serveur. Elle
peut réaliser les mêmes traitements que vous réaliseriez par du code
client. Disons donc tout de suite que l'on peut parfaitement s'en
priver... Mais alors quel est l'intérêt d'une procédure stockée ?
Autrement dit, une procédure stockée est l'endroit idéal pour piloter les transactions. Un exemple concret... Soit une table des clients et des adresses des
clients (pour MS SQL Server). On conserve toutes les adresses des
clients afin de gérer leur obsolescense. Notez que l'on utilise un auto
incrément (IDENTITY)...
Ce que l'on désire, c'est être assuré qu'en
insérant un nouveau client, on y insère aussi l'adresse. Or nous savons
qu'il n'est pas possible d'insérer simultanément dans deux tables
différentes avec un ordre SQL basique. Ce problème peut aisément être
contourner par une procédure stockée transactionnée...
Dès lors, l'appel de cette procédure avec de bons paramètres, va ajouter les lignes dans les deux tables simultanément :
CQFD... En revanche, une procédure stockée ne doit
jamais s'occuper de faire de la lecture seule (une simple requête même
complexe suffit en général) ou de la présentation de données (votre code
client sera toujours plus apte que votre SGBDR pour tous les aspects
"cosmétiques" !). La norme SQL n'a quasiment rien défini sur le
sujet. Ou plutôt devrais je dire que la faiblesse de la norme en matière
de procédure stockée est telle qu'a part la manipulation des curseur,
chaque éditeur de SGBDR a fabriqué un langage procédural spécifique à
son serveur. Pour Oracle, ce langage c'est PL/SQL (Programming Language / SQL), pour Sybase et MS SQL Server, c'est Transact SQL, pour InterBase, c'est ISQL (Interactive SQL)... etc. 7. A quoi servent les UDF ?User Define Function / Fonctions utilisateurs Les UDF (USer Define Function ou fonction
utilisateur) sont un récent ajout de SQL puisqu'ils viennent de la
version 3 (1999) de la norme. Ce sont des fonctions que tout utilisateur
peut coder dans sa base de données et qui peuvent être appelées dans
des requêtes SQL. Ce concept existait déjà dans certains
SGBDR comme InterBase. Les fonctions de InterBase doivent être réalisées
dans un langage extérieur et sont "branchées" au serveur par exemple
par le biais de DLL sous environnement MS Windows. Dans la norme SQL 3, ces fonctions peuvent
être réalisées soit en SQL, soit dans un langage externe reconnu (Ada,
C, Fortran, Cobol, MUMPS, Pascal, PL1). En pratique cela pourra être
fait sur d'autres langages voire le langage procédural du serveur. 7.1. Quel intérêt ?L'intérêt des UDF réside dans la
possibilité d'ajout de fonctions puissantes ou non encore réalisées dans
celle fournies par l'éditeur de votre SGBDR. Autrement dit, ajouter les
manques du dialecte SQL de votre SGBDR. Il y a un autre intérêt moins évident. Si vous devez réaliser des applications multiserveurs, c'est à dire des applications susceptible de tourner sur différents SGBDR, et si les SGBDR cible implémente les UDF, alors il est possible de définir dans chaque serveur une bibliothèque d'UDF qui permettra d'uniformiser toutes les requêtes qui pourront s'adresser indifférement à l'un ou l'autre des SGBDR cible ! 7.2. Un exemple ?Pour la peine je vous en communique trois ! Le premier exemple donne la constante PI utilisable dans n'importe quelle requête :
Le second exemple montre une fonction de conversion des francs en euros :
Le troisième montre comment on peut
utiliser un langage externe pour réaliser une UDF. L'exemple de routine
externe est en C et compte les mots d'un CLOB (Character Large OBject) :
A ce stade certaines parties de la
déclaration de la fonction sont spécifiques au SGBDR, en particulier la
déclaration EXTERNAL NAME et l'appel de la fonction. Certains SGBDR comme InterBase
implémentent depuis longtemps des UDF notamment sous forme de modules
externes que l'on peut écrire dans le langage de son choix, comme C ou
Delphi, à condition que ces fonctions soient placées dans une
bibliothèque sous forme de DLL ou équivalent (dépend de l'OS). Exemple d'UDF externe pour InterBase réalisées sous Delphi :
Exemple d'UDF pour MS SQL Server 2000 :
7.3. Peut-on s'en passer ? Faire autrement ??Bien entendu... On peut réaliser quelques
unes des UDF dans des vues par exemple ou des procédures stockées. On
peut encore faire un traitement des données reçues sur le poste client.
