Deux approches sont alors possibles pour répartir le travail entre processeurs travaillant simultanément. La première possibilité consiste à partager la grille à trois dimensions entre les processeurs, dont chacun propagera toutes les fonctions d'onde dans la zone d'espace restreinte qui lui sera confiée. Inversement, on peut charger chaque processeur de propager une seule fonction d'onde sur toute la grille ; un mélange des deux approches est évidemment également possible.
Lorsque, au début de cette thèse, nous avons défini la stratégie de parallélisation, nous n'envisagions pour la propagation des fonctions d'onde qu'une méthode du type Crank-Nicholson, que nous avons présentée plus haut. L'usage qui y est fait d'opérateurs aux dérivées partielles pour le terme d'énergie cinétique rend la solution de partager la grille entre les processeurs assez lourde à mettre en pratique, à cause de l'échange de valeurs aux frontières des zones confiées à chaque processeur qui est nécessaire. Nous avons donc opté pour la seconde possibilité.
Cette dernière est en effet extrêmement facilitée par le fait que les équations TDKS dans l'approximation adiabatique II.3 font intervenir le même Hamiltonien monoélectronique pour toutes les fonctions d'onde de spin identique:
![$\displaystyle i\hbar\frac{\partial}{\partial t}\psi_i(t) = \widehat{h}[n(t)] \;\psi _i (t)$](img204.gif)
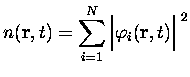
par conséquent, une fois connue la densité ![]() par réduction à
travers les processeurs, le Hamiltonien
par réduction à
travers les processeurs, le Hamiltonien
![]() qui est une fonctionnelle de
cette densité uniquement peut être calculé localement, et son action sur
les fonctions d'onde appliquée en parallèle.
qui est une fonctionnelle de
cette densité uniquement peut être calculé localement, et son action sur
les fonctions d'onde appliquée en parallèle.
Cette approche, vu sa simplicité, a pu être très rapidement implantée sur CRAY T3D à l'aide des extensions CRAFT au Fortran. Les performances ont montré, comme on pouvait s'y attendre étant donné le faible volume de communications nécessaires(une simple réduction-distribution par pas de temps) par rapport à la quantité de calculs, que l'accélération était à peu près exactement un facteur égal au nombre de processeurs.
Un problème d'ordre pratique s'est cependant posé : la condition initiale des itérations dynamiques devait être lue à partir de résultats calculés sur stations de travail à distance, ce qui a vite généré des transferts extrêmement pénibles vu l'incompatibilité des formats de stockage de données. Bien que notre but ne soit pas là, nous avons cependant parallélisé le calcul de la condition initiale.