Marie Tahon
Research
Projects
Students
- Manon Macary: PhD Computer Science Allo-Media/LIUM (may 2018 - ). Analyse de données massives en temps réel pour l’extraction d’informations sémantiques et émotionnelles de la parole.
- Apolline Marin: M2 TAL Intership LPP, Paris (feb. - jul. 2019). Annotation de parole expressive, apprentissage actif et évaluation par la synthèse.
- Félix Michaud: M1 Acoustic Internship LIUM, Le Mans (feb. - jun. 2019). Segmentation et débruitage de cris d’oiseaux à l’aide de réseaux de neurones.
- Thomas Granjon: M2 Computer Science Internship LIUM, Le Mans (jan. - jul. 2019). Comparaison et évaluation de vocodeurs pour la synthèse neuronale.
- Alexandre Tabot: M2 Computer Science Intership LIUM, Le Mans (jan. - aug. 2019). Catégorisation automatique de personnages et évaluation en contexte pour la synthèse.
- Frédéric Le Bellour: M2 Computer Science Intership IRISA, Lannion (oct. 2017 - aug. 2018). (Semi-) Automated annotation of expressivity and emotion in speech
Research Projects
- Segmentation and identification of expressive multi-speaker speech (RFI SIMPÆX 2018-2020)
The SIMPÆX project aims at the automatic segmentation and identification of expressive styles and speakers in a speech corpus. Indeed the extraction of features concerning the speaker, his emotional state and the social context, offers very relevant clues for various applications such as audio indexing, automatic speech recognition, speech synthesis or human-machine interactions.
- Marie Tahon and Damien Lolive (2018). Discourse phrases classification: direct vs. narrative audio speech. In Proc. of Speech Prosody, Poznań, Poland. hal
- Pronunciation adaptation for expressive speech synthesis (ANR SynPaFlex 2016-2019)
The main idea of this research subject is to model pronunciation variants for expressive text-to-speech synthesis. Expressive variants are either linked to regional pronunciation, the type of discours (narrative or direct speech), emotion, or speaker pronunciation. These variants can be included at a symbolic level to the phonemic chain or at an acoustic level. Evaluation of pronunciation is also investigated. This work is done under the framework of the French ANR project SynPaFlex (site).
- M. Tahon, G. Lecorvé and D. Lolive (2018). Can we Generate Emotional Pronunciations for Expressive Speech Synthesis? IEEE Transactions on Affective Computing. doi, hal
- A. Sini, D. Lolive, G. Vidal, M. Tahon and É. Delais-Roussarie (2018). SynPaFlex-Corpus: An Expressive French Audiobooks Corpus Dedicated to Expressive Speech Synthesis, In Proc. of LREC, Miyazaki, Japan. hal
- M. Tahon, G. Lecorvé, D. Lolive, R. Qader (2017). Perception of expressivity in TTS: linguistics, phonetics or prosody?, In Proc. of the International Conference on Statistical Language and Speech Processing (SLSP), Le Mans, France. hal
- M. Tahon, R. Qader, G. Lecorvé and D. Lolive (2016). Improving TTS with corpus-specific pronunciation adaptation, In Proceedings of Interspeech, San Fransisco, USA. hal
- Guadeloupeans folk songs analysis (collaboration 2014-)
This work has been realized under the framework of a collaboration with a vocalist and musicologist, Pierre-Eugène Sitchet (alias Gino Siston). This project aims at understanding the structure of Gwoka folk songs, and also the vocal characteristics of the performers. These elements will be used for a study on endoculturation in the Gwoka in Pierre-Eugène's PhD. This collaboration is also a musical study, singers voices are analyzed as musical instruments during the performance. A comparison between hand-transcripted score and signal processing visualization has been realized on one song.