Mais dans ce dernier cas, les performances ne sont pas très
intéressantes. Autrement dit les UDF ne sont pas absolument nécessaires, mais bien utiles ! 8. La journalisationOu comment sont réalisées les transactions par le serveur La journalisation est le mécanisme de base permettant le transactionnel et assurant l'intégrité des données de la base. 8.1. A quoi ça sert ?Cela sert à enregistrer toutes les
manipulations de données qui sont lancées par des requêtes SQL sur le
serveur, afin de les exécuter de la manière la plus intègre possible
afin que tout problème survenant lors d'une transaction n'induise pas
une "désintégration" de la base... Le journal capte toutes les demandes et assure un mécanisme de reprise automatique dans le cas d'une panne, mais aussi gère les ROLLBACK et COMMIT. Aucune base de données relationnelle gérant des transactions ne peut se passer de ce type de mécanisme. Attention : une erreur fréquente est de
croire qu'à l'aide du journal on peut suivre ce que tel ou tel
utilisateur a pu faire sur la base, ou bien quelles ont été les
modifications survenue dans telle ou telle table. La journalisation est
en principe un mécanismes strictement interne au SGBDR et donc réservé à
son seul usage. Il n'est donc pas lisible pour un utilisateur, fût-il
administrateur de la base de données ou du serveur. 8.2. Comment ça marche ?Je n'entrerais pas dans les détails de
l'implémentation de la journalisation de tel ou tel éditeur. Je vais
simplement vous expliquer comment cela marche de manière générique... Lorsqu'une requête du DML (Data Manipulation
Language) c'est à dire un ordre SELECT, INSERT, UPDATE ou DELETE, est
envoyée au serveur, le journal écrit dans son fichier les éléments
relatif à quel utilisateur se rapporte cette demande ainsi que quelques
paramètres comme la date et l'heure de la demande. Le journal inscrit la
requête telle qu'il la trouve ainsi qu'un marqueur pour signaler le
début de la transaction (n'oubliez pas que toute requête, la plus simple
soit-elle est une transaction à part entière). Ces informations pourraient se présenter comme suit :
Le SGBDR signale au client que la requête a été prise en compte et lui demande d'attendre le retour d'exécution. Nous supposons que la table T_PRIX contienne les données suivantes :
Nous allons maintenant interrompre le courant
électrique de notre serveur à tout instant pour voir comment se
comporte le SGBDR...
Le journal est relu "à l'envers" et le SGBDR
essaye de retrouver la dernière marque de transaction validée ou
rollbacké, puis reprend la lecture du journal et redémarre le travail
sur les transactions inachevées. Il interdit à tout utilisateur de lui
envoyer des requêtes tant qu'il n'a pas retrouvé son point d'équilibre
(intégrité des données)...
Le journal est relu "à l'envers" et le SGBDR
essaye de retrouver la dernière marque de transaction validée ou
rollbacké, puis reprend la lecture du journal et redémarre le travail
sur les transactions inachevées. Si les données concernées par la
modifications n'ont pas été toutes écrites, il supprime celles déjà
présentes et recommence son travail...
Le journal est relu "à l'envers" et le SGBDR
essaye de retrouver la dernière marque de transaction validée ou
rollbacké, puis reprend la lecture du journal et redémarre le travail
sur les transactions inachevées. Si les données concernées par la
modifications n'ont pas été toutes calculées et inscrite, il supprime
celles déjà présentes et recommence son travail...
Le journal est relu "à l'envers" et le SGBDR
essaye de retrouver la dernière marque de transaction validée ou
rollbacké, puis reprend la lecture du journal et redémarre le travail
sur les transactions inachevées. Si les données concernées par la
modifications n'ont pas été toutes répercutées dans la table, il
recommence à la première valeur...