An example of a Gwoka performance by the famous Hilaire Geoffroy here
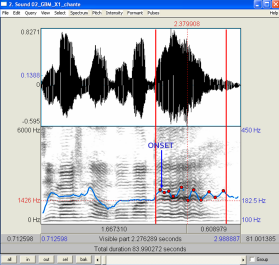
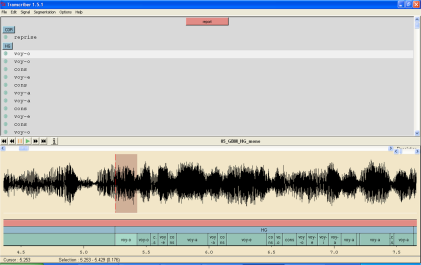
- M. Tahon, P.-E. Sitchet (2017). The transmission of voicing in traditional Gwoka: Between identity and memory. Journal of Interdisciplinary Voice Studies. Issue 2.2, pp. 157–175. doi, hal
- M. Tahon, P.-E. Sitchet (2016). From Transcription to Signal representation : Pitch, Rhythm and Performance. International Conference on Technologies for Music Notation and Representation (TENOR), Cambridge, U.K., May. doi
- M. Tahon, P.-E. Sitchet (2016). La nasalité dans le répertoire Gwoka de la Guadeloupe. Congrès Français d’Acoustique (CFA), Le Mans, France, 11-15 april. doi, presentation
- P.-E. Sitchet, M. Tahon (2016). Le voisement dans le Gwoka: entre le parlé et le chanté. Journées d'Informatique Musicale (JIM), Albi, France, 31 march-2 april. PDF.
- Emotion and social cues automatic recognition from speech (BPI ROMEO2 2013-2016)
Social cues rely on verbal and para-verbal features which occur in the course of speech. Paralinguistic speech processing aims at recognizing emotions, stress, affect bursts such as laughs and other speaker characteristics (gender, age, identity, ...). To do so, dfferent machine learning techniques were investigated: feature selection, classification, etc. The issue of which acoustic features are best for a given task (here emotion and laugh) recognition is a real actual challenge. An acoustic feature set should generalize enough for being useful in different real-life situations (type of speakers, recording conditions, type of ellicited emotions, etc...). Different feature selection methods have been tested in real-life cross-corpus conditions. The best features found in this study are robust to noisy environements, and the set is quite a small one in order to avoir over-fitting.
- Marie Tahon, Laurence Devillers (2016). Towards a small set of robust acoustic features for emotion recognition: challenges. IEEE Transactions on Speech, Audio and Language Processing, volume 54, Issue 1, pp. 16-48. doi, hal
- Marie Tahon, Mohamed A. Sehili, A. Delaborde and L. Devillers (2015). Cross-corpus experiments on laughter and emotion detection in HRI with elderly people. International Conference on Social Robotics, Paris, France, 27-30 octobre. doi
- Amit K. Pandey, R. Gelin, R. Alami, R. Viry, A. Buendia, R. Meertens, M. Chetouani, L. Devillers, M. Tahon, D. Filliat, Y. Grenier, M. Maazaoui, A. Kheddar, F. Lerasle, L. Duval (2014). Romeo2 project: : Humanoid Robot Assistant and Companion for Everyday Life: I. Situation Assessment for Social Intelligence. Artificial Intelligent and Cognition (AIC), Turin, Italie. hal
- Marie Tahon, Eric Bavu, Manuel Melon, Alexandre Garcia (2014). Attack transient exploration on sopranino recorder with Near-Field Acoustic Holography method, ISMA, Le Mans. doi
- Real-life Human-robot interaction corpus collection (FUI ROMEO 2009-2012)
In the course of speech signal processing, the data is fundamental. It is very enrichful to collect your own corpora. Many expressive corpora were collected with the LIMSI Affective and Social dimensions of spoken interactions team. Among the different corpus collected at LIMSI between 2009 and 2014, we can cite: JEMO (prototypical, more than 80 speakers, young adults), ROMEO2 (spontaneous, 27 speakers, elderly people), ARMEN (spontaneous, 52 speakers from 16 to 91 years old), IDV-HH (spontaneous, 28 visually impaired speakers), IDV-HR (spontaneous, 26 visually impaired speakers), NAO-HR (spontaneous, 12 children), etc...



- M. Tahon, G. Degottex and L. Devillers (2012). Usual voice quality features and glottal features for emotionnal valence detection. In proc. of Speech Prosody, Shangai, China. PDF
- M. Tahon, A. Delaborde and L. Devillers (2012). Corpus of children voices for mi-level social markers and affect burst analysis. In proc. of LREC, Istanbul, Turkey. PDF (NAO-HR2)
- M. Tahon, A. Delaborde and L. Devillers (2011). Real-life emotion detection from speech in Human-Robot interaction : experiments across diverse corpora with child and adult voices. Interspeech, Firenze, Italy. doi (IDV-HR)
- M. Brendel, R. Zaccarelli, B. Shculler and L. Devillers (2010). Towards Measuring Similarity Between Emotional Corpora. In Workshop Emotion, LREC, Malta. (JEMO) PDF
- M. Tahon, A. Delaborde, C. Barras and L. Devillers (2010). A corpus for identification of speakers and their emotions. In Workshop Emotion, LREC, Malta. PDF (IDV-HH)
- A. Delaborde, M. Tahon, C. Barras and L. Devillers (2010). Corpus NAO-children: affective links in a Child-Robot interaction. In Workshop Emotion, LREC, Malta. (NAO-HR)
See an extract here

- Acoustic radiation of sorpranino recorder
I had the chance to realized acoustic imaging experiments at the LMSSC laboratory. The work focuses on measurement and analysis of a wind instrument using the acoustic holography technique in an anechoic room. A cylindrical acoustic antenna was used to capture the radiated sound during attacks' transitory. Experimental results aim at localizating radiating positions but also the temporal behaviour of this radiation during attacks.
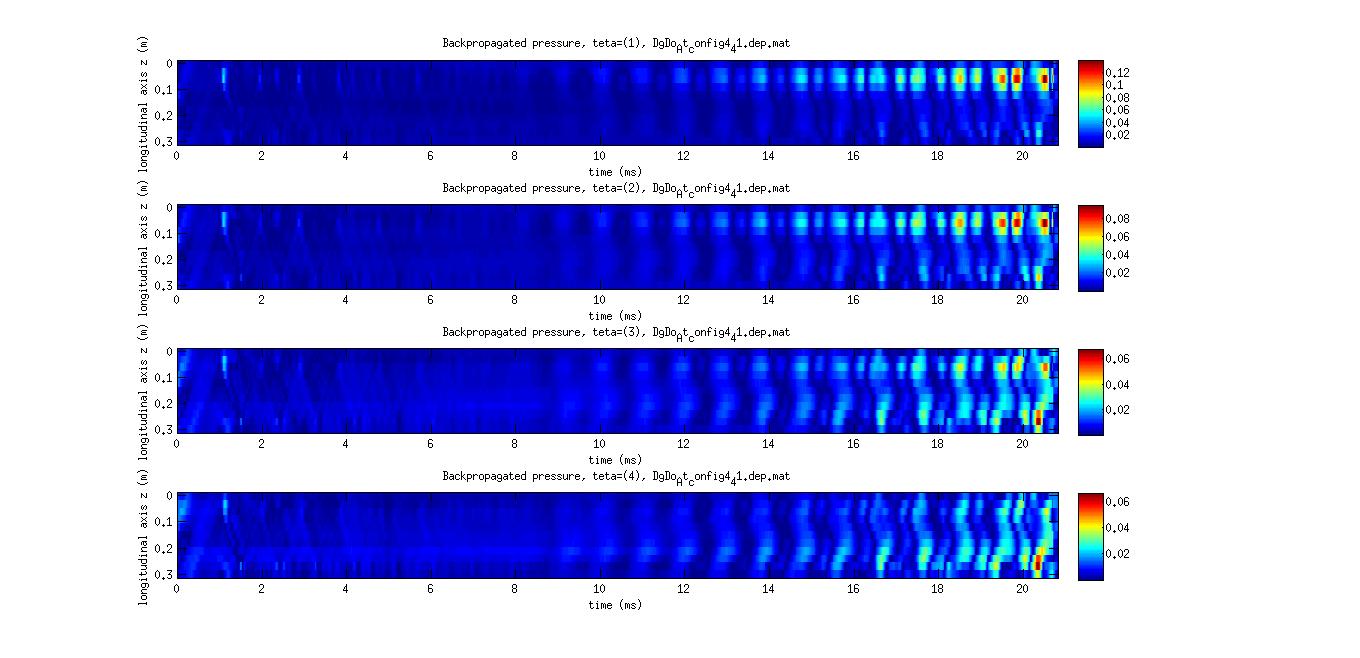

- Marie Tahon, Eric Bavu, Manuel Melon, Alexandre Garcia, Attack transient exploration on sopranino recorder with Near-Field Acoustic Holography method, ISMA, Le Mans, 2014. doi
- Artificial Mouth for wind instruments (Master thesis)
I have worked on the Ircam's artifical mouth. The study aimed at studying the vibrations of the artifical lips (silicone cylinders filled with water) when a trumpet was playing a single note. Vibrations and sound descriptors were studied with various experimental positions in order to build an automated system.
- Bell's sound damping (Internship)
This study aimed at damping a bell's sound in order to facilitate carillon's performances for keyboard players. Different materials at different position on the bell were tested for a better damping. Experimental and theoretical background on vibrating structures acoustic radiation were needed in the course of this internship.