Et voilà ! Rien de plus simple en
apparence... Rajoutez-y la gestion des verrous et une concurrence de
traitement... et donnez m'en des nouvelles !!! 9. Quelques remarques de...DrQ : Pour ce qui est des résultats de MySQL, ça
ne correspond pas exactement à ce que j'avais vu comme tests. MySQL
était plus rapide que PostgreSQL avec un petit nombre d'utilisateurs
(<10). Biensur pour des requêtes simples. SQLpro : Les test comparatifs disponibles jusqi'ici
était un peu ancien. La version actuelle de PostGreSQL a été nettement
améliorée question performances. Cependant, c'est sous Linux que
PostGreSQL va le plus vite car il n'a pas besoin de l'émulation CygWin. Olivier Nepomiachty : je ne connais pas PostGreSQL. la migration est elle facile ? Faut-il réécrire le code SQL ? La migration des tables se fait-elle sans soucis ? SQLpro : PostGreSQL est assez facile à aborder si
l'on connait SQL et les bases de données. L'excellent bouquin de Campus
Press, peut servir de base à un bon apprentissage. De plus le langage
procédural de PostGreSQL (PG/SQL) est très priche du Pascal donc de
Delphi PostGreSQL est assez normatif comme MySQL, à mon avis une majorité de requêtes ne devraient pas avoir besoin d'être ré écrites. Le reste devrait subir de très légères modifications. A quelques exceptions près comme le type array qui n'existe pas sous PostGreSQL, il doit être possible de passer de l'un à l'autre. Le mieux étant de disposer d'un User Case comme Power Designor ou autre afin d'effectuer un reverse engineering pour reconstruire une base PostGreSQL à partir d'une base MySQL. Hachesse : Il t'as fait quoi MySQL pour que tu lui en veuille a ce point? Il t'as mourdu? SQLpro : Non, et puis de toute façon je suis vacciné
;-) !!! Simplement je regrette que des produits tout aussi souple et
plus contraints que MySQL aient quasiment disparus. Je ne citerais que
Paradox dont le format, malgré qu'il soit un SGBDR "fichier" comprenanit
l'intégrité référentielle et un ersatz de transactionnel (rollback
limité à 255 lignes, tables contenant les valeurs avant modification ou
suppression). Mais pour moi, un SGBDR doit au moins possèder l'intégrité référentielle de base, et si l'on veut monter en charge, le transactionnel. RDM : quelques Remarques:
SQLpro : Il n'est pas évident de dire qu'une sous
requête va être plus lente qu'une jointure. Si la jointure est
"naturelle", alors c'est probable, dans tous les autres cas, le
phénomène à bien des chances d'être insensible du fait de l'optimiseur.
Mais il est vrai qu'une jointure est plus propre qu'une requête. La
transformation n'est pas toujours possible hélas ! A mon sens, il ne faut pas "mettre un maximum de chose" côté serveur... Mais le strict nécessaire à mon avis réside dans le respect de l'intégrité des données. Un trigger permettant de faire du formatage de données ne présente pas d'intérêt. En revanche s'il étend l'intégrité relationnelle il est indispensable. Il en est de même des transactions et des procédures stockées. La tendance à tout mettre du côté serveur n'est pas la bonne. D'un autre côté, le client léger n'a pas de rélles possibilités pour traiter les données alors entre l'ajout d'un serveur d'objet (donc une machine de plus) ou la réalisation systématique des traitements en procédures stockées c'est une question de stratégie et de coût qui doit être évaluée pour chaque développement. Attention cependant aux effets de mode... Les SGBDR existent tels quels depuis maintenant 20 ans... et sont assez performants. L'archictecture 3 tiers depuis quelques années. Elle commence a devenir mature avec les composants CORBA, la technologie MIDAS et les nouveaux objet COM dérivés de l'architecture .net de MS. En ce qui concerne le C/S de 3eme génération, je dirais... prudence (qui, comme chacun le sait, est mère de sûreté) même si certaines technologies comme XML et en particulier SOAP et les web services, présentent à priori des innovations intelligentes. Mais tout le monde ne développe pas pour le web ! Henry Cesbron Lavau : A propos du paragraphe 1.7 : [...] L'idée de manipuler des transactions depuis un code client (VB, Delphi, Java, C++...) Pourquoi, depuis quand c'est le langage qui transacte ? c'est une affaire de composants, pas de langage. SQLpro : Tu as entièrement raison, mais j'ai voulu
faire simple en confondant l'envoi de l'ordre de pilotage de la
transaction et la transaction elle-même. Si c'est bien le SGBDR qui
transactionne, encore faut-il lui onner les ordres BEGIN, COMMIT /
ROLLBACK [TRANSACTION] depuis un code quelconque, qui peut être le code
client. Or le client peut parfaitement décider d'aller boire son café
entre le BEGIN et le COMMIT, ou pire interrompre son PC !
